-
-
Capstone symposium poster
-
Side-view slice
-
Top-view slice
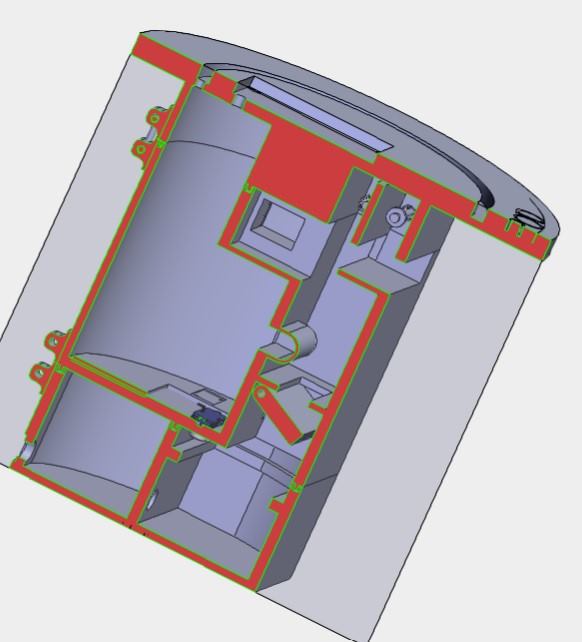
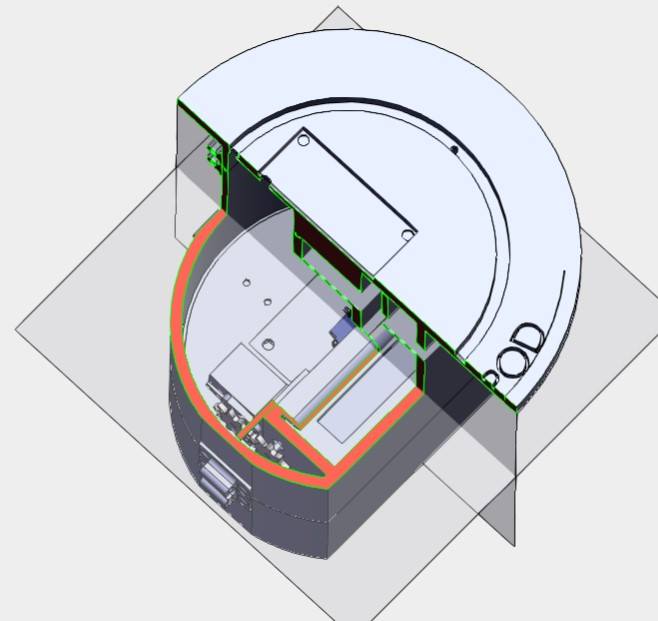
Overview
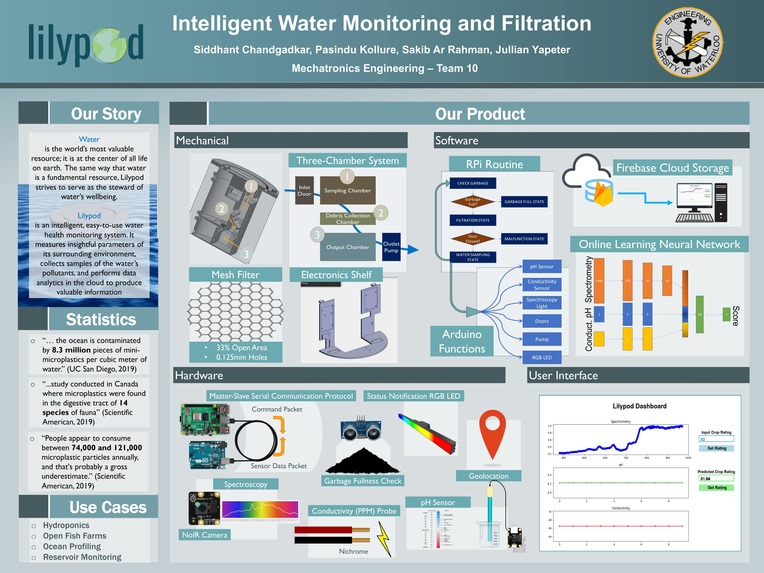
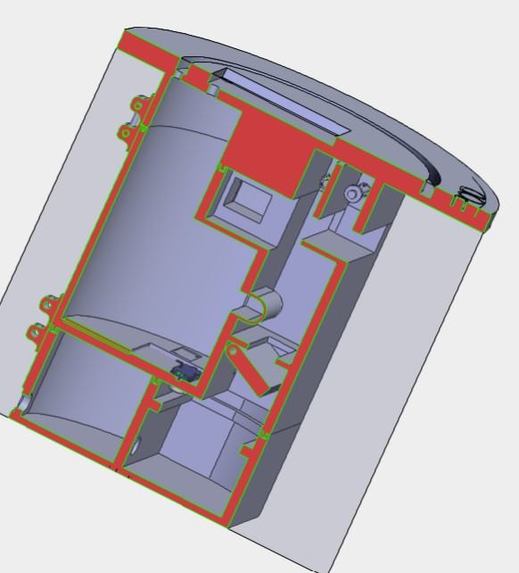
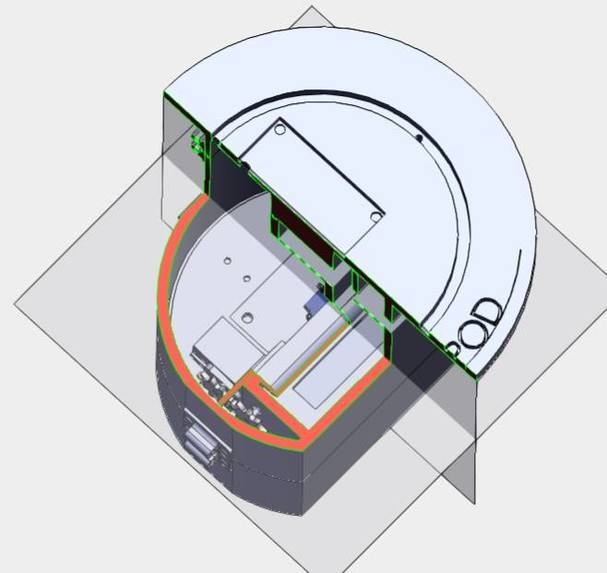
The Lilypod design is comprised of three main categories: hardware, software, and mechanical. The hardware aspect of the project is essentially an embedded system that includes a master-slave microcontroller scheme, an array of sensors, and actuators. A Raspberry Pi 4b plays the role of the master, executing the decision-making functionalities of Lilypod, while an Arduino Uno takes the role of the slave, interfacing with most of Lilypod’s transducers. One of the project’s main functionalities is to track important parameters of the water that would serve as insightful information for hydroponics farmers and environmental agency workers to make informed decisions that would be beneficial to the health of the ecosystems for which they are responsible. As such, Lilypod was equipped to gather a few pieces of crucial data, balancing cost-efficiency and utility. The data points that are able to be collected include pH level, conductivity (which is a proportional measure of nutrient concentrations in the water), and spectroscopy data. The collected data can then be stored on a cloud database, displayed on a simple dashboard for hydroponics farmers and other Lilypod operators to view, and also be used as training data for a machine learning algorithm that correlates water parameter values to a farmer-inputted crop quality value. A hollow cylindrical frame is designed to house all the electronics securely, separate chambers that will take in water from those that do not, and facilitate the movement of water through the module to be sampled and filtered as dictated by the onboard computers.
Software
Functional Routine:
With the hardware in place, software must be written to coordinate the project’s many functions. Lilypod’s behaves like a state machine; executing a set of functions that are assigned to one of five different states at any given point in time. A python module was implemented to dictate the routine of Lilypod; the method with which it decides which state to transition towards after having finished performing the functions of its current state.
The Check Garbage state directs Lilypod to halt the intake of water by closing both the inlet and outlet doors and utilize an HC-SR04 ultrasonic sensor that is installed above the mesh filter to determine if the debris collection chamber is filled. In this state, the notification LED ring atop the module shines blue. If the ultrasonic sensor detects a low enough distance value from it to the top of the heap of debris (lower than a pre-set threshold), the slave microcontroller will inform the master of the need for operator intervention and maintenance, thus terminating all operations indefinitely until the debris collection chamber has been manually cleaned and the system manually reset. The robustness of the measurement is ensured by taking the median of many measurements during a ten-second window, thus rejecting noise. The LED notification ring will turn red to signify that the module has entered the Garbage Full state and that it requires manual maintenance.
After ten seconds of executing the Check Garbage state, if the level of debris within the chamber is below the set threshold, the module would transition into the Filtration state. At this point, for one minute, Lilypod will have both the inlet and outlet doors open as well as the pump on, allowing for water to travel through the module and filter out debris. Additionally, the LED ring will turn green. A confirmation of the door being open is obtained by the closing of a limit switch. If the limit switch is not hit by the end of the Filtration state window, the module would go into its Malfunction state, signifying the occurrence of a mechanical or electrical error. This state, like the Garbage Full state, is terminal and also requires manual help from human operators.
Should the door work as expected by the end of the Filtration state, Lilypod will enter the Water Sampling state, where the LED ring will turn orange. This state lasts 30 seconds. In it, the outlet door is closed in order to keep the water pooled within the sampling chamber, where spectral, pH, and conductivity measurements of the water can be taken. An incandescent lightbulb is programmatically turned on during this time to illuminate the water sample. A picture is taken using a Raspberry Pi NoIR camera (which captures light in the IR range in addition to the visible range) through a diffraction lens. The image is then processed using classical computer vision algorithms to build a histogram of the intensities of different spectral ranges of light, profiling the transmissivity of the water which directly correlates to its mineral/nutrient composition. At the same time, the pH sensor and conductivity sensor also perform their tasks. The Raspberry Pi subsequently packages all the collected data, appends a signature time stamp, and updates a cloud database with the latest information. Lilypod then transitions back into the Check Garbage state to complete the routine loop.
Multithreaded Communication Framework:
A communication framework was written to orchestrate the passing of information between the master and slave in an efficient and reliable manner. This two-way communication protocol was designed to allow the master to send commands to the slave and for the slave to send sensor measurements back to the master through the serial bus. The medium for this communication is the synchronous passing of data packets of ten floating point values.
The above diagram illustrates the data pipeline for this project. The master, in this case the Raspberry Pi, runs three processes in three parallel threads: a main process, a send process, and a receive process. The main process is responsible for keeping track of (and deciding the transitions between) routine states, creating command data packets to send to the slave (the Arduino), and performing spectroscopy (since the Raspberry Pi is better fit to drive the NoIR camera and to handle the computational cost of image processing algorithms than the Arduino). Depending on which routine state Lilypod is to execute, the main process puts together a command data packet that reflects the functions that are to be run during that specific state. When the command data packet is ready, the main process puts it onto a command queue. The send process which runs in parallel thread is able to tightly poll the command queue for newly created command packets. When it receives one, the send process appends a start and end byte and writes the command packet onto the serial bus. The slave, which polls the serial bus, checks any newly received packet for the proper start and end bytes and proceeds to execute all the required functions. After all intended functions are executed, the slave puts together a sensor data packet and writes it to the serial bus. Back in the master controller, a receive process polls the serial bus for a new sensor data packet. Upon receiving one, the receive process checks the validity of, and strips off, the start and end bytes and puts it on a sensor data queue. When the main process has finished all its other responsibilities and is ready for the next sensor data packet, it dequeues the latest entry from the sensor data queue. After updating the database (and, by extension, the user’s dashboard) with the new sensor readings, the main process uses the information in the sensor data packet to decide which state Lilypod should be transitioning towards. The construction of the new command packet is both the ending of the previous communication loop and the beginning of the next one.
Master-side Command Data Packet Protocol:
To ensure robustness, start and end bytes (0xFA and 0xFB, respectively) are appended to the beginning and end of all data packets. Should the receiving end find an incorrect start or end byte, it would clearly signify a corrupted data packet and it would hence be ignored. Each element in the command data packet represents the master’s intent for each of the slave-driven transducer’s next action. Below is a figure outlining the command data packet’s denotation. Pump State, Bulb State (Incandescent lightbulb for spectroscopy), Garage State (inlet door), Trap State (outlet door), pH State, Cond State (Conductivity sensor), and USS State (ultrasonic sensor), which will carry a value of either 1.0 or 0.0, tells the Arduino whether that specific transducer should be turned on or off for the next state. LED State (notification LED ring) will carry either 0.0, 1.0, 2.0, or 3.0 representing the command to shine the color blue, green, orange, and red, respectively. Garage Direction and Trap Direction, which will also carry either a value of 1.0 or 0.0, represents whether the door should be opened or closed by the slave microcontroller for the next state.
Slave-side Sensor Data Packet Protocol:
On the slave side, after receiving a command packet from the master and executing all the intended functions, the Arduino Uno will package sensor information to relay back to the master. The three pieces of sensor information it is responsible for include pH Value, Cond Value (Conductivity reading measured in Siemens), and USS Value (ultrasonic sensor reading). The pH and conductivity values will be returned as floats, while the ultrasonic distance reading will simply be a boolean 1.0 or 0.0 depending on whether the slave has deemed the debris collection chamber to be full or not. Two additional pieces of data, Garage State and Trap State represent the limit switch readings of the inlet and outlet doors, if the doors do not behave as intended, the Garage State and Trap State will differ from what the master expects to be returned, thus prompting a transition into the Malfunction State as previously described. This data packet also employs a start and end byte system to allow for the rejection of faulty packets. For the data packet, the start byte is 0xFE and the end byte is 0xFF, differentiating it from a command packet and hence further inhibits miscommunication from occurring between the master and slave.
Cloud Database and User Interface:
To improve the mobility and ease of deployment, Lilypod is cloud-connected instead of being wired to a server. Firestore won out against other options such as Microsoft Azure and Amazon RDS for its non-relational structure, ease of development, and scalability. The non-relational schema allows information of different datatypes and of different sizes to be stored easily. This is beneficial since the sensor data points of different types: pH level and conductivity are floating point values, garbage level is represented as a boolean, the recorded name of the Lilypod module (to help a farmer differentiate between multiple Lilypod modules) is a string, geolocation is stored an array of floats (latitude and longitude values), and spectroscopy data is recorded as a map of strings (spectral range) to floats (intensity of light at that spectral range). This snapshot of data from a single point in time has a primary index of a time stamp; the number of seconds that has elapsed since the beginning of the epoch, guaranteeing that no two data documents’ indices will conflict with each other. A python application programming interface for Firestore allows data to be packaged as a python dictionary within the main process and be written to the cloud database with ease. Database updates happen once every 1 minute and 40 seconds, occurring after the completion of every Water Sampling State. The following figure shows how a single data document is structured:
In addition to the database, a user dashboard was created to assist Lilypod users to examine trends in the water parameter values. In the dashboard, the collected sensor data is shown in line chart format, which proved to be an easier viewing experience than the above database key-value fields. Below is a picture of the user dashboard.
Since the timestamp-based indexing system of the database inherently sorts the database in chronological order, it makes it convenient for the user dashboard application to poll for the most recently created data document and update the charts in real-time frequency. The spectrometry chart has the spectral ranges on the x-axis and the respective intensities on the y-axis. For the pH and conductivity charts, where each reading is a single floating point value, the x-axis is time represented as the number of measurements in the past, and the y-axis is the value of the parameter in terms of pH level and siemens respectively.
In addition to simply being a data viewing dashboard, this application serves as a simple interface for Lilypod users to interact with a machine learning interface running on an external server. At any frequency of choice, hydroponics farmers are able to inspect the quality of their crops, input a percentage score into the blue box and hit the Set Rating button. At which point, the machine learning model will perform online learning; updating its weights based on the new data point, with the water parameter values as the features and the farmer-inputted quality percentage score as the label. By hitting the green button, Get Rating, the hydroponic farmer can obtain a predicted quality score based on the most recent water measurements, thus serving as a supplementary auditor capable of notifying the farmer of a need to treat the water and prompting early action.
Machine Learning:
Due to the lack of training data correlating pH, spectral transmissivity, and conductivity of water to quality of hydroponic crops, the currently implemented machine learning model relies on online learning; gradually learning the function that relates the measured features to the desired quality score output given farmer-labelled data. This means that over time, with the increase in the number of times the machine learning feature gets used, the accuracy of the model at predicting crop quality will improve.
The designed model is a three-branch multi-layer perceptron. Each branch corresponds to one of the three types of data that Lilypod collects. After the concatenation of the three branches, the network outputs a logit between 0 and 1 as a prediction of quality, where 0 means low quality and 1 means high quality. One training step (composed of N epochs) will run whenever the user inputs a new label through the dashboard interface. An inference step will occur whenever the user requests for a prediction. The following is an illustration of the final model:
Spectral data enters as a 1000-element vector, corresponding to intensities over 1000 bins of spectral ranges. pH and conductivity values are simply scalars. Each branch passes through a few fully connected layers. In the case of the spectral data, the fully connected layers go through a dimensionality reduction into a 10-element vector, a sort of encoding, in order to prepare it for concatenation. The pH and conductivity data also go through fully connected layers in order to increase its dimensionality into 5-element vectors, such that its prominence does not get eclipsed by the spectral data. The increased number of layers also allow for more complex relationships to be approximated without the need for exceedingly wide hidden layers. The three branches are brought together with a concatenation step. The resulting vector with the amalgamated information from all three water parameter measurements are is put through a couple more fully connected layers that ultimately output a score. The final two fully-connected layers are responsible for learning the interplay between the three water parameters and how they ultimately correlate to crop quality, by estimating appropriate weights with which the elements in the concatenated vector are combined. Additionally, the last two fully-connected layers perform both dimensionality reduction in order to achieve the desired scalar output. The ReLU activation function is used at the end of each fully-connected layer to introduce non-linearity to the model and endow the model with the capability to fit non-linear functions.
A step of online learning occurs when the user inputs, through the dashboard interface, an observed crop quality score. The cloud database gets updated with this new score. Meanwhile, the machine learning model that is simultaneously running in an external server polls for changes in the database. When a new score gets posted onto the database (duplicate scores are mitigated by examining timestamps), the machine learning model takes the latest data frame of water measurements as training features and the inputted percentage score (scaled to a decimal between 0 and 1) as the training label. An epoch of forward and backward propagation is executed using mean squared error as the loss function and the Adam optimizer as the solver. The Adam optimizer maintains a per-parameter learning rate that adapts based on the average of both the first and second moments of the gradients, which makes it robust to non-stationary problems; suitable for noisy online learning, as it the case for Lilypod.
A step of inference occurs when the user requests for a predicted rating through the dashboard interface. The click of the Get Rating button gets registered in the database. When the online learning model detects the request, it runs one iteration of forward propagation to obtain a crop quality score. This score gets multiplied by 100 to convert it to a percentage, and then gets posted onto the database for the dashboard application to poll. The score is then displayed in the green box labelled Predicted Crop Rating for the user’s viewing. The score is clipped to a value between, and including, 0 and 100 in the case where the neural network predicts a value that falls outside of this range.
To validate the designed network’s ability to learn from given data and fit a function, one dummy datapoint was created by running sensor measurements in a tub of salted water. An arbitrary percentage score label was then assigned to the measurement to indicate the hypothetical quality of the crops. Then, the network was trained on the single datapoint for a large number of epochs. It was found that the network was able to overfit to this single datapoint and output the expected score given the dummy datapoint during inference time. This ensures that the network has the capacity to fit the relationship of water parameter data and crop quality if given sufficient data, through many uses of the feature.

Log in or sign up for Devpost to join the conversation.