







Inspiration
The rapid spread of COVID-19 has critically overwhelmed healthcare institutions around the world, an issue clearly evident in the United States. Amidst the COVID-19 crisis, healthcare institutions and government leaders are confronted with unthinkable challenges, including supply shortages that threaten both patient care and the safety of healthcare workers. The ceaseless patient volume and high patient acuity have exceeded the bed and staffing capacity of many hospitals. In these difficult times, the need for effective interhospital collaboration is increasingly clear.
There exist initiatives connecting hospitals with suppliers and initiatives documenting equipment stockpiles, but as Dr. Daniel M. Horn, a physician at Massachusetts General Hospital in Boston urged in his The New York Times op-ed, “Big tech needs to rapidly build and scale a cloud-based national ventilator surveillance platform which will track individual hospital I.C.U. capacity and ventilator supply across the nation in real time. Such a platform — which Silicon Valley could build and FEMA could utilize — would allow hospitals nationwide to report their I.C.U. bed status and their ventilator supply daily, in an unprecedented data-sharing initiative.” LiliusMed plans to actualize this platform.
Mission Statement
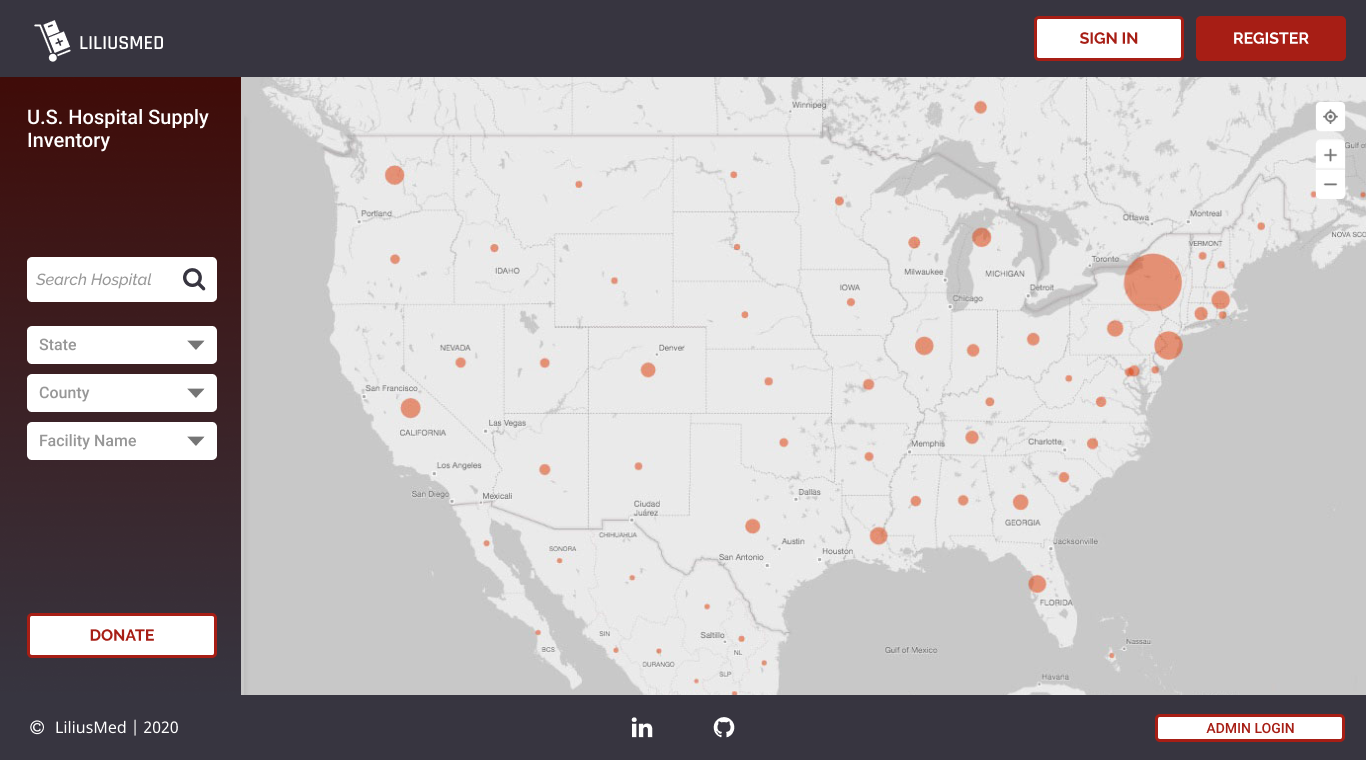
LiliusMed will create a near real-time dashboard visualization showing hospital supply needs in order to fast-track the distribution of vital hospital supplies and equipment. Our mission is to create a network infrastructure that allows healthcare systems to efficiently share data and effectively collaborate.
What Is The Platform?
The LiliusMed platform can be broken into 3 parts:
- A dashboard that allows hospitals to report their current data, such as:
- Ventilators
- Surgical masks
- Respirators
- Gloves
- Gowns
- COVID-19 tests
- COVID-19 inpatients (both confirmed positive cases and persons under investigation)
- Acute care bed capacity
- ICU bed capacity
- Available staffing
A machine learning algorithm to determine potential COVID-19 cases based on socio-demographic and geographic data points.
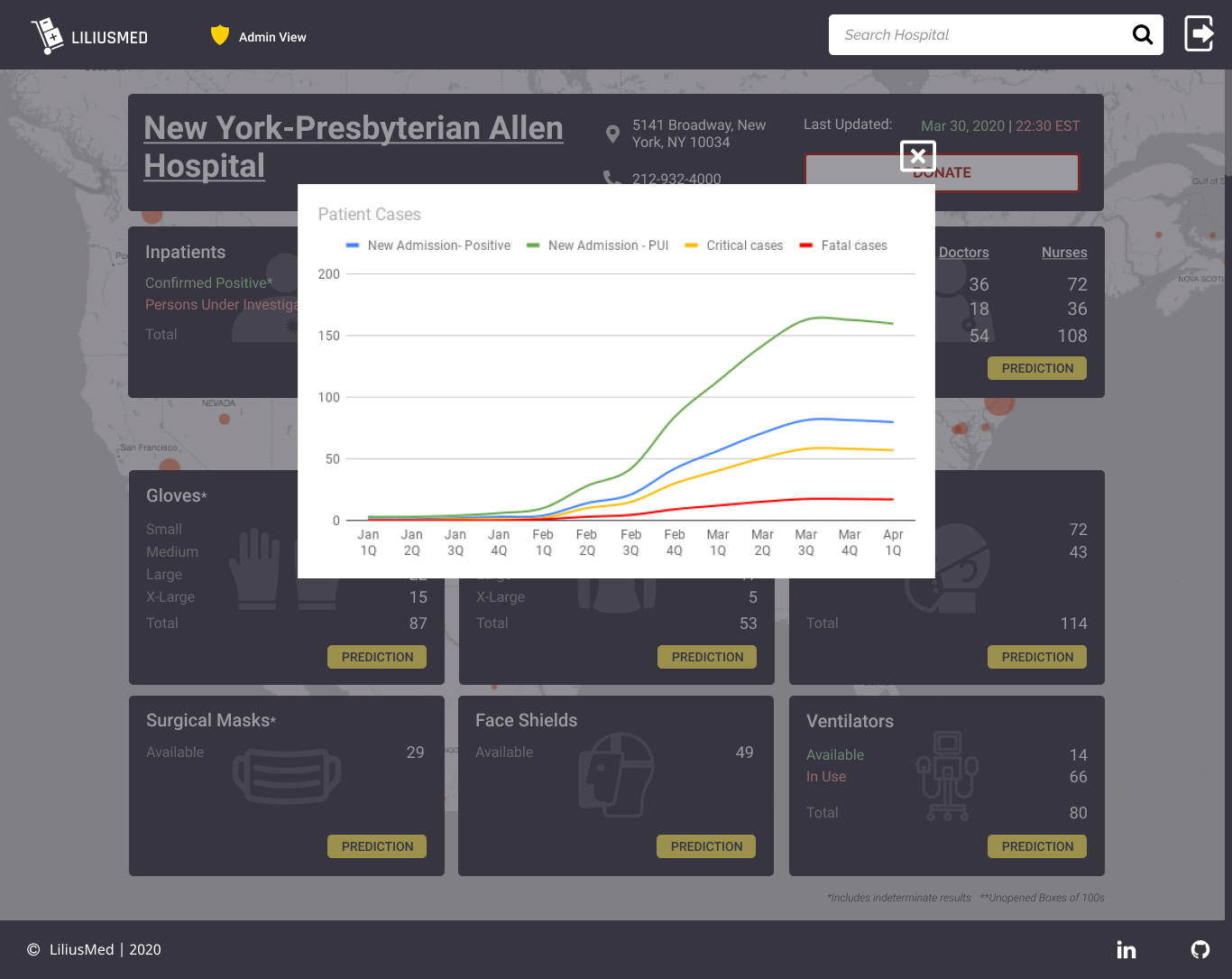
A series of dashboard displays that combine our machine learning model with data reported by hospitals. These dashboards, described in detail below, provide information that helps triage the supply chain crisis. This information will help local and federal organizations direct supplies and personnel, as well as triage COVID-19 patients.
Goals
- A database and network of hospitals
- Hospital data including supply count, bed capacity, and staffing
- Calculation of the personal protective equipment (PPE) burn rate (usage rate) of a hospital or region.
- A machine learning model to predict a county’s new COVID-19 patient counts for the coming days. Hospitals can potentially use this tool to influence the triage of new patients based on bed availability and staffing capacity throughout the county.
- As more data is added, we can make correlations between total patients, new patients, and burn rates to predict the need for supplies for a hospital or area.
- An early warning system to inform hospitals about the amount of supplies they will require for the coming days.
- Front-end functionality for a hospital to request supplies or donate their extra supplies to a hospital that currently needs them.
- Supplier functionality to report their supply count and have their supplies be directed to the proper hospitals.
Use Cases
Suppliers & Manufacturers
Suppliers and manufacturers can utilize the comprehensive platform to better understand and anticipate production needs based on our burn rate (usage rate) calculator powered by the CDC. By cross-examining predicted new cases, projected supply needs, and burn rate of hospitals, suppliers and manufacturers can accurately scale their production to directly and efficiently address the needs.
- Helps suppliers and manufactures accurately scale production based on need
- Saves time and streamlines the workflow for suppliers and manufactures by compiling all hospital needs in one coherent dashboard
Government Agencies
Government agencies can harness the power of our machine learning algorithm, coupled with the intuitive database of hospital supplies, personnel, and patients, to better understand where to direct resources. These tools substantially improve the complex decision-making process of supply distribution in order to maximize the number of lives saved. Our simple dashboard will allow agencies to pinpoint areas where COVID-19 cases are expected to increase and better prepare the impacted hospitals.
- Helps agencies remove barriers to efficient supply chain management.
- Provides agencies an early warning system using a predictive model to pinpoint potential COVID-19 hotspots.
- Pinpoints hospital needs based on predicted increase in patients to help optimize PPE, personnel, and bed capacity.
Hospitals
Utilizing our simple dashboard, hospitals will be able to self-report supplies, personnel, and patients. The search feature enables hospitals to make informed decisions about triage, patient flow, and potential transfers to nearby hospitals. Our supply burn rate (usage rate) calculator, powered by the CDC, will allow healthcare systems to visualize their supply usage.
- Search nearby hospitals to guide decisions about patient flow
- CDC-powered burn rate calculator to track PPE usage
COVID-19 Case Prediction Model Using
Socio-Demographic and COVID-19
Statistical Data
Case Study Applied to New York Counties
1 Introduction
The rapid spread of COVID-19 has critically overwhelmed healthcare systems around the world, an issue clearly evident in the United States. The immense surge in COVID-19 cases has rendered many hospitals ill-suited to care for the high patient acuity and volume of incoming patients due to widespread shortages of personal protective equipment (PPE) such as face masks, ventilators, as well as insufficient staff and bed capacity. These shortages have the potential to compromise both patient care and the safety of healthcare workers. The core issue is a mismatch of supply and demand problem, where hospitals’ available supplies and capacity are inadequate to meet their needs. To overcome these challenges, public and private sectors’ companies are coming together to forge new supply chains to fill the demand for various medical supplies. To be capable of the behemoth undertaking of improving healthcare delivery across the nation these supply chains must address difficult questions both efficiently and accurately: Which hospitals should receive aid? Where are the greatest patient caseloads? Where are the greatest supply shortages? What specific aid is required, and how much? To tackle these questions, manufacturers, distributors, and government officials must have the ability to reliably understand each hospital’s current needs, as well as anticipate their future needs. A predominant driver of hospitals’ supply needs is the number of current and anticipated COVID- cases. We propose to use machine learning (ML) as a forecasting technique to predict the expected number of new COVID-19 cases both within a community and within a hospital system.
2 Methodology
The main modes of transmission for SARS-CoV-2, the novel human coronavirus responsible for COVID-19, appears to be through respiratory droplets via person-to-person spread, as well as contact with contaminated surfaces. To combat the rate of spread of COVID-19, public health officials have recommended social distancing to limit exposure to and transmission of the virus, which has been instituted in various degrees across the nation such as through shelter-in-place and stay-at-home orders. The extent of adherence to these social distancing measures influences the rate of exposure and the spread of COVID-19. We base our methodology on the premise that the spread of COVID-19 within a community is highly correlated with the community’s socio-demographic data. To prove our hypothesis and to provide a tool that could forecast the expected number of new COVID-19 cases, we built a model using Decision Tree Regression that predicts the next day’s new cases based on socio-demographic data at the county level.
Given the time limitations and the current unavailability of some data, we limited our model to counties within the state of New York. In the future, we intend to expand the prediction model to nationwide data. Attributes The reported number of confirmed cases in each county is highly dependent on the number of tests performed. Hence, such reported numbers likely significantly underestimate the prevalence of actual positive cases. Given that the testing rate within a county is currently undisclosed, we combined a county’s social and demographic traits with statistical characteristics of the COVID-19 spread within the county. Table 1 below shows the attributes used in our model. Socio-demographic data is extracted from the latest available United States Census. COVID-19 data is scribed from the John Hopkins Novel Coronavirus COVID-19 (2019-nCoV) Data Repository Repository.
Table 1. County attributes used in our model
Attribute Description
Density: Population density
Education: Percentage of population 25 years and older having a high school degree or higher
Unemployment: Unemployment rate
Sex Ratio: Ratio of male to 100 female
Age Median: Median of population age
Public Transportation: Commute percentage of workers that use public transportation as a way to commute (excluding taxicab)
Infection Rate: Current COVID-19 infection rate (number of cases/population)
Infection Density: Current COVID-19 infection density (number of cases/area)
Average Increase: Average daily percentage increase of COVID-19 cases (calculated from the previous 5 days)
COVID1: Number of COVID-19 cases on day 1
COVID2: Number of COVID-19 cases on day 2
COVID3: Number of COVID-19 cases on day 3
COVID4: Number of COVID-19 cases on day 4
COVID5: Number of COVID-19 cases on day 5
Prediction: Case increase rate
2.1 Technique
The main limitation of our model is the limited number of cases, as we applied our model to 58 different counties within New York State only. To focus our model on attributes and their relative effects on the spread of COVID-19, we used Decision Tree as a regression method (Python Scikit-Learn implementation). Decision Trees (DTs) are a well known and widely used supervised classification and regression technique. DTs extract decision rules from training features that would be used to perform predictions on new data. These decision rules can be internally described as a set of if-else steps.
The main advantage of Decision Trees is the simplicity of the model and its white box nature ( i.e., precise decision rules can be extracted and visualized). DTs do not require a relatively large dataset to perform well, compared to other techniques such as Neural Networks and Support Vector Machine.
2.2 Experimentation and Results
To study the performance of DTs, we applied the model to New York State counties to predict the next day's expected percentage of increased cases. Knowing the increased percentage of cases, we are then able to calculate the expected number of new cases. We performed 10 Folds Cross-Validation by dividing our data set into 10 different chunks, then running the model 10 times. For each run, we designate one chunk to be for testing and the other 9 are used for training. This is done so that every data point will be in both testing and training. DTs resulted in an R-squared value of 0.4. Our dataset contains a lot of variance in the number of cases between counties. Given this result and the limited number of cases used, a 0.4 R square value shows the ML can be indeed used to predict future numbers of COVID-19 cases using socio-demographic data. Figure 1 below shows the performance of DTs on a sample test run.
Figure 1. Decision Trees performance on a sample test run
3 Discussion
In this study, we used Decision Trees to predict the next-day percentage increase of COVID-19 cases at a county level within New York. Results show that socio-demographic data influence the spread of COVID-19 given the promising performance of ML even with a very limited data set. Therefore, the correlation between community traits and COVID-19 cases appears to be valuable for predicting a hospital's expected supply needs, translating to both improved healthcare delivery to patients and the safety of healthcare workers.
4 Future Expansion
This attempt is primarily intended to show that it is possible to correlate socio-demographic traits with the spread of COVID-19. In addition, this demonstration serves as initial proof that machine learning can be used to predict the future numbers of new COVID-19 cases. We are limited in the conclusions drawn from the results of this model given the restricted data used and the geographical limitation (only within New York). Furthermore, the number of positive COVID-19 cases depends on the number of COVID-19 tests being performed. In addition, time-series forecasting could be implemented when time-series data becomes available.
To enhance this project further, additional effort is needed to:
- Gather data for all United States counties
- Extract testing rate per county
- Extract more daily COVID-19 number of cases
- Extract hospitalization rate of COVID-19 patients
With relative data extracted, multiple forecasting attempts can be done to predict:
- Hospitalization rate of COVID-19
- Death rate
- Long-term infection rate
- Length of stay of COVID-19 patients
- Ventilator needed per hospital
- PPE need per hospital
Supporting Resources
Trump Administration Engages America’s Hospitals in Unprecedented Data Sharing
US Surgeon General
US Surgeon General Dr. Jerome Adams said Friday on “CBS This Morning” that the Federal Emergency Management Agency has sent a team to New York City to help allocate resources. “You heard Governor Cuomo say, look, we actually have resources, they’re just mismatched,” Adams told CBS’ Gayle King. “So we sent a team, a FEMA team to help New York City to make sure the resources are getting to where they need.” Article
Youtube Video of Surgeon General
Via USDigitalResponse.org: Building/implementing a system to better collect and track data from hospitals about their bed and ventilator capacity
USDigitalResponse.org Stating The Problem
Dr. Daniel M Horn
Dr. Daniel M Horn Article NY Times
NY Government
Government organizations are still relying on inaccurate and “opinion biased” decision making trees to distribute much needed supplies
Article on the NY Government Website
Product Roadmap
The LiliusMed team has functionality of the platform. We are currently in the process of bringing our front-end up to speed with our U/X designer's wire frames. Below is our Product Roadmap post hackathon submission:
- New Security Features
- Admin Dashboard
-- Distribution Optimizer (Protect Patients) - ML model more accurate (Goal = 0.8)
- Expand the hospital dashboard -- PPE Optimizer (Protect Staff)
Team
- Ryan Fogarty- Front-end/ Back-end
- Sawyer Cutler- Back-end
- Firas Georges- Machine Learning
- Nathaniel Ng- Machine Learning
- Nicholas Nemetz- Front-end
- Diana Zhong, MD- Medical Expert/Design
- Chickee Fuerman- UX/UI Design
- Josh Trinidad- Front-end/Back-end
- Ronique Ricketts-Front-end UX/UI
- Galata Tona- Back-end
- Konstantin Kornev - Front-end
- Jason Lee- Product Manager
- Anthony Holley- Project Manager









Log in or sign up for Devpost to join the conversation.