Inspiration
We were inspired by the opportunity to optimize the capabilities of LLMs to more capably take on specific tasks that can accelerate academic learning and improve accessibility across the world. This project enabled us to work towards the education and accessibility pillars of this hackathon and we can see huge potential for the project as it expands in scale. The name LilDewey was inspired by John Dewey, one of the most influential educational reformers of the United Stated Educational System. Like him, LilDewey aims to make education more accessible and structured for all.
What it does
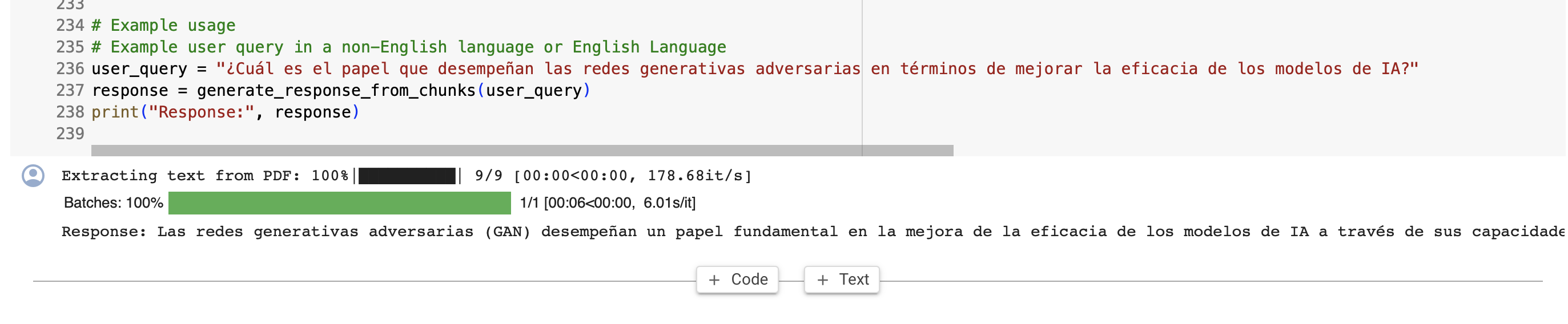
Anyone in secondary education knows the struggle of massive textbooks and compounding this issue is the difficulty experienced by students who may use english as a second language. DeweyBot is an embedded model that specializes in the capabilities offered by the OpenAI API and GPT-4 to be quickly trained on any given corpus of text and then answer specific user queries in coherent, concise and content-specific responses that cite page numbers and sections accordingly. Furthermore, in recognition of the difficulty many students who may speak english as a second language face, DeweyBot is able to leverage an internal translational model that can take in queries in over 183 languages, and then produce responses in that same detected language while still based on the original given english text. This could be invaluable for, say, a spanish-speaking student learning a biology textbook in English, but feels she could best formulate the question in her native tongue in order to understand a given concept.
How we built it
Lil’ Dewey is a comprehensive solution designed for processing PDF documents to extract text, segmenting the text into manageable chunks, embedding these chunks for semantic similarity searches, and optionally translating content for multilingual support. The solution leverages several Python libraries and integrates with the OpenAI API for generating responses based on the content of the PDF. Here's an overview of how each part of the code works and integrates into the broader solution:
PDF Download: Utilizes urllib.request.urlretrieve to download a PDF from a specified URL to a local file. This allows users to input PDFs via URLs for processing. Text Extraction from PDF: Employs fitz (PyMuPDF) to open PDF documents and extract text. This process is enhanced by a preprocessing function that cleans the text by removing newlines and excess spaces, improving the quality of text for further processing. Text Chunking: After cleaning, the text is split into smaller, manageable chunks. This is crucial for analyzing large documents, as it breaks down the text into segments that are easier to process and understand in context.
After the data pre-processing we began the semantic search processing and search chunk embedding: We used SentenceTransformer to convert text chunks into dense vector embeddings, enabling semantic search capabilities. These embeddings capture the contextual meaning of text chunks, facilitating the identification of relevant content based on query semantics. FAISS Indexing: Integrates with FAISS (Facebook AI Similarity Search) to create an efficient similarity search index from the embeddings (and utilizing the K-Nearest Neighbors (KNN) Algorithm). This index supports fast retrieval of text chunks that are semantically close to a given query. Semantic Search: We then implemented a search function that encodes a user query into an embedding and uses the FAISS index to find the most relevant text chunks. This function supports queries in different languages by detecting the query's language and translating it to English if necessary. This is the first dimension of the translational capability.
For this we leveraged ‘langdetect’ for language detection and a Translator for translating text. This supports multilingual queries by translating non-English queries into English before processing and then translating responses back into the original query language for maximal accessibility and comprehension for the user. This is the second dimension of the translational capability. The model accommodates detecting and translating for over 183 languages.
Next we built integration with OpenAI for Response Generation. OpenAI API Interaction: We incorporated OpenAI's API to generate responses based on the semantically relevant text chunks. It constructs a prompt that includes the relevant chunks and instructions for generating a coherent and contextually appropriate response. This allows leveraging advanced language models (like GPT) for synthesizing information from the PDF into a concise answer. It also includes page numbers, sections, and relevant information that directly cites the text to minimize hallucination or misattribution of information.
Challenges we ran into
We had a great deal of difficulty accommodating OpenAI’s API for this project based on its changed framework from previous uses which we were more familiar with. Additionally, the translational capability of the model had a restriction on the amount of tokens it could translate, meaning we had to break it down into manageable chunks and concatenate the translated answer together thereafter. After successfully implementing functionality within Google Colab, we attempted to provide a demo with a user interface on HuggingFace Spaces, using Gradio. Then, we would be able to embed this demo to a website. However, we were unable to migrate the code to Spaces even after debugging. We then planned to add the back-end code to Flask, and design our own UI, but we ran out of time.
Accomplishments that we're proud of
The translation feature is something that we are proud of. LilDewey can translate in 183 languages, providing global usage. This feature also allows the project to be a lot more accessible. It was also a bit of a challenge initially to think about the logic behind implementing the translation effect into our ML algorithm. We had some issues with the translation AI API we had to deal with and are proud of how we managed to work around it to get great results.
What we learned
We learned a lot about Embedded Large Language Models. We also learned about how to take text and properly encode it so we could perform a K-means clustering unsupervised machine learning algorithm on the data to replicate this. We also learned a lot about how to integrate the GTP-4 API into our algorithm to get human-like results. We also attempted to build a UI which taught us a lot about how integration works and how to build interfaces on websites such as Hugging Face which allow users to host machine learning applications on their site.
What's next for LilDewey
The next steps for LilDewey, apart from his aspiring rap career, is to improve the project’s usability. Currently, we have the translation feature to work on accessibility. However, for large textbooks with large amounts of data, the algorithm can take a while to run. Improving the algorithm's time efficiency would make it easier to use and more effective. We also want to develop the UI for a website, possibly making a website to allow users to use this ML and make it personal for a user such as recommending other textbooks to the user or storing the textbooks they upload.
Built With
- faiss
- fitz
- language-detection
- llm
- machine-learning
- numpy
- openai
- python
- translate
- translationai





Log in or sign up for Devpost to join the conversation.