Inspiration 🌅
We’ve all been there: you snap a bunch of photos to capture a moment, only to look back and feel like something’s missing. Maybe the lighting was off, the image is way too grainy, or there’s a distracting detail you wish you could erase. The photo just doesn’t feel like the moment you lived. That frustration is what inspired Lighthouse — a tool designed to reconstruct and creatively reimagine noisy or imperfect images using the power of diffusion.
What it does ⚙️
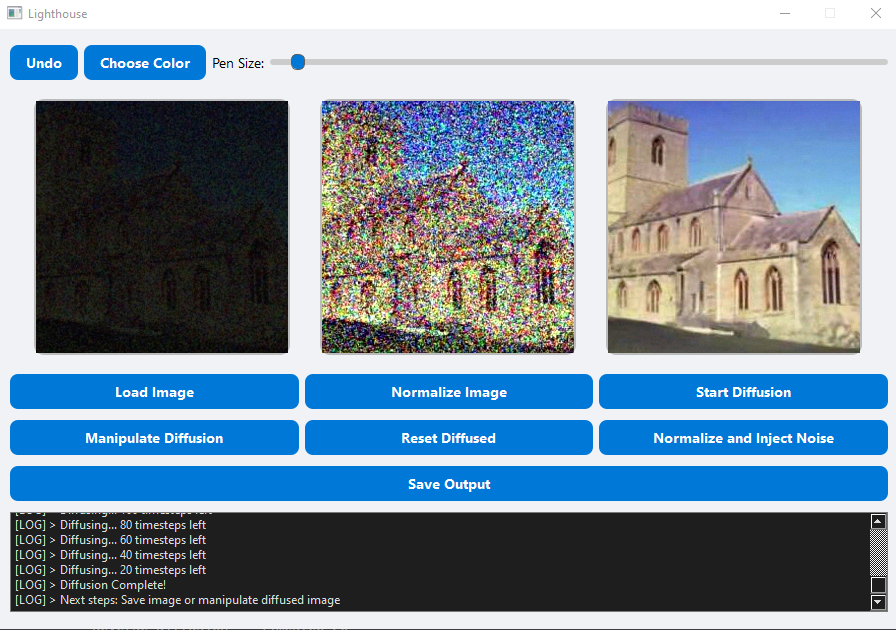
Lighthouse is powered by diffusion models — deep learning systems that can generate detailed, high-quality images from nothing but noise. Normally, these models start from pure randomness and gradually subtract noise in small steps, revealing an image as they go. I thought: what if we hijack this process? What if we insert a real image midway through the diffusion process and let the model rebuild it with enhanced detail or creative variation?
Lighthouse focuses on two main tasks:
Extreme Image Denoising: In low light or high ISO situations, your image can be so noisy it’s nearly unusable. Lighthouse uses a diffusion model’s inherent denoising ability to recover and recreate details that likely existed — even when traditional filters fail.
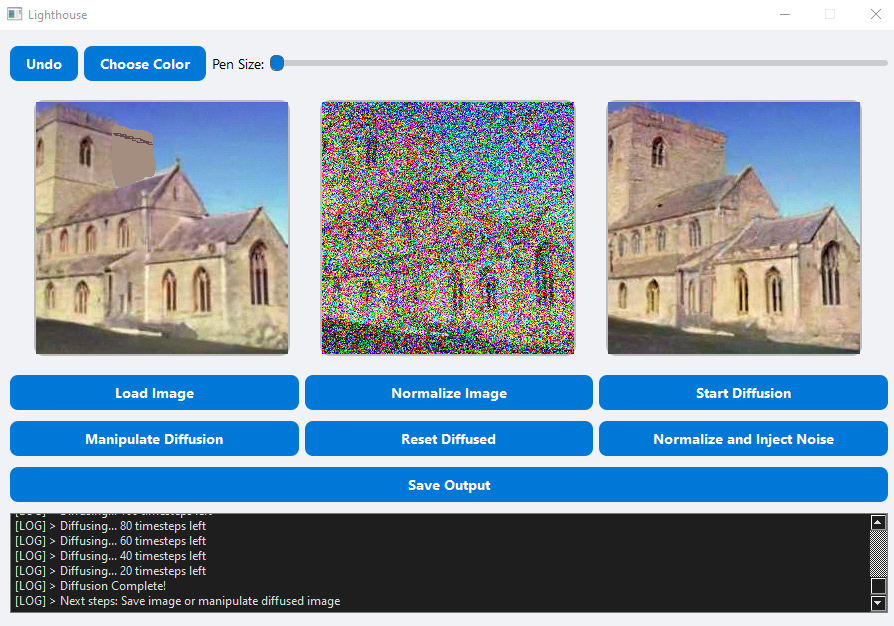
Creative Generation: By modifying and adding noise back into an image (a process I call renoising) and running it through the diffusion model again, Lighthouse can generate realistic and artistic variations based on small modifications — enabling expressive, intuitive editing.
Check out the demo to see both of these modes in action!
Lighthouse uses the same method large tech companies like OpenAI (DALLE) and Stability AI use to generate images. The difference? Lighthouse allows you to start the diffusion process with an image, and modify it in a creative manner; no such functionality from big tech companies. Also, they have a giant supercomputer of hundreds of NVIDIA H100s ($30k each), I have 1 NVIDIA 2070 ($400).
How I built it 🛠
Lighthouse is built using Google’s Denoising Diffusion Probabilistic Models (DDPM). This architecture lets me skip the initial timesteps and start the denoising process from a partially noisy, real image. To make renoising work, I also implemented a custom noise scheduler that simulates the same noise induction process used during training.
Challenges I ran into 🚧
Diffusion models are powerful — and incredibly compute-heavy. Even with a decent GPU (RTX 2070), running high-res models pushed the limits. After experimenting with several architectures, I landed on a model that struck the right balance between performance and output quality. Training a model from scratch would’ve taken more than a hundred years on my setup (literally) — so for now, pre-trained models are the move.
Accomplishments that I'm proud of ✅
The best part? Lighthouse works. It can bring detail back into unrecognizable images and enable amazing, creative edits in just a few steps. Lighthouse was a shot for the moon, adapting existing models and getting diffusion models to work with image manipulation could've not worked in the slightest, so I'm proud that it worked pretty well.
What we learned 📚
This project was my first time working hands-on with diffusion models, and it was a deep dive. I already had a theoretical understanding, but implementing denoising, scheduling, and custom workflows really pushed my understanding to the next level — especially when experimenting with novel use cases like renoising.
What's next for Lighthouse 🔮
I’m excited to take Lighthouse even further with:
- Stable Diffusion Integration: Operating in the latent space using VAEs, which could unlock faster and higher-resolution generation.
- LoRA Fine-Tuning: Adding lightweight adapter training to guide generation using semantic concepts, all without retraining the entire model.
Built With
- ddpm
- python
- torch





Log in or sign up for Devpost to join the conversation.