-
-
Our on-demand generative dashboard
LightHome
Inspiration
Online grooming rarely begins with explicit language. It begins with something ordinary: a compliment, a shared interest, a private joke. The danger is the shift from friendly rapport into isolation, secrecy, and boundary testing, and that shift usually contains no flagged words.
The scale makes this urgent. In 2023, NCMEC received more than 36 million CyberTipline reports, including 186,000 online enticement reports, up 300 percent from the prior year. Research shows a predator can move from first contact to high-risk grooming in about 45 minutes. Most systems wait for explicit content, the stage where the bad words finally appear. By then it is too late. LightHome was built around one idea: do not wait for the explicit message, catch the dangerous shape earlier. Our demo line is that we catch it at minute 12.
What it does
LightHome analyzes the structure of a conversation over time, not just its vocabulary. Every message runs through structural signals: directionality, reciprocity, boundary recycling, and escalation velocity. Instead of only asking whether someone said a banned word, it asks who is asking the personal questions, whether vulnerability flows both ways, whether one person is separating the child from parents and peers, and whether the same boundary push returns after hesitation.
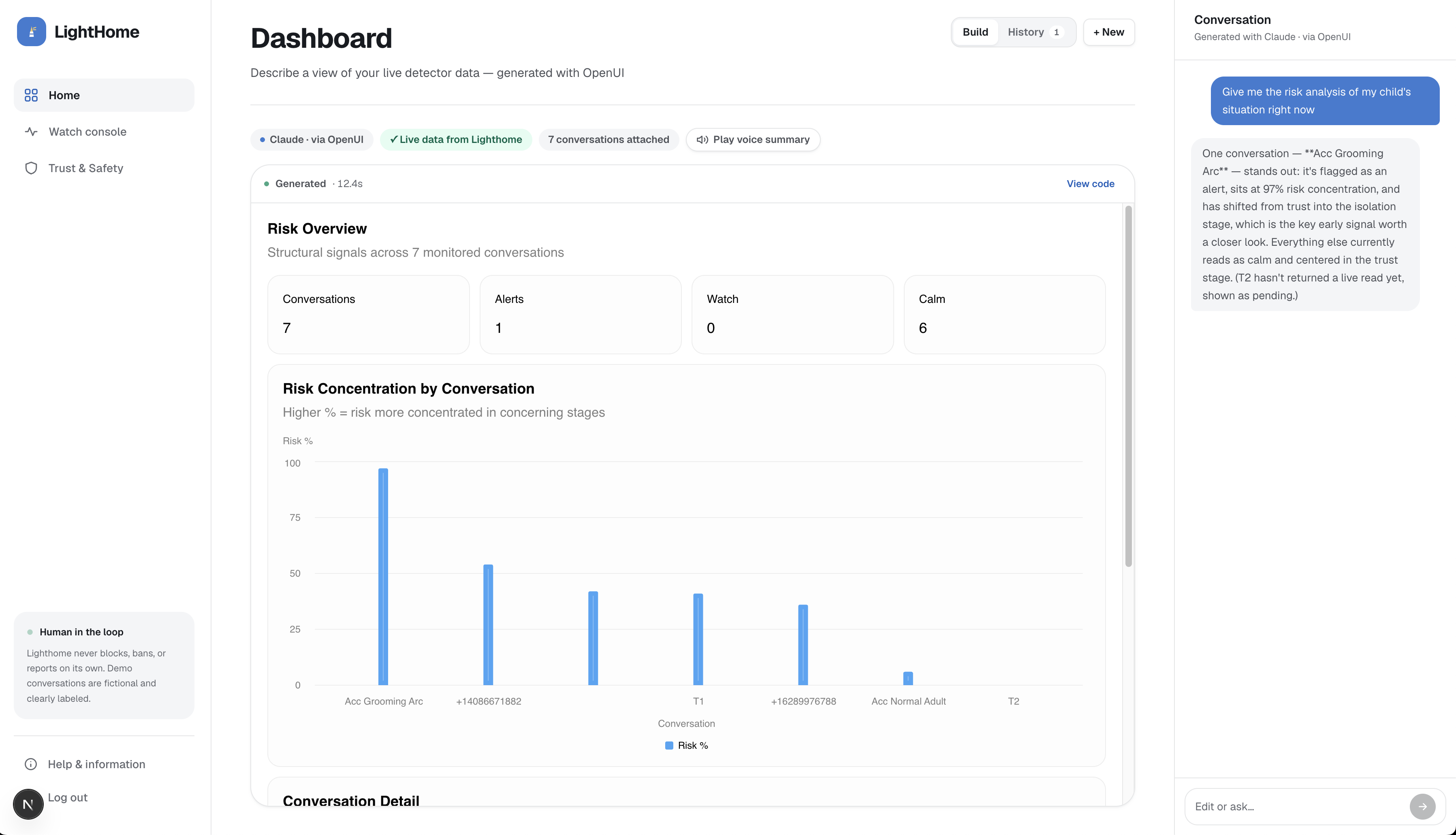
Those signals feed a Bayesian stage tracker that maintains live probabilities across four stages: trust-building, isolation, desensitization, and escalation. An alert fires only when four structural conditions hold at the same time, which is what keeps the negative cases quiet. A teen saying "don't tell my mom" does not trip the alert, and the trust-and-safety view shows exactly which condition held it green.
LightHome has two views. The parent dashboard shows risk progression and guidance without exposing raw private messages. The platform trust-and-safety view shows the transcript, the per-message feature breakdown, and the full decision trace for a human moderator.
How we built it
LightHome is an explainable pipeline with separate layers for feature extraction, stage tracking, AI synthesis, state, and observability. The four structural extractors run in local Python before Claude ever sees the message. Claude then synthesizes the message and those features into a stage-likelihood distribution, which feeds the Bayesian tracker that updates the conversation's stage probabilities over time.
Claude is one input, not the brain. Because the structural features are computed independently, they can overrule the model when it is wrong, and we log that feature-versus-Claude disagreement as a first-class, queryable signal in our trace. There is one internal decision record, and the API projects it into two views, so "the parent never sees raw messages" is enforced at the API boundary, not by frontend convention.
Stack: Python and FastAPI, custom NLP feature extractors (spaCy, VADER, sentence-transformers), a Bayesian stage tracker, and a Next.js and Tailwind dashboard with a live message stream, probability bar, stage timeline, and conditions table.
Sponsors we built with
- Claude (Anthropic) is our stage-likelihood synthesis layer. It takes the message plus the four locally-computed features and returns a probability distribution over the four grooming stages via structured output. It also condenses a dashboard answer into one or two spoken sentences for the voice summary. Crucially it is one input, not the brain, and the structural features can overrule it.
- Redis holds per-session conversation state so the Bayesian tracker keeps a running prior across the message stream. It sits behind a state-store protocol and swaps to an in-memory fallback with one line if Redis is down.
- Arize (Phoenix) is our decision observability and audit trail. Every Claude call is captured as a span with the features in and stage likelihoods out, and we log the feature-versus-Claude disagreement as a first-class, queryable attribute. A local JSONL fallback keeps traces available offline.
- Sentry monitors the detection system itself, tracking real alert-fire events and pipeline failures rather than a bare init.
- Deepgram powers voice. Its listen API transcribes the trust-and-safety composer mic (speech to text), and its Aura TTS voices the spoken dashboard summary (text to speech), so a moderator can ask and hear instead of only typing and reading.
Challenges we ran into
The hardest part was avoiding a keyword detector. Surface language is misleading: "don't tell my mom yet" can be risky in one context and ordinary in another. The system has to read structure, not panic at isolated phrases. That is why the negative demos mattered as much as the positive one. We built three fictional scenarios: a grooming arc that should trigger, a coach-student conversation that should not, and a teen relationship with casual secrecy language that should not. We also kept the demo restrained, since the point is that the risky pattern appears before any explicit content exists.
Accomplishments that we're proud of
LightHome is explainable by design. Every alert breaks down into raw features, stage likelihoods, Bayesian priors and posteriors, alert status, and alert reasons. We are proud of the false-positive case: a system that flagged every private teen conversation would be harmful and unusable, and LightHome shows why similar words do not mean similar risk. The parent view communicates risk progression without turning the product into a surveillance feed.
What we learned
Detecting obvious bad content is not the hard part. The hard part is detecting early structural movement while preserving context, uncertainty, and human judgment. Safety systems need to be humble: expose their reasoning, show uncertainty, and keep humans in the loop.
What's next for LightHome
Next, we want to evaluate LightHome against larger datasets and measure false positives and false negatives more rigorously. We would also improve the feature extractors, expand the trust-and-safety workflow, and test the system across more conversation styles.
Our long-term plan is to integrate LightHome into more platforms, especially platforms where many children and teenagers communicate online. This could include gaming communities, education platforms, social apps, messaging tools, and creator communities. The goal is not to replace existing moderation systems, but to add an early structural risk layer that can detect concerning progression before explicit content appears.
We also want to build better platform integrations so LightHome can work as an API layer for trust-and-safety teams. Platforms could send conversation events to LightHome, receive structured risk records, and review explainable alerts through a moderation dashboard.
LightHome was built and demoed entirely with fictional scenarios. A real deployment would require expert review, privacy review, child safety partnerships, and careful evaluation with organizations such as Thorn, NCMEC, and platform trust-and-safety teams.
LightHome is a prototype, not a replacement for professional child safety work. Its purpose is to show how AI can help detect harmful conversation patterns earlier, more explainably, and with humans still in control.
Safety and deployment note
Built and demoed entirely on fictional scenarios. It is a prototype, not a replacement for professional child safety work. Any real deployment would require expert review, privacy review, and rigorous evaluation with organizations. However, since this is a project for the betterment of society, we believe that using AI for this purpose should be the goal of AI in general.
Built With
- arize-phoenix
- fastapi
- next.js/react
- openui
- python
- railway
- redis
- sentence-transformers
- sentry
- spacy
- tailwind-css
- the-claude-api
- typescript
- vader
- vercel


Log in or sign up for Devpost to join the conversation.