-
-

Predictions by Luminos™
-
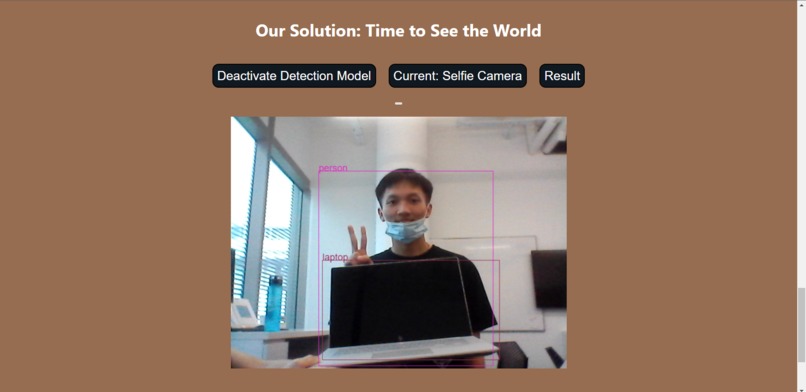
Real-Time Object Detection by Luminos™

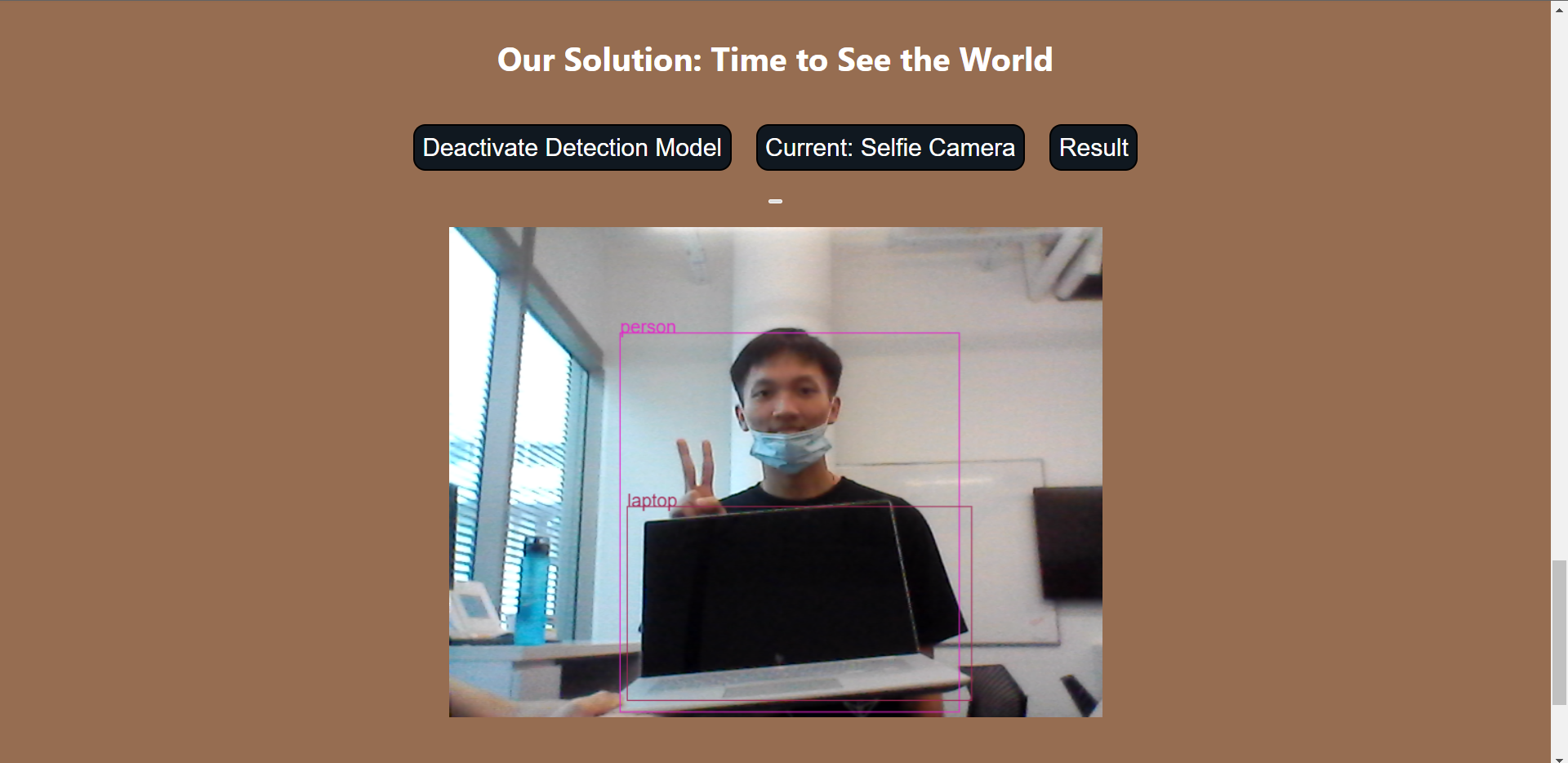
Inspiration
Meet Sam. His visual impairment makes it a pain to navigate his own surroundings without help. It gets even more difficult when he is all by himself, with no one to help him, exposing him to road hazards and physical injury. What if there was a device that could help Sam detect objects around him in real-time and tell him what he is looking at?
What does it do?
Luminos™ is a computer vision model based on COCO-SSD to detect objects in video feeds. The detected objects will be voiced out by an AI for interpretation by the visually impaired.
How we built it
We built a web application to demonstrate the functionality of the model. We used ReactJS to build the user interfaces. We used TensorflowJS API for the SSD model.
Challenges we ran into
We initially started to build our own object-detection model from scratch but we encountered many incompatibility issues. As a workaround, we used a pre-trained object-detection model from TensorflowJS API.
Accomplishments that we're proud of
We successfully built user interfaces with object-detection model deployed through the website. This allows general users, who can access the website, to use the model.
What we learned
We learned how to deploy pre-trained deep learning models through a website. We also learned a lot about how computer vision can help blind and low vision people navigate their daily lives more easily.
What's next for Luminos™: A Vision for the Blind?
We hope that Luminos™ can be implemented through a wearable device to help visually impaired people around the world.
Built With
- javascript
- react
- tensorflowjs




Log in or sign up for Devpost to join the conversation.