-
-
Home page
-
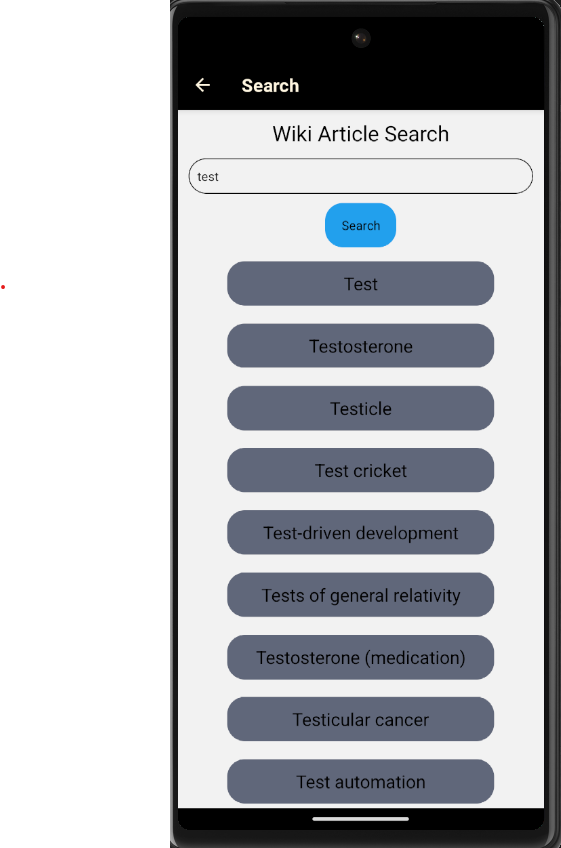
Search page
-

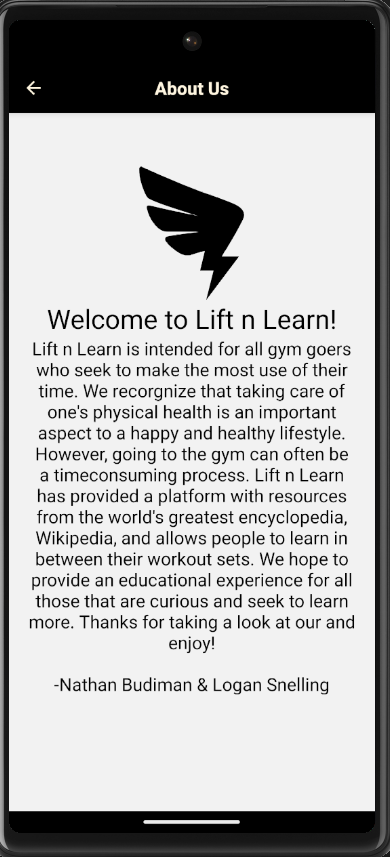
About page
-

Block chunk
-

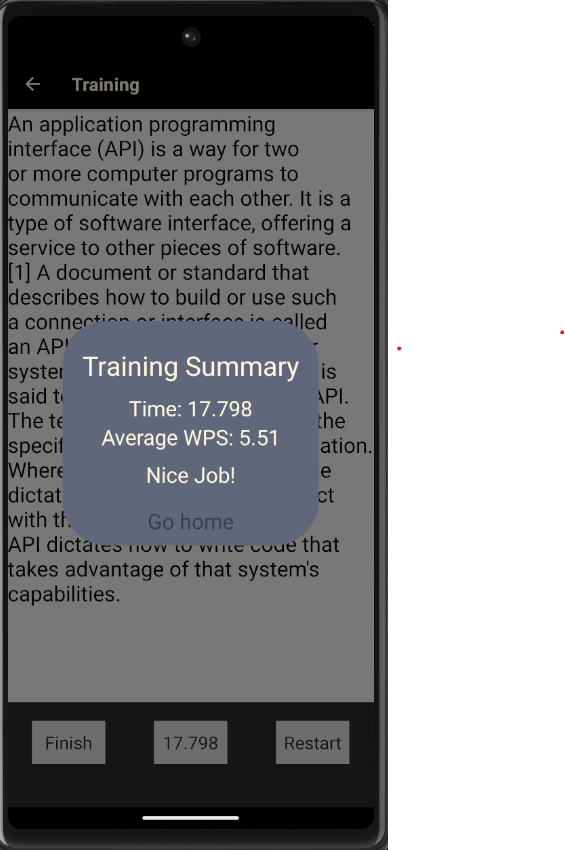
Training
-
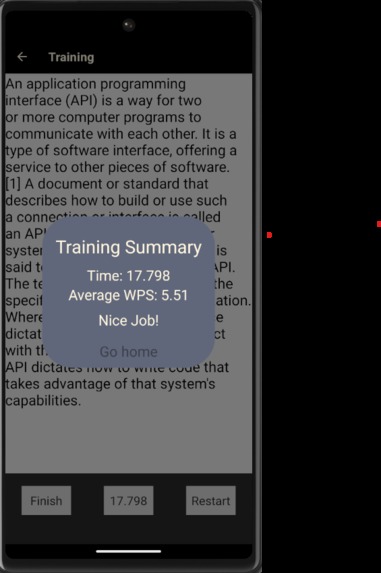
Training Summary


Inspiration
One of my hobbies is working out and lifting weights at the gym. Though I do thoroughly enjoy the process, I found that it was often time consuming and took away from other mentally stimulating activities. Between workout sets, I would find myself mindlessly drifting through instagram or getting lost in reading an article. That's when I though of Lift n Learn - An app that would create custom chunked wiki articles that enabled users to both focus on learning and their fitness goals.
What it does
Lift n Learn is a mobile app. The main purpose of the app is to allow readers to split up large wiki articles into specific proportions. There is a calibration feature that allows the system to track users reading speed and a setting for break time. Based on these two parameters and the article the user selects within the app, the app will generate bite size chunks of the wiki article. These chunks are expected to be read by the user in the break time they've specified.
How we built it
The frontend is built in React-Native and run on expo go, there are no UI frameworks, traditional stylesheets and css was used to design and build the mobile application. The backend is built in Python Django and involves the data processing for chunk splitting and API calls from Wikipedia
Challenges we ran into
The most difficult challenge was building the data processing for the wiki chunks in Python Django. From an algorithmic perspective, we intended to split the chunk the moment the client requested access to the article to prevent the need for a large and inefficient database. After several iterative approaches, the team developed a greedy algorithm. The wiki API returns full wiki articles in HTML. Parsing the data, getting only paragraph and headers and finding coherent ways to organize the blocks while ensuring the user requirements for breaktime were met proved difficult. The team's solution was to split the chunks by separate paragraph and header objects. Based off the users expected word count for blocking, the backend would combine and stich together adjacent paragraphs to ensure the reader had roughly equal chunks that were coherently put together between sets.
Accomplishments that we're proud of
We're proud of finding an efficient and effective algorithm for data chunking, building a responsive UI with basic caching features and effectively navigating through the challenges of using a windows laptop to host the backend server and iPhone for mobile app development (Which was incompatible and required many work arounds).
What we learned
The biggest thing for us was learning to work as a team and communicate properly to ensure we understand the same business requirements. In addition, integrating backend and frontend, working together to solve difficult algorithmic problems and working together to do more than we ever could alone proved extremely valuable. I felt we were a great team and was able to accomplish a lot more because we collaborated and communicated effectively.
What's next for Lift n Learn
The app still has some minor glitches and doesn't have any database to store user information or allow users to upload their own chunk size articles. the team may look into further improving the application and making it viable for the real world in the gym.
*Note: The application is a mobile app, so we were not able to release it publicly within the time specifications. In addition, due to Apple HTTP safety protocols, the backend cannot communicate with the frontend in development. An android mobile app works with the Python Django API for development.

Log in or sign up for Devpost to join the conversation.