-
-
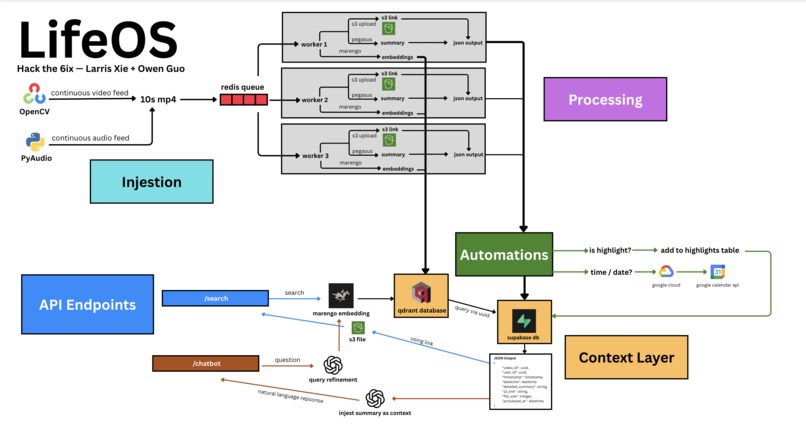
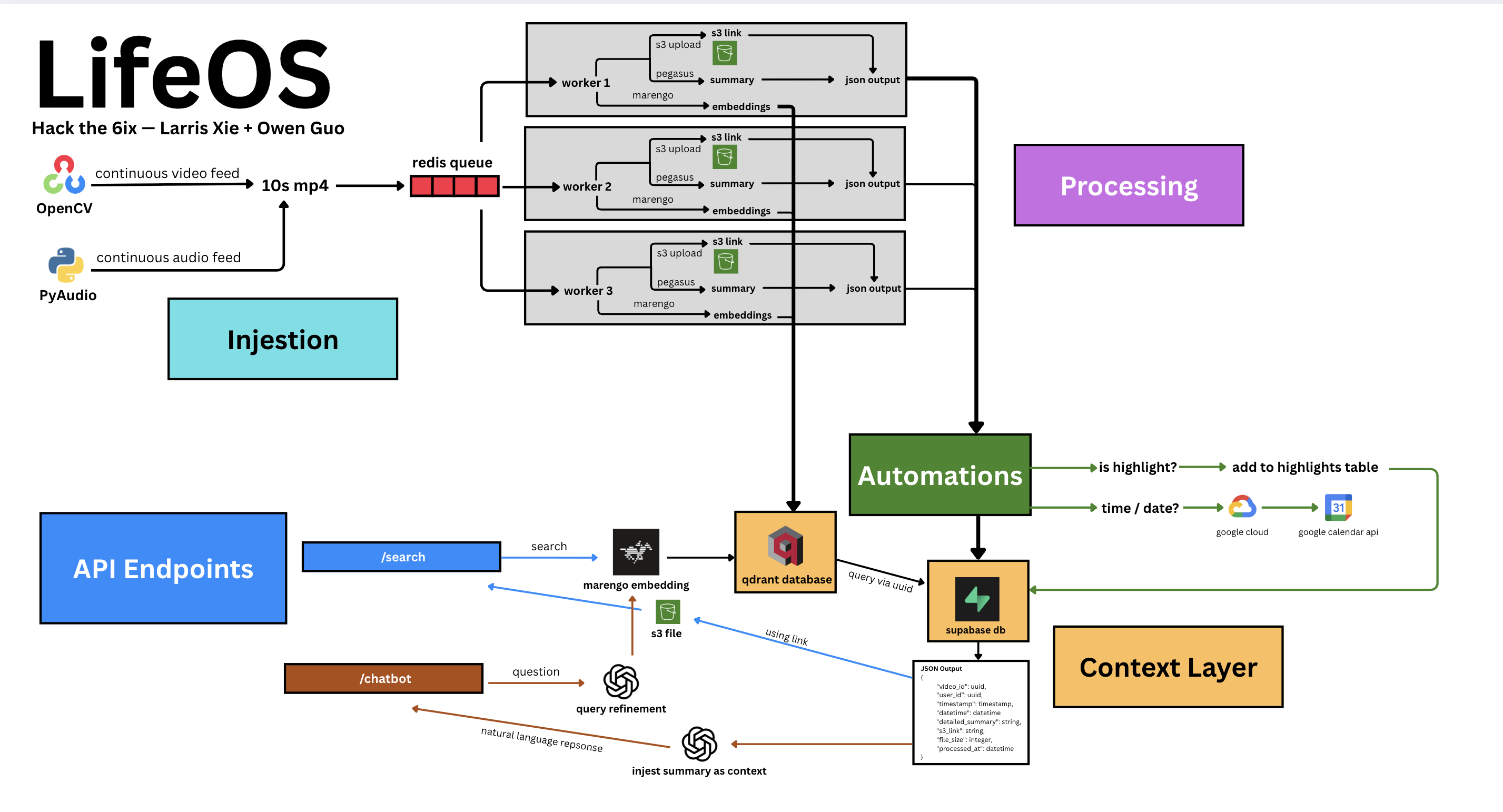
Systems Diagram
-

Loading Page
-
Home Page
-
Chat Page
-
Highlights Page

Inspiration
While AI has become a prominent part of our lives, it suffers from a lack of context, forcing users to spend a lot of time priming the model with details from their lives. The inspiration came from Meta Glasses — imagine they were always recording and gathering context about your daily patterns, habits, and fed it all back into an agentic model. It would be the perfect personal assistant, study partner, field doctor, coach, and more.
The most popular apps nowadays build on this concept, such as Cursor, which a much better coding experience due to its context of the codebase, it understands the patterns.
Hence, we wanted to build the infrastructure layer for an in-person Model Context Protocol (MCP) implementation. It gathers context using a continuous video feed, which is summarised and embedded into our database for retrieval as context. It serves as the base layer for a new paradigm of apps built for smart glasses — integrating real life with automation and allowing other developers to create their own integrations.
How LifeOS Was Built
The project can be split into the following sections:
Injestion
OpenCV and PyAudio are used to continuously feed in video and audio in real-time, where it is spliced into 10 second clips.
Processing
These clips are then put into a Redis Queue, which feeds into 3 workers, each running two tasks in parallel: creating multi-modal embeddings using TwelveLabs' Marengo 2.7 Model, and also creating natural language summaries with TwelveLab's Pegasus 1.2 while uploading the raw video to an S3 bucket. A uuid is generated, which relates the embedding, stored in a vector database (Qdrant), and a JSON (summary, S3 link) which is stored in a relational database (Supabase).
Automation
While the JSON is uploaded to Supabase, the summary is passed through an automation layer, which uses natural language processing to determine whether any of the preset automations should have their functions called. We created Google Calendar integrations, which detects when dates are mentioned and schedules them in, and also a personal highlight journal, which captures their most exciting moments. This is where the potential for people to build comes in — others can take advantage of this MCP to use the context for their own integrations and build on top of this infrastructure we provide.
API Endpoints
/search: The natural langugage query is passed through Marengo's embedding model, which vectorises the search, allowing for the most similar video to be found in the vector database. Then, using its uuid, the Supabase is queried, returning the actual summary and S3 link which displays the clip.
/chat: In order to communicate with an LLM, who has full context of your life, the user's question prompts the model to generate relevant queries, which are embedded and the summary is returned as above. Then, with that context, and the initial question, the LLM is able to return a comprehensive answer.
The remaining endpoints are accessed through a combination of CRUD routes, OAuth for creating a JWT token for login, and integrations using external APIs (Google Cloud -> Google Calendar).
Challenges + Learnings
The main challenge we faced initially was the high latency when processing in series, especially with Marengo's multi-modal embedding bottlenecking operations where it wasn't necessary. For a 10 second video, it was taking upwards of 1 minute to process and add into the database — in order for the context to seem real-time, the retrieval and processing speeds needed to be faster. This was our first time working with infrastructure that was this complex, and that needed to scale especially well, since we wanted to create something that other developers could use.
That's why we began by drawing a comprehensive systems diagram (refer to images), which allowed us to parallelize certain tasks that were independent, saving a lot of time. Furthermore, the implementation of a queue and multiple workers allowed us to scale horizontally and load balance the incoming requests for lower latency.
This was a really good project to dive into systems design and infrastructure, and we were exposed to a lot of new tools that could streamline this process, like AsyncIO for concurrent processing. Furthermore, it was awesome exploring the TwelveLabs API, which was able to generate incredibly accurate and detailed descriptions of videos through the Pegasus model, and precise searches with the Marengo model. It was also our first time working with vector databases, which was a big challenge compared to traditional SQL and NoSQL based databases.
Backend:
Database / Storage: AWS S3, Qdrant, Supabase (PostgreSQL)
API + Processing: FastAPI, AsyncIO, Redis Queue
NLP + Video: OpenAI (GPT-4), TwelveLabs (Pegasus 1.2, Marengo 2.7), OpenCV
Infra: Docker
Frontend:
Framework: Next.js / React
UI/UX: TailwindCSS, Framer Motion





Log in or sign up for Devpost to join the conversation.