
Inspiration
Every student hits a moment where logic runs out — grad school or a job offer, staying near family or chasing a better salary in another city, playing it safe or betting on a startup. We searched for tools to help and found only two extremes: spreadsheets that compare numbers but ignore how it feels to live with the choice, or AI chatbots that confidently tell you what to do, as if a model trained on the internet could understand your relationship with your parents.
We wanted something honest. An AI that does what AI is actually good at — modeling possibilities, surfacing tradeoffs, catching blind spots — and then has the integrity to say: "Here's everything I can compute. The rest is yours."
That gap became LifeLens AI.
What it does
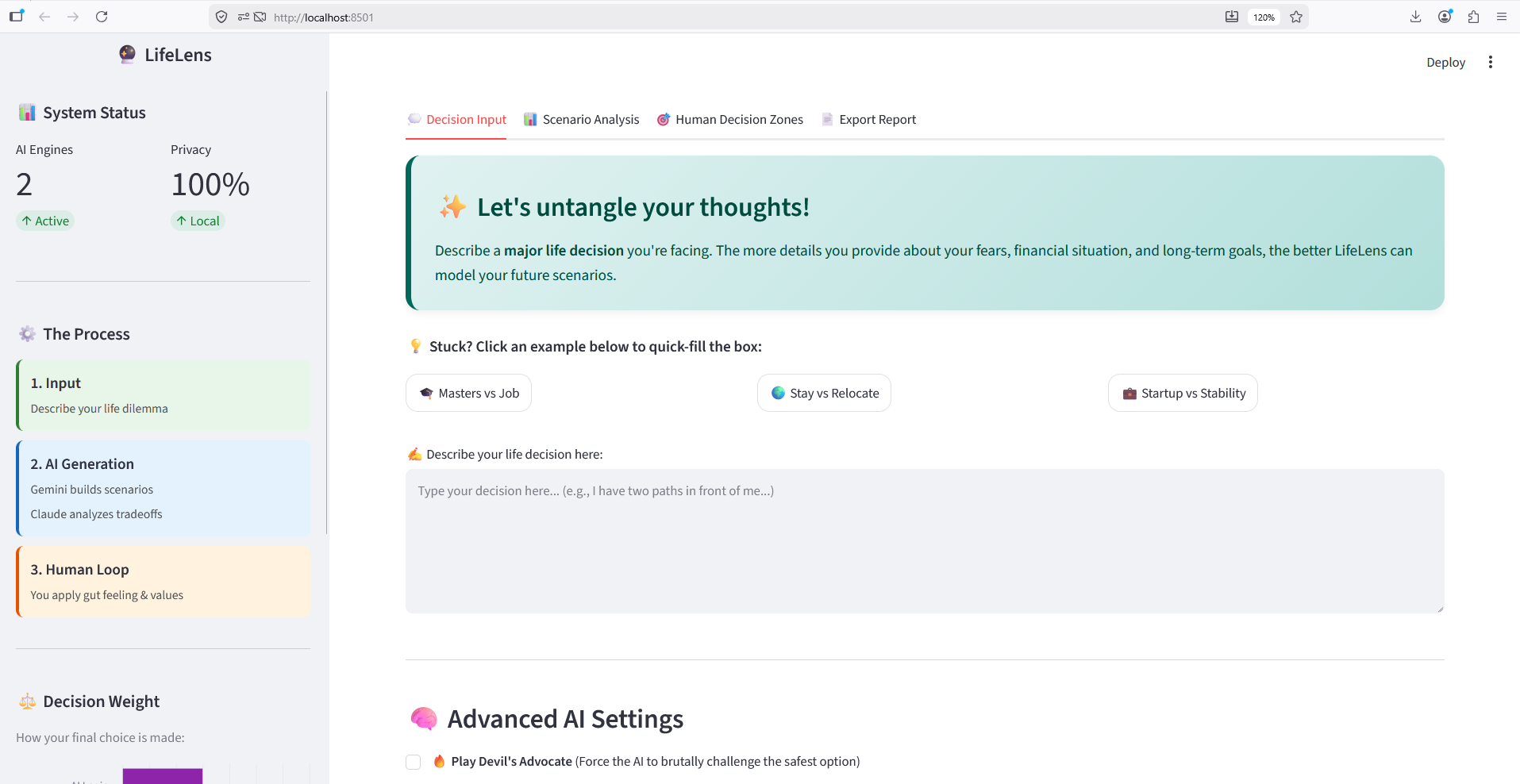
LifeLens AI is an interactive decision simulator for major life choices. A user describes their dilemma in plain language, and the app:
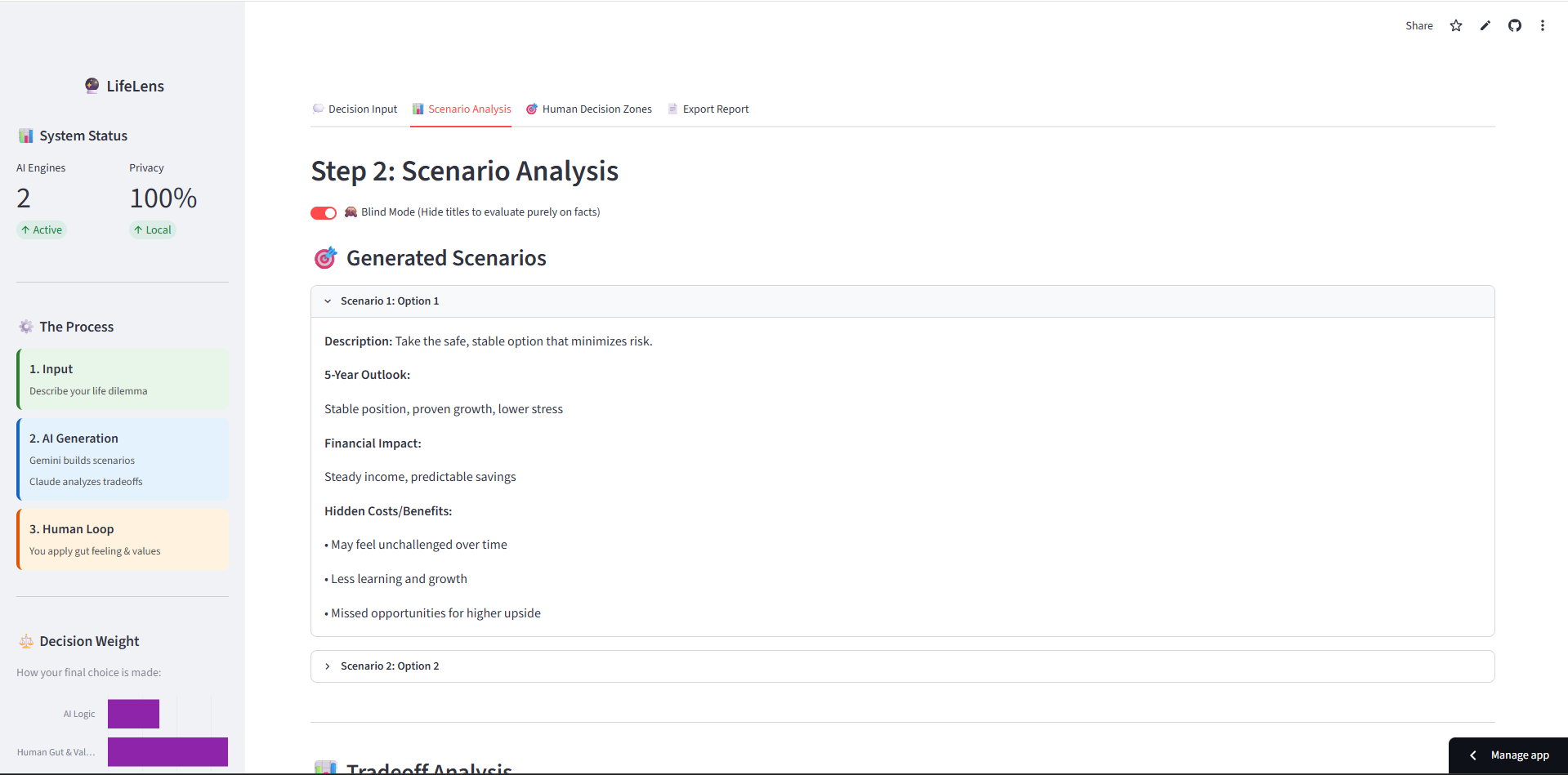
- Generates 3-4 realistic scenarios for their decision, each with a 5-year outlook, financial impact, and hidden costs/benefits most people overlook
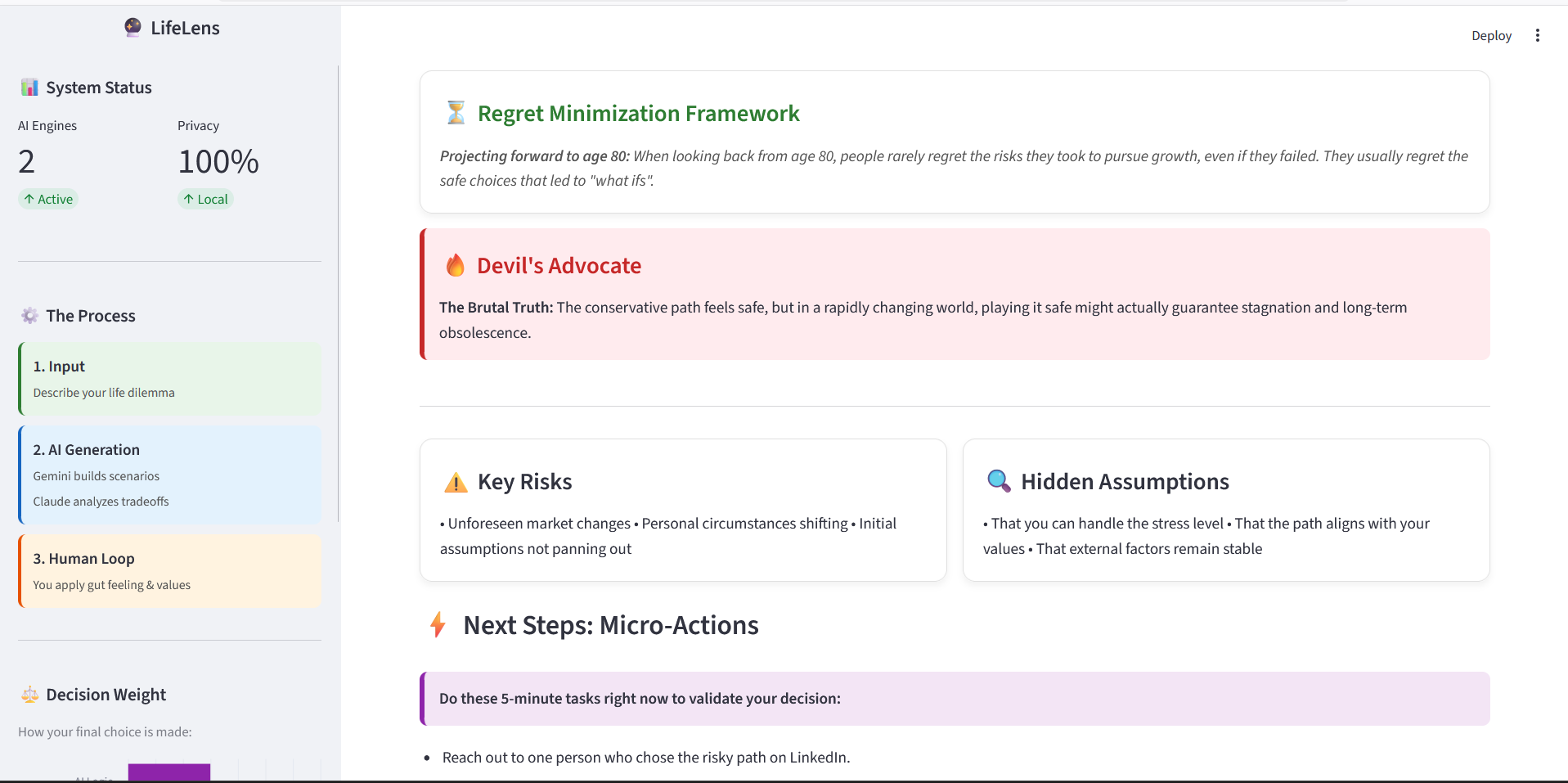
- Runs a deep tradeoff analysis — key risks, hidden assumptions, and what would need to be true for each path to succeed
- Applies a Regret Minimization Framework (inspired by Jeff Bezos' mental model), projecting the user to age 80 and asking which path they'd regret not taking
- Optionally activates Devil's Advocate Mode, where the AI deliberately attacks the user's safest-looking option to break confirmation bias
- Offers Blind Mode, hiding scenario titles so users evaluate facts without prestige bias (e.g., judging "Google" vs. judging "Option 2")
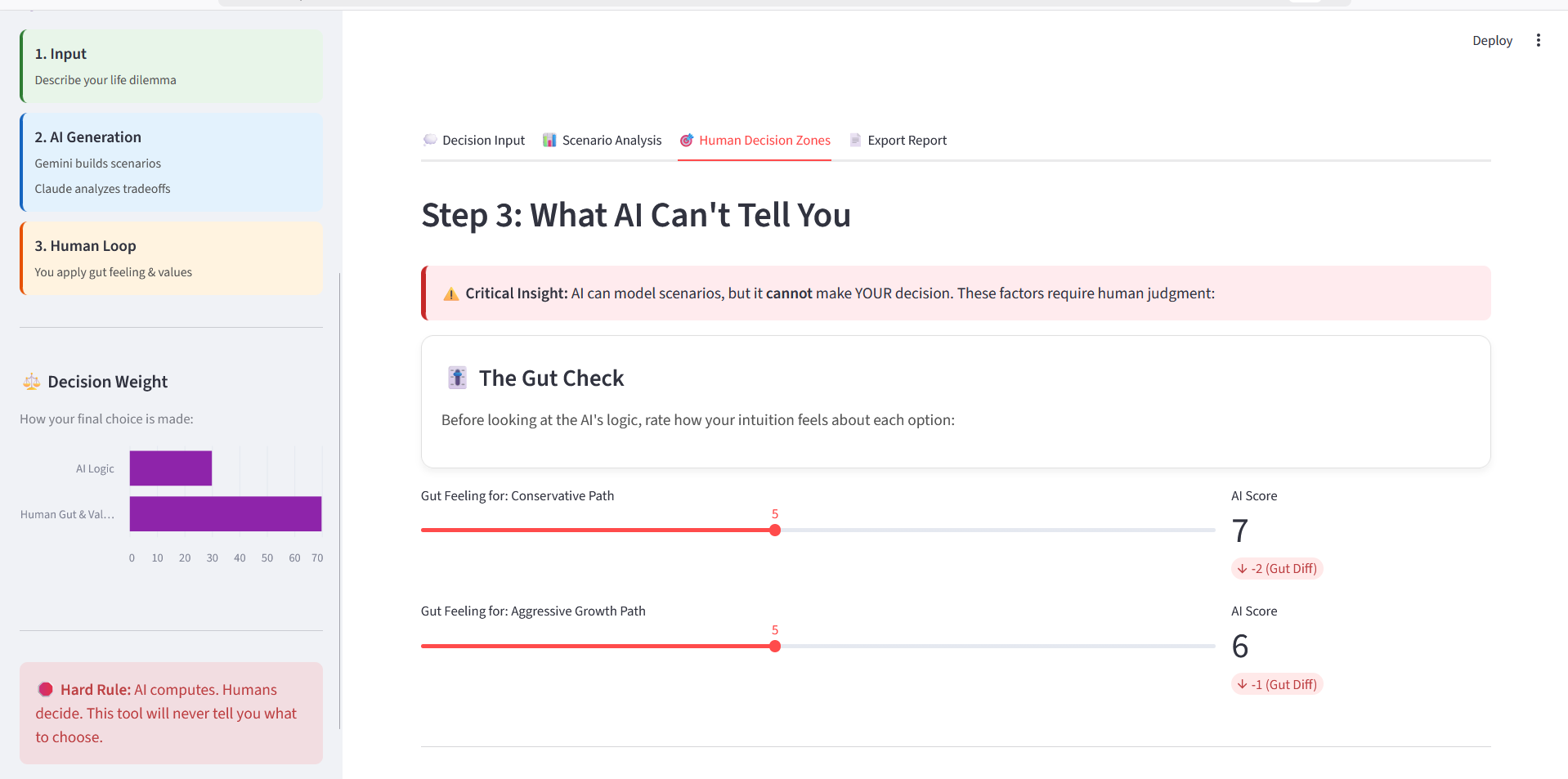
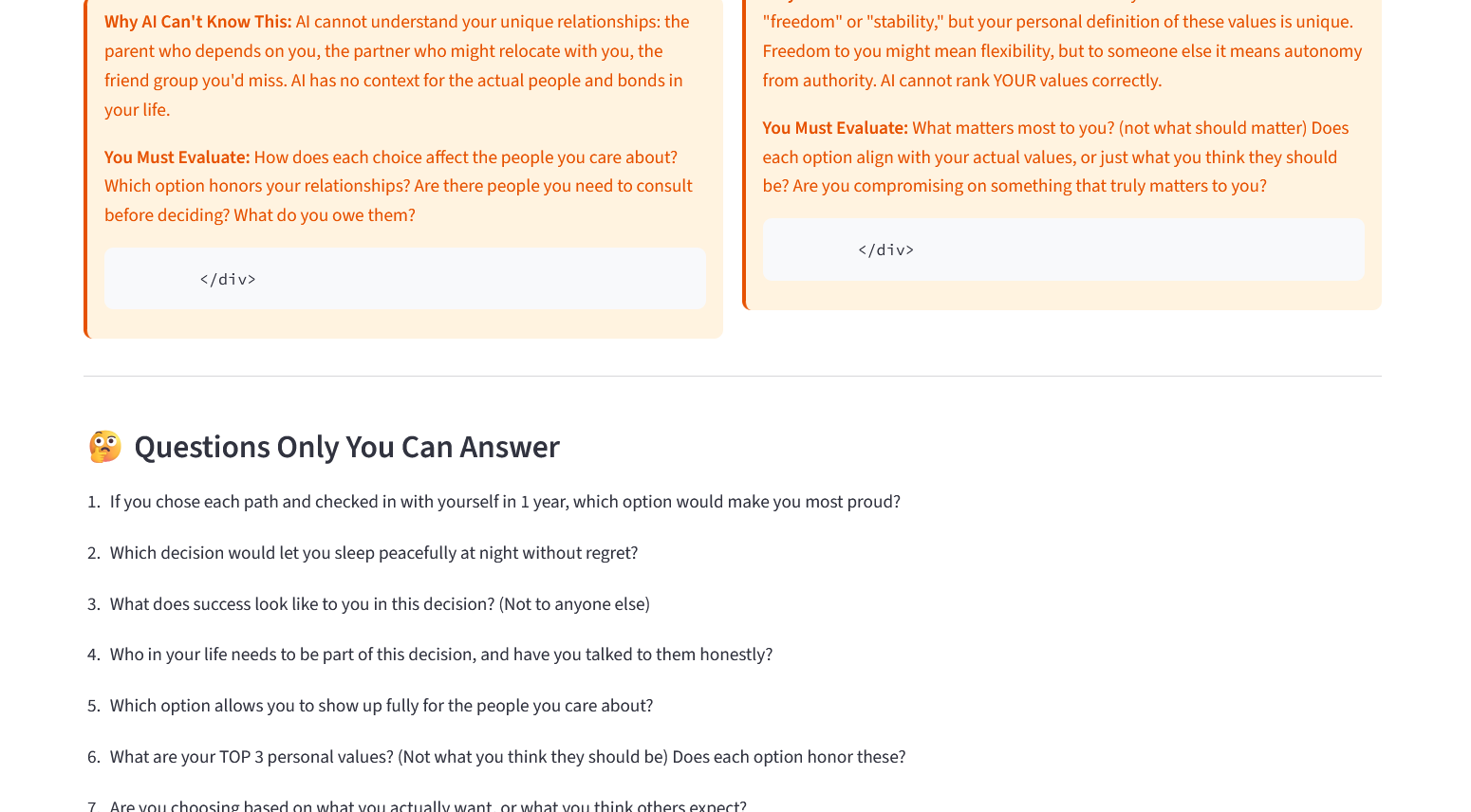
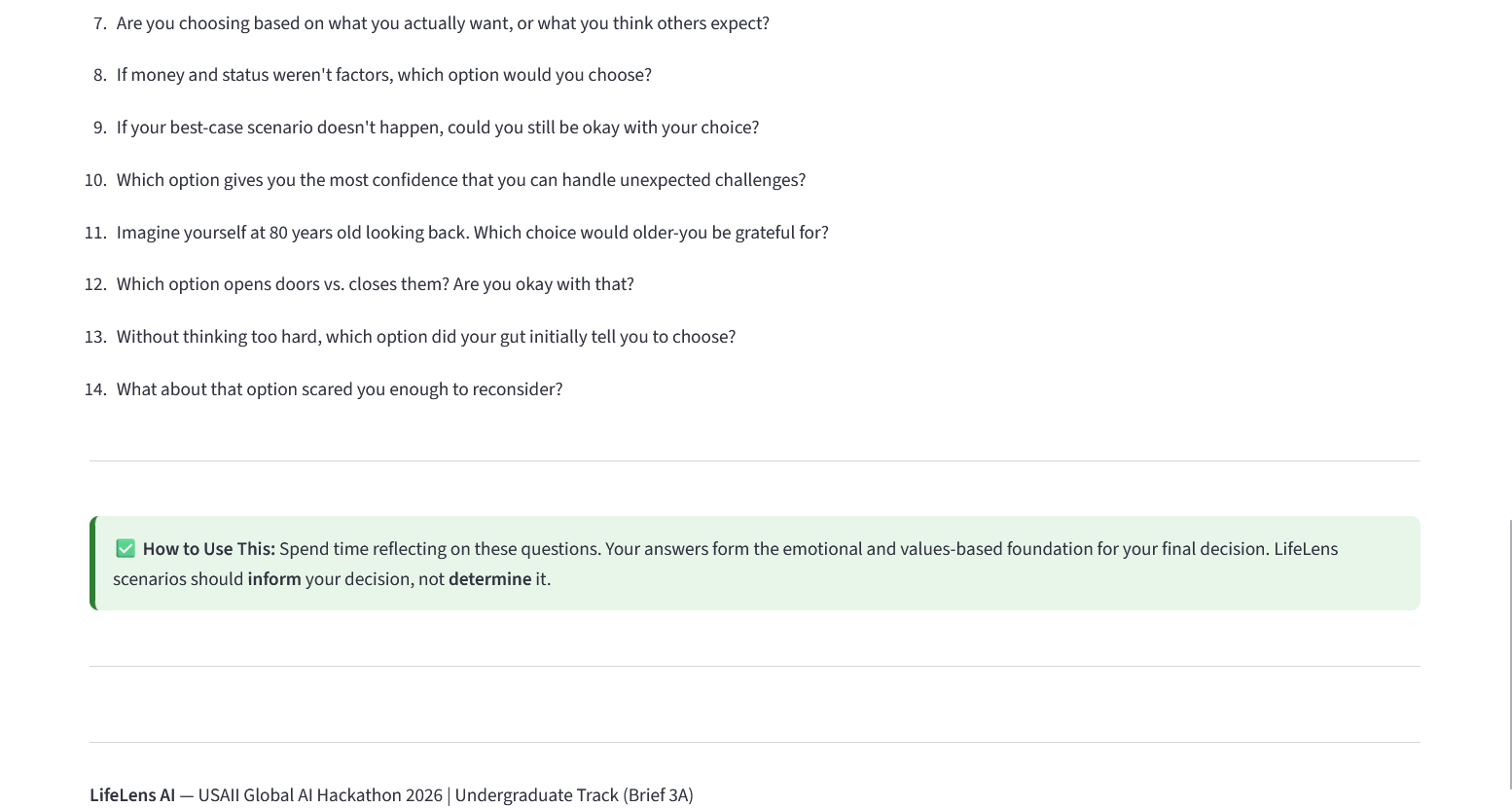
- Surfaces Human Decision Zones — an explicit, interactive section listing what the AI cannot determine: emotional weight, relationship impact, personal values, and gut intuition
- Includes a Gut Check slider, where users rate their own intuition per scenario side-by-side with the AI's logic score, visualizing exactly where emotion and computation diverge
- Generates micro-actions — tiny, 5-minute real-world tasks to validate the decision today
- Exports everything into a clean PDF report to share with mentors, parents, or advisors
The final decision is never made by the app. It's handed back to the user, every time.
How we built it
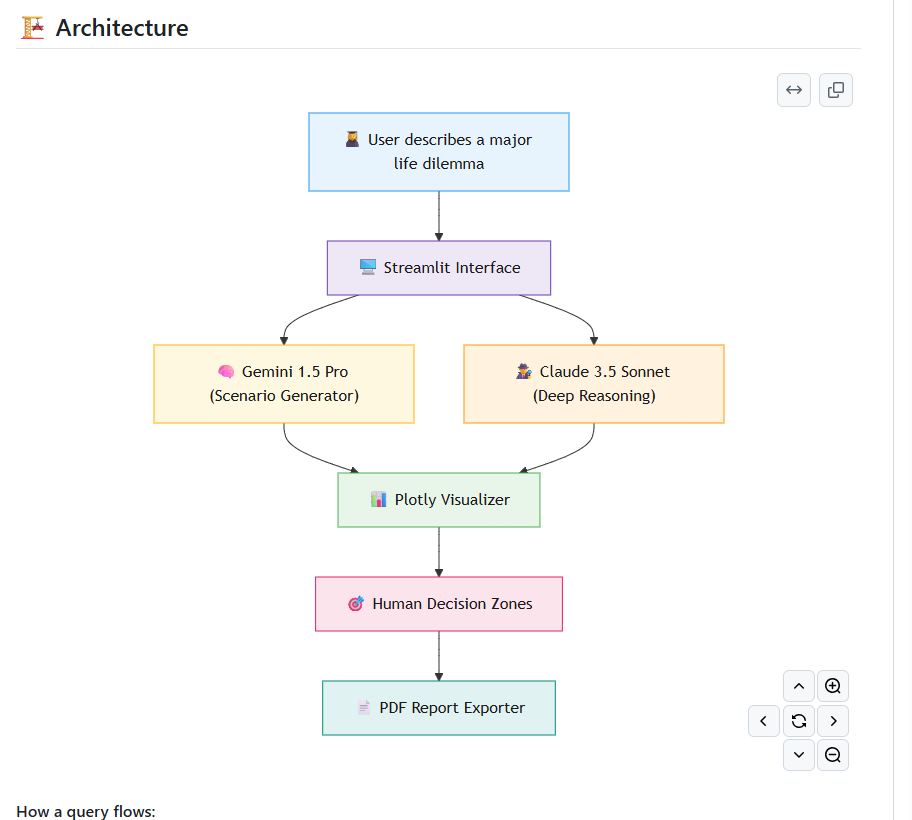
Architecture — two AI models, each doing what it's best at:
- Google Gemini generates the initial scenarios. We use it here because scenario generation is a creative, divergent task — we want several genuinely different narrative paths, not one "optimal" answer.
- Anthropic Claude performs the deep reasoning layer on top of those scenarios: tradeoff analysis, hidden assumptions, the regret-minimization projection, and (when enabled) the Devil's Advocate critique. We chose Claude here because this stage needs careful, nuanced judgment about risk and consequence rather than creative breadth.
This is the core of our AI Architecture: divergent generation (Gemini) feeding into convergent reasoning (Claude), rather than one model trying to do both badly.
Responsible AI Guardrail: The realistic risk we identified is that any AI decision tool risks over-trust — a user treating a generated "confidence score" as ground truth for a deeply personal choice. Our concrete mitigation is the Human Decision Zones module: a dedicated, unskippable section of the app that explicitly lists what the AI cannot access (emotional weight, relationships, values, intuition) and forces interactive engagement — the Gut Check sliders — before the user can treat the AI's output as complete.
Human-in-the-Loop Design: The AI never outputs a recommendation or a "you should choose X." Every output is framed as information to weigh, not an answer. The Gut Check feature literally puts the user's own intuition score next to the AI's logic score and shows the difference — making the human's judgment a visible, required input rather than an afterthought.
Stack:
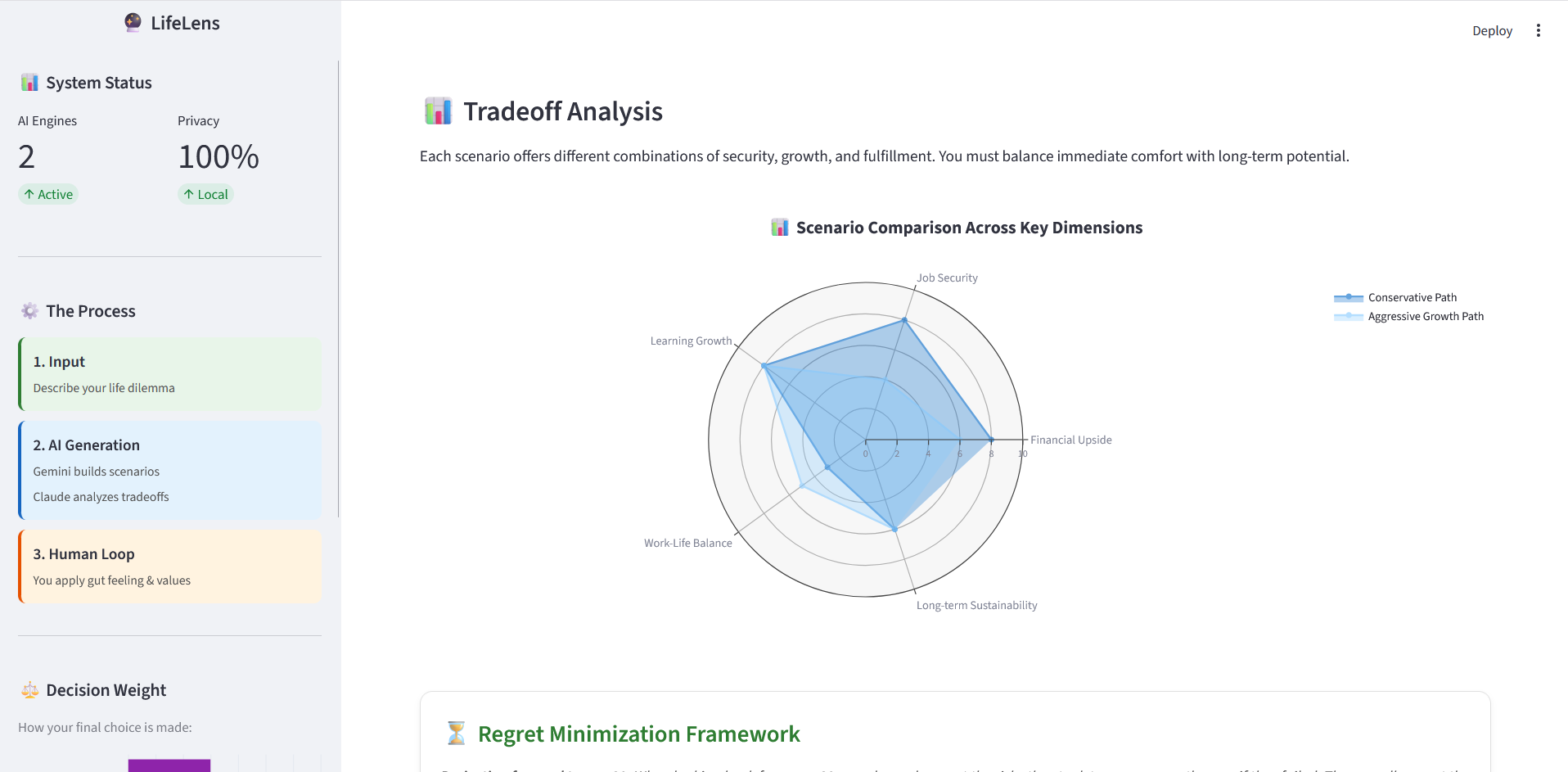
- Streamlit (Python) for the interface, with custom CSS for a card-based, modern dashboard feel instead of default Streamlit styling
- Plotly for tradeoff radar charts comparing scenarios across dimensions like financial upside, security, and growth
- ReportLab for PDF report generation
- python-dotenv for secure API key management
We also built a fallback layer: if either API fails or hits a rate limit mid-demo, the app gracefully loads pre-written standard scenarios instead of crashing or exposing a raw error — important for a live judging environment where reliability matters as much as ambition.
Challenges we ran into
Our biggest challenge wasn't the AI logic — it was silent failures. Early on, both our Gemini and Claude API calls were failing (a deprecated model name for Gemini, and a missing explicit API key parameter for Claude), but our own error handling was too good at hiding it — it silently fell back to demo data every single time, so every test input produced identical output. From the outside, the app looked broken and "non-responsive to user input," which would have been disastrous in front of judges.
We fixed this by making failures loud during development: surfacing the real underlying exception in the UI instead of swallowing it. That one change took us from "mysteriously identical output" to pinpointing two exact root causes in minutes — a lesson in why defensive code shouldn't be silent code.
The second challenge was scope. A mentor session pushed us hard on: "What is the ONE thing your AI does — what goes in, what comes out, what does the user do with it?" We had to resist adding more features and instead make sure the core loop (decision in → scenarios + analysis out → human reflection) was rock solid before treating everything else as polish.
Accomplishments that we're proud of
- A genuinely dual-model architecture where each AI is doing the job it's actually good at, not just calling two APIs for the sake of it
- The Human Decision Zones framework — we believe this is what separates LifeLens from a typical "AI advice" wrapper. We're not hiding AI's limitations; we're designing around them on purpose
- A working Devil's Advocate and Blind Mode that directly target two well-documented cognitive biases (confirmation bias and prestige bias) — these came directly from thinking about how real people make bad life decisions, not from "what feature sounds cool"
- Built and shipped a complete, polished, end-to-end product as a two-person team within the build window
What we learned
We learned that responsible AI isn't a section you add to a submission — it has to be a design constraint from the start. Our Human Decision Zones feature exists because we asked "what can this model never know about this user?" before writing the scenario generation code, not after.
We also learned a very practical lesson about debugging AI applications: when your fallback logic is well-designed, it can accidentally mask the very bugs you need to see. Good error handling for users and good error visibility for developers are not the same thing, and you need both
The Decision Impact
LifeLens AI fundamentally changes how students approach life-altering choices. Instead of freezing in anxiety or blindly following an AI's dictation, users walk away with a clear, unbiased map of their futures and a localized understanding of their own intuition. The real-world impact is absolute clarity without the loss of human agency — turning overwhelming crossroads into structured, manageable, and highly personal action plans.
What's next for LifeLens AI
- Specialized decision tracks — career, relocation, education, and relationship decisions each have different hidden factors worth modeling differently
- Mentor collaboration mode — letting a trusted advisor leave comments directly on a user's generated report
- Outcome tracking — opt-in follow-ups 6 months or a year later, asking users how the decision actually played out, to eventually validate (or humble) our own scenario modeling
- Multi-language support, so the tool is usable beyond English-speaking students

Log in or sign up for Devpost to join the conversation.