
Inspiration
As most people enter the workforce we are told to consider the "cost of living" before deciding on a job or internship. In our recent search we found that there is no definite resource for finding the cost of living. With the wide variety in the costs of living across California, we find this information to be a necessity for students and industry juniors looking at prospective locations to begin their career.
What it does
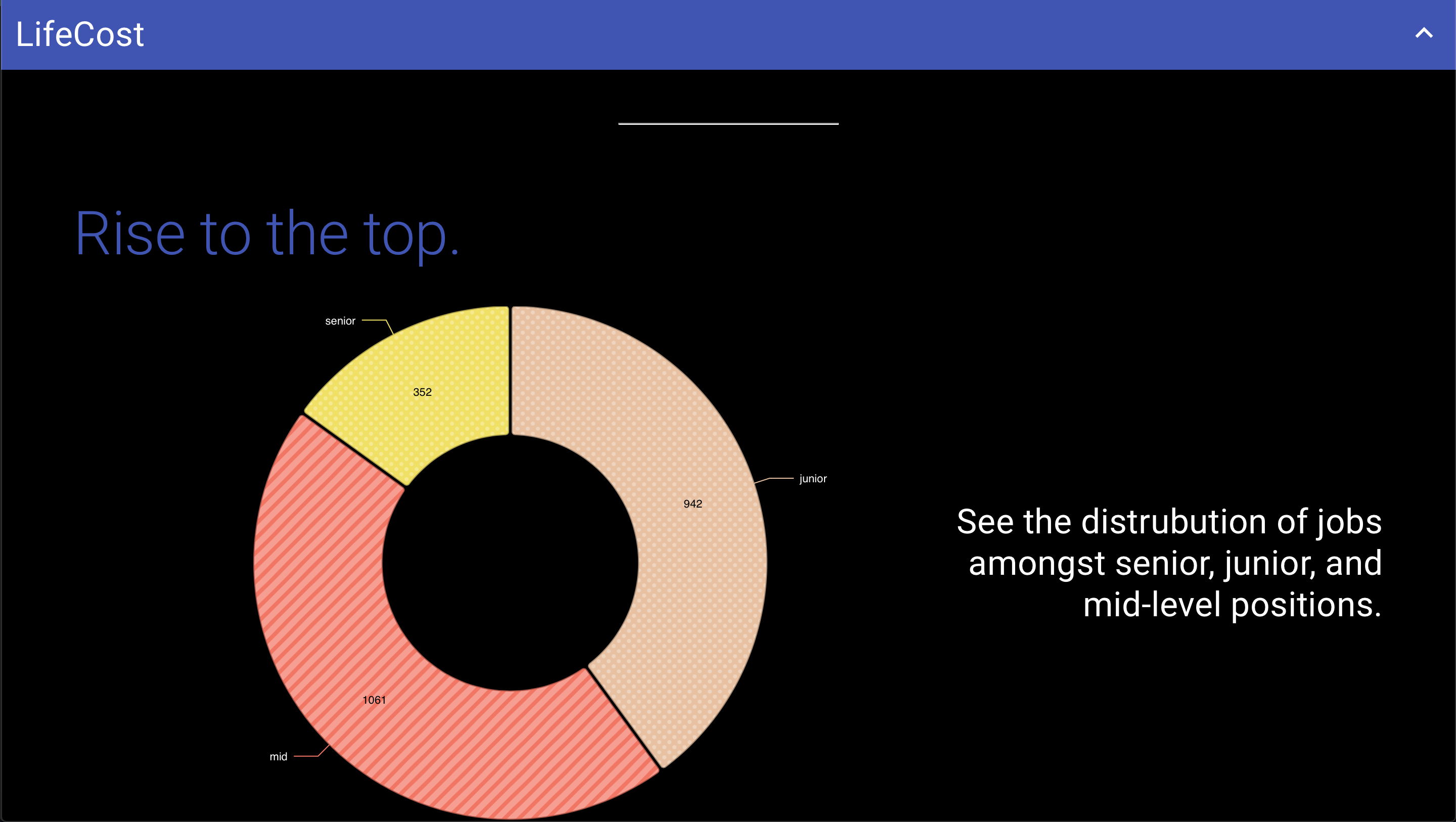
LifeCost helps users find out where they want to work or live. We provide accurate and reliable information about any city in California's cost of living and job market through analysis of job listings on the internet. We split jobs into senior, junior, and mid level positions to show the potential for career growth years in the future, so users can make the most informed decision. For every city, a user can search for over 780 different prospective careers. Moving is an expensive and permanent decision that impacts someone's future indefinitely, and LifeCost hopes to gives the individual more control.
How I built it
We get data by scraping websites with scrapy and selenium and store that data in a postgres database. We serve this data with an express backend and a react frontend.
Challenges I ran into
To scrape many of the websites we needed a list of cities but there was not many readily available lists of cities. Initially we used this list but later switched to the list of cities that we got from scraping for sales tax in California. One of our scrapers had scraped well over 1.7 million pages, and took 12 hours to complete. We couldn't work on a lot of the project until this scraper had completed.
When we first connected our backend to our frontend we found that some people are not very good at typing in correct city names or job titles. We didn't want people to expect to have to type in an exact city or job title and in our specific format. To solve this issue we had to approximate string matching that was accurate but also fast because we had about ~2100 cities and 780 different job titles. We ended up using Metaphone to find terms that sounded the most similar.
We initially wanted to scrape Twitter tweets for sentiment analysis but found that in order to use their api we needed to apply. The application requirement and the rate limits set by Twitter led us to scrape their front front end interface. We found that most elements on the page is dynamically loaded we swapped to using Selenium specifically for Twitter. We were able to scrape tweets and do sentiment analysis but we had to drop this idea because we were not able to scrape enough tweets to provide reliable and accurate information.
Due to the changing nature of our features, the design of the frontend had to be redone multiple times. Since we are a team with no designer, this often meant restructuring the entire page while in the process of adding basic functionality. Entire components were scrapped due to redesigning. This especially added challenge since our frontend uses a lot of libraries new to us. For example, a good amount of hours were spent into a 3D rendering library called threejs, but the 3D model we rendered didn't fit the atmosphere of the project. Instead we had to implement a particle rendering library. Additionally, the removal of the Twitter sentiment functionality resulted in a last-minute application of a graph library. While there are many more instances of this, the stress of adopting many libraries to change or remove them posed a great challenge.
Accomplishments that I'm proud of
We made our first web project only a few weeks ago so we're very surprised that our two member group was able to do so much in such a short amount of time.
What I learned
We learned much more about scraping, processing, and visualizing data. Our full stack application taught us a lot more about integrating the backend with the frontend. Since we used a large variety of frontend libraries, we were able to take with us a lot of information and experience about using them.
Most importantly, we learned about quickly adapting to changes in the project and its requirements. Our project took many forms over the course of the Hackathon and required us to be quick on our feet about drastic changes.
What's next for LifeCost
Twitter sentiment analysis was a feature that we really wanted to work but couldn't put in during the allotted time. Our goal for the feature is to scrape more places to make the application more reliable and useful, and provide general sentiment about cities through the analysis of Tweets near or about the location.

Log in or sign up for Devpost to join the conversation.