-
-
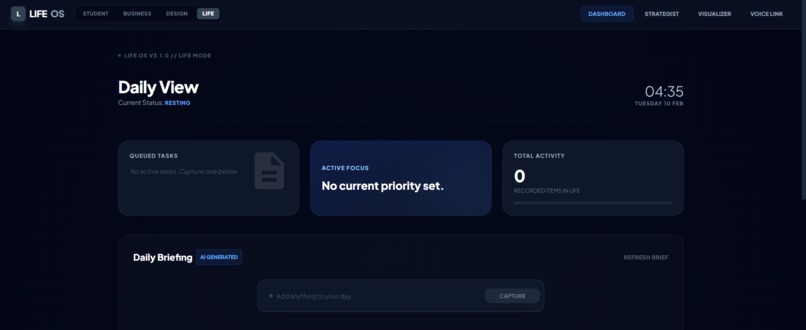
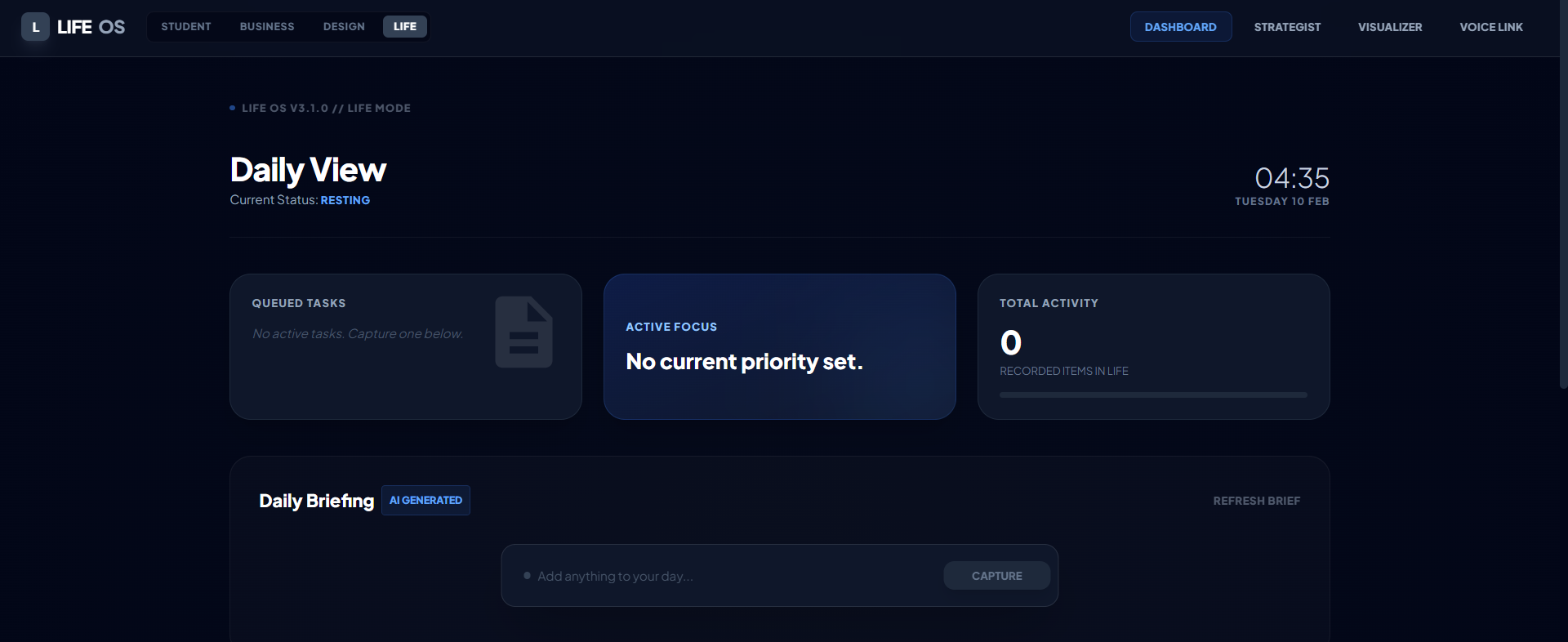
Smart command center with AI-generated daily briefs, priority tracking, and time-aware status adapts to your workflow in real-time.
-
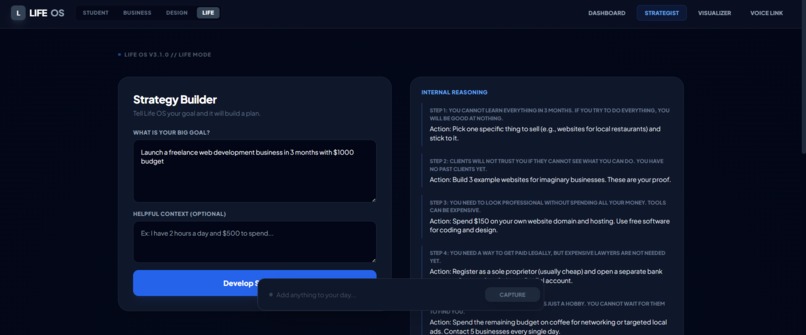
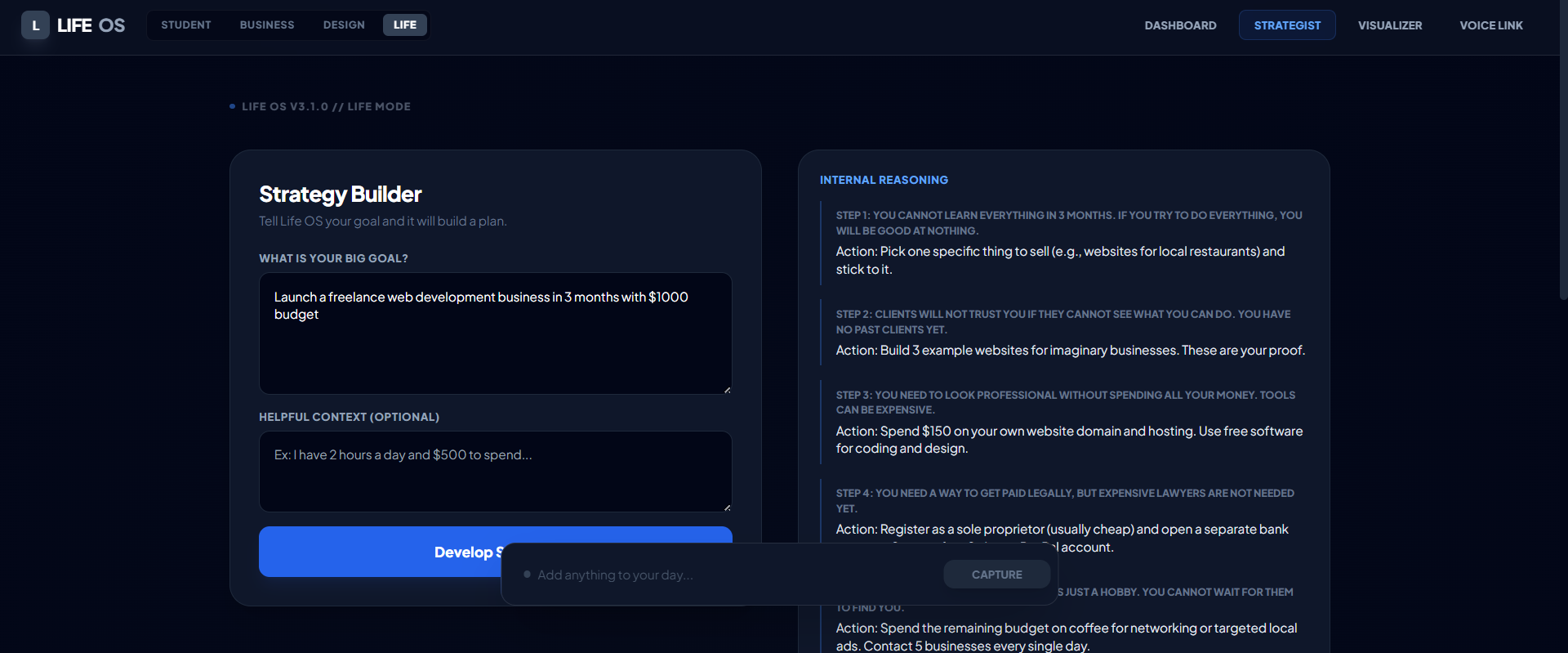
AI breaks down complex goals into actionable steps with transparent reasoning see exactly how Life OS thinks through your strategy.
Life OS: Autonomous AI Strategist
The Inspiration
I was working late one night, staring at my endless todo list, when it hit me. Every productivity tool I had ever used just organized my chaos. They never actually thought with me. They reminded me of deadlines but never asked why I kept missing them. They listed my tasks but never questioned if I was working on the right things.
That night, I wondered: what if an AI could actually strategize alongside me? Not just respond to commands, but actively reason through my goals, identify patterns in my failures, and help me plan for the long term? Traditional assistants are reactive. I wanted something autonomous.
When Gemini 3 launched with its advanced reasoning capabilities, I saw the opportunity. This was not just another language model. It could think through complex problems, generate visuals, create videos, and process voice. I could build something that operates like a real strategic partner.
Life OS became my answer to that question. A personal operating system that does not just help you get things done. It helps you think better.
What I Learned
Building Life OS taught me that AI orchestration is an art form. I started by throwing everything at Gemini 3 Pro, but quickly realized that was wasteful. Different models excel at different tasks. Pro is incredible for deep strategic reasoning, but overkill for simple classification. Flash handles quick data parsing beautifully and costs a fraction. Pro Image creates stunning architectural blueprints, while Flash Image iterates edits rapidly. Veo generates cinematic simulations that bring abstract workflows to life.
The breakthrough came when I embraced structured outputs. Early versions used free form text responses, which were unpredictable and hard to parse. When I switched to JSON schema enforcement, everything clicked. Suddenly I had type safe, reliable data flowing through the entire system. The UI could trust the API responses. The reasoning became transparent.
I also learned that users do not trust black box recommendations. When I just showed final strategies, people questioned them. But when I exposed the reasoning chains, showing exactly why the AI chose each step, trust skyrocketed. Transparency is not a nice to have. It is fundamental to human AI collaboration.
Context management was harder than I expected. Gemini models are stateless. Every request starts fresh. I built a hybrid system using LocalStorage for long term memory and selective context injection for each API call. Only the most relevant recent items get included to preserve token budgets while maintaining continuity.
How I Built It
The architecture revolves around four specialized engines, each powered by different Gemini models working in concert.
The Strategy Engine uses Gemini 3 Pro Preview for autonomous planning. When you input a goal and context, it does not just list steps. It breaks down the problem space, identifies dependencies, sequences actions logically, and assesses risks. Every recommendation includes explicit reasoning. You see the thought process, the chosen action, and potential pitfalls. This transparency makes the AI feel less like a tool and more like a collaborator.
The Data Ingestion system leverages Gemini 3 Flash for rapid natural language processing. You type freely, like talking to a human. "Finish the investor deck by Friday, high priority." The system automatically classifies it as a task, extracts the deadline, assigns priority, and tags it appropriately. It adapts to your current mode, whether you are a student managing coursework or a founder tracking business metrics.
The Visual Intelligence layer combines three modalities. Gemini 3 Pro Image Preview generates professional architectural blueprints from text descriptions. You can request system diagrams at 1K, 2K, or 4K resolution. Gemini 2.5 Flash Image handles iterative editing, letting you refine visuals with natural language commands. And Veo 3.1 creates animated 3D simulations of logical processes. Imagine watching your workflow come to life as a cinematic visualization.
The Voice Diagnostic interface goes beyond simple speech to text. It analyzes your goals, constraints, and past failures to identify systemic patterns. It tells you the brutal truth about why you keep hitting the same obstacles and suggests minimal viable changes to break the cycle.
Everything persists in LocalStorage, creating long term memory across sessions. The system generates daily briefs by analyzing your stored items and current priorities. It adapts to four contextual modes: Student, Business, Design, and Life. The same input gets interpreted differently based on your active mode.
The Challenges
Video generation with Veo 3.1 was my first major hurdle. Each simulation takes 60 to 90 seconds to generate. I implemented a polling mechanism that checks every 10 seconds, provides progress feedback, and caches completed videos. Users needed to understand this was not a bug. It was complex AI doing serious computational work.
Maintaining state across stateless API calls required creative architecture. I built a system that stores conversation history locally and injects relevant context into each request. Users can even edit memory directly, telling the system what to remember or forget. This hybrid approach balances continuity with fresh reasoning.
Managing multiple modalities in a cohesive interface was surprisingly complex. How do you make text reasoning, image generation, video simulation, and voice analysis feel like parts of one unified system? I solved this with consistent visual language, progressive disclosure of complexity, and tab based navigation. Start simple on the dashboard, reveal deeper capabilities as needed.
API key security in a client side application required careful thought. I use environment variables injected at build time through Vite, ensuring keys never leak into client bundles. The tradeoff is that this remains a prototype requiring users to supply their own Gemini API keys.
Balancing speed versus quality meant making intelligent model choices. Fast operations like classification use Flash. Deep thinking like strategic planning uses Pro. High quality visual generation uses Pro Image. Quick iterative edits use Flash Image. Each decision optimizes for the task at hand, following a simple heuristic:
$$\text{Model Choice} = \begin{cases} \text{Flash} & \text{if } \text{latency} < 1s \text{ required} \ \text{Pro} & \text{if } \text{reasoning depth} > \text{threshold} \ \text{Pro Image} & \text{if } \text{quality} > \text{speed} \end{cases}$$
The hardest challenge was building trust in autonomous recommendations. Early testers were skeptical when the AI suggested strategies. They wanted to know why. I restructured the entire output to expose reasoning chains. Now every recommendation shows the thought process, the dependencies, the risks. Users can audit the logic. This transparency transformed skepticism into confidence.
What It Means
Life OS proves that autonomous AI agents are not science fiction. They are buildable today with the right architecture and model orchestration. By combining Gemini 3 Pro reasoning, multi modal generation, voice interfaces, and transparent thinking, I created something that feels genuinely intelligent.
The future is not AI that just executes commands. It is AI that strategizes with you, questions your assumptions, visualizes your systems, and helps you think more clearly. That is what Life OS represents. An autonomous partner that amplifies human thinking rather than replacing it.
This hackathon pushed me to explore the full depth of what Gemini models can do. The result is a system that does not just help you get things done. It helps you understand why you are doing them and whether there might be a better way.
Built With
- aistudio
- gemini-2.5-flash-image
- gemini-3-flash-preview
- gemini-3-pro-image-preview
- gemini-3-pro-preview
- google-genai-sdk
- localstorage
- react-19.2
- tailwind-css
- typescript-5.8
- veo-3.1-fast-generate-preview
- vite-6.2

Log in or sign up for Devpost to join the conversation.