-
-
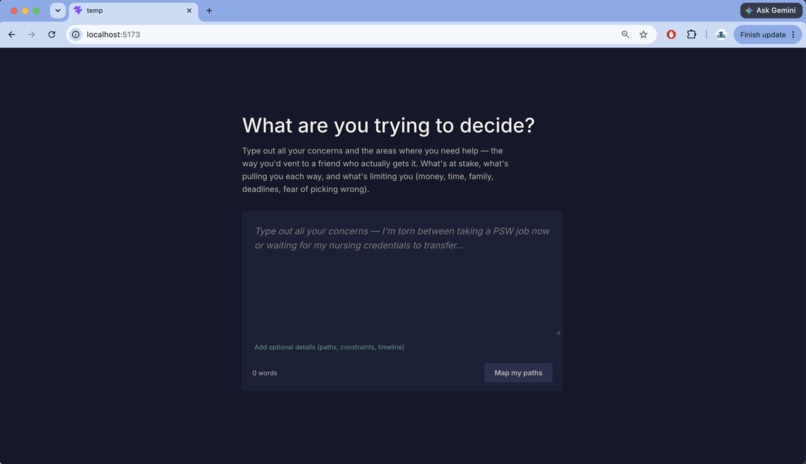
Mainpage
Inspiration
Major life decisions — immigration, career pivots, relocation, education vs. work — are rarely a simple pros/cons list. People face real constraints (savings runway, dependents, deadlines) and hidden tradeoffs they have not named yet. We built a tool that structures that thinking, models paths over time with honest uncertainty, and never tells anyone what to choose.
What it does
Users describe any decision in plain language. The system:
Extracts the core decision, binding constraint, and paths being compared Models each path at 3 months, 1 year, and 3 years — financial, career, and personal impact Surfaces non-obvious tradeoffs, hidden considerations, and what each path closes off Shows confidence per claim and flags what the AI cannot know Lets users challenge assumptions via what-if input and reruns reasoning dynamically Demo scenario: a Filipino RN in Toronto with 3 months savings deciding between PSW work now vs. CNO credential recognition. The same engine handles grad school vs. startup, relocation, and law school vs. bank offer — no code changes per scenario.
How we built it
Stack: React + Vite frontend, FastAPI backend, OpenAI API (gpt-4o-mini default), Pydantic schemas.
End-to-end flow:
Plain-language intake ↓ Phase 1 — Extract (LLM call #1) → binding constraint, paths, personal constraints, risk signals ↓ Phase 2 — Model (LLM call #2) → tradeoffs, timed outcomes, verification checklist, claims + confidence ↓ Phase 3 — Validate (no LLM) → reject generic pros/cons; auto-retry Phase 2 if quality fails ↓ Structured comparison UI + optional what-if rerun Why two LLM calls, not one: Extraction grounds Phase 2 in the user's actual constraints before tradeoff modeling. A single-shot prompt tended to produce generic advice; splitting extract → model improved path alignment and reduced template drift across domains.
Quality gate: validators.py programmatically checks for generic phrasing, missing URLs in verification items, overconfident long-horizon claims, and path count mismatches. Failed checks trigger auto-retries with targeted fix instructions.
Responsible AI: The AI never picks a path for the user, never claims anyone is "safe" or "verified," uses ranges instead of false precision, and pushes users to confirm facts on official sources before acting.
Challenges we ran into
Generic LLM outputs — Early responses sounded like pros/cons lists. We fixed this with a two-phase chain, few-shot quality examples, and a programmatic validator with auto-retry. Latency — Each request is 2–3 LLM calls (~60–90s). We added loading states in the frontend and a mock fallback when the API is unreachable. Overconfidence — The model defaulted to high confidence with empty unknown_factors. Prompt rules and the validator now enforce mixed confidence and failure branches on uncertain paths. Scope pivot — We started with a different direction and had to rebuild around a fully generic reasoning engine rather than domain-specific templates. Accomplishments that we're proud of One engine handles immigration credentialing, early-career, relocation, and education-vs.-job decisions without hardcoded templates. Binding-constraint-driven reasoning produces tradeoffs tied to the user's actual numbers and household situation. Uncertainty is visible in the UI (confidence labels + flags) and in the JSON contract judges can inspect. Four test scenarios run through the same pipeline with validation — proof the system generalizes beyond the demo video.
What we learned
Splitting extract from model improved coherence more than a longer single prompt. Programmatic quality checks catch generic phrasing that humans skim past in demo output. Honest uncertainty — ranges, failure branches, verification checklists — is a feature, not a weakness. It matches how real decisions work. Keeping the human in the loop (questions to ask employers, schools, regulators) builds more trust than pretending the AI has all the answers.
What's next
Structured intake follow-up questions feeding structured_context directly Streaming/partial responses to reduce perceived latency User-saved decision sessions and exportable verification checklists Evaluation harness with human-rated output quality across more domains Stronger guardrails for high-stakes decisions (legal, medical, financial) with clearer escalation to professional advice
Built With
- css
- fastapi
- html
- javascript
- openai-api
- pydantic
- python
- react
- rest-api
- server-sent-events
- uvicorn
- vite


Log in or sign up for Devpost to join the conversation.