-

Our web app currently lists 3 famous books with snippets of passages from them
-
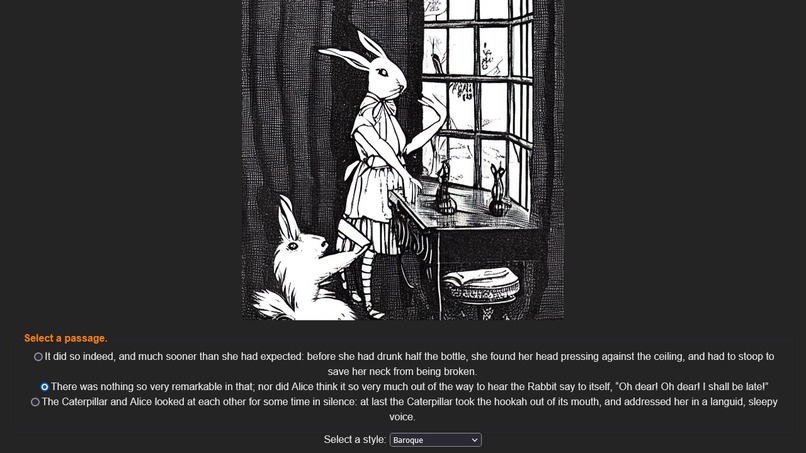
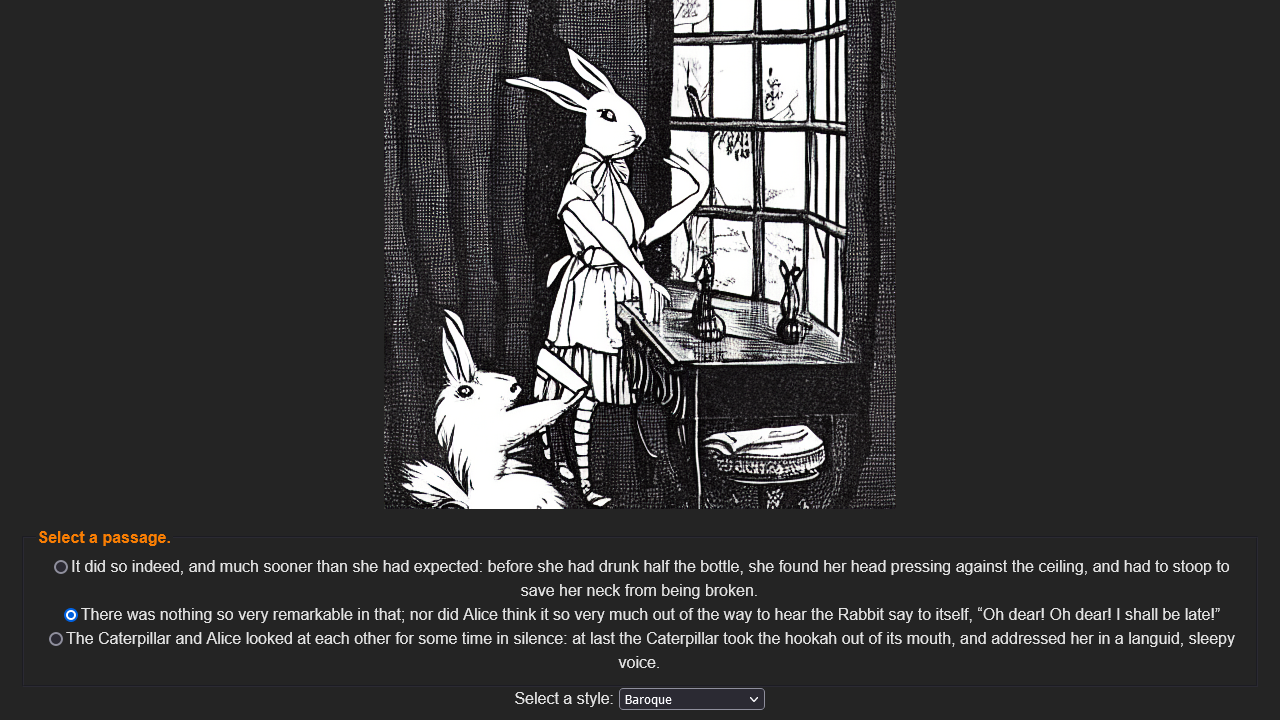
A user selects a text snippet, choose an art style, and waits for generated image
-
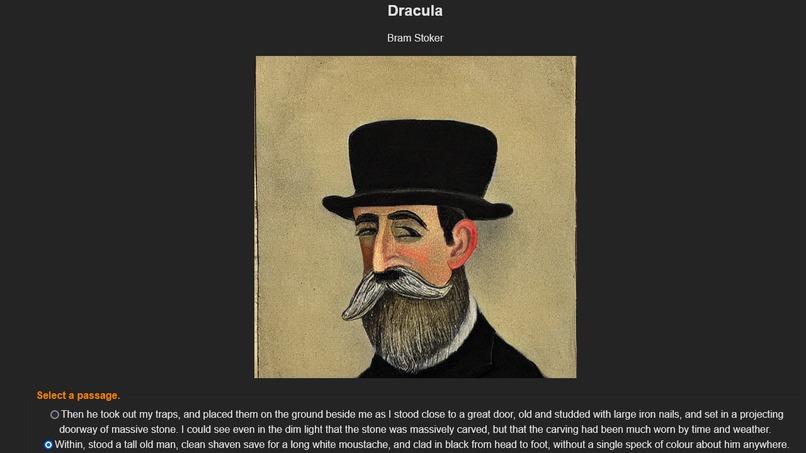
Illustrations will be unique every time, and have different results. Users can regenerate an image to their liking.

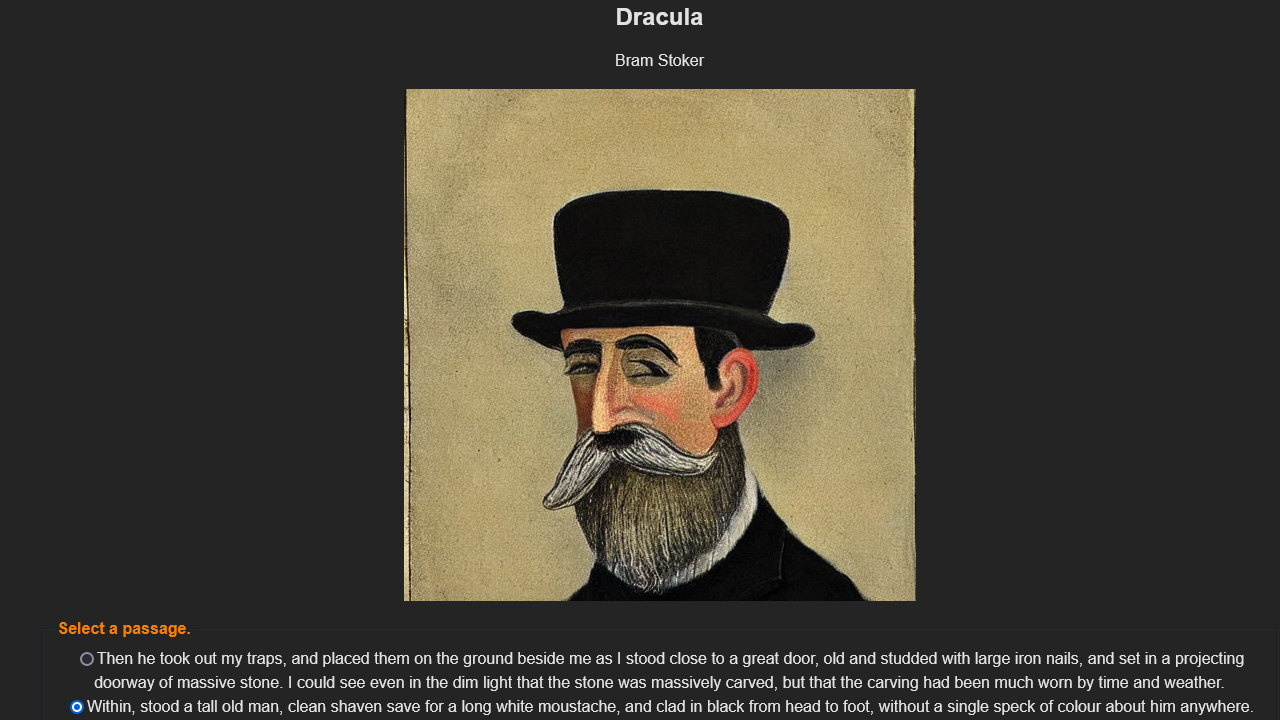
Inspiration
The inspiration for Librum came from the need to make classic literature more accessible and appealing to modern audiences, especially younger generations. With the decline of reading among younger people and the increasing popularity of social media, we wanted to create a tool that would help bring older books to life and make them more engaging for readers.
Additionally, we wanted to address the challenges faced by people with dyslexia, who may find it difficult to read and comprehend text-only books. With the advent of AI text-to-image generation, we were able to create a web application that allows users to generate beautiful, engaging illustrations for public-domain books, making them more accessible and enjoyable for all readers.
What it does
Librum is a web application that allows users to generate illustrations for public-domain books. The application uses diffusion models to generate illustrations of different styles based on snippets from a book selected by the user. This prototype showcases how readers can make books more appealing by generating visual aid, and ultimately helps with reading comprehension and enjoyment, especially for children.
How we built it
Librum was built using a combination of Vite/React for the front end, a RESTful API built with Flask, and AI powered by pyTorch and Stable Diffusion. The AI text-to-image generation technology was trained on a large dataset of images and text to enable it to generate realistic, high-quality images based on the text provided by the user. The user interface was designed to be intuitive and easy to use, allowing users to quickly generate images for their chosen text snippets and art styles.
Challenges we ran into
One challenge that we ran into while working on Librum was finding time to work on the project in our busy lives. Many of us are students or working full-time jobs, so it can be difficult to find time to work on the project. This was especially challenging because we are in different time zones, which made it harder to coordinate and communicate with each other.
Another challenge that we faced while building Librum was the difficulty of generating high-quality images from older public-domain texts. The dataset that the AI text-to-image generation model was trained on more modern prose, so trying to generate images with older prose prompts can produce less desirable results. To address this challenge, we implemented a significant data pre-processing step to bias the model toward generating higher-quality images from older texts. This involved carefully selecting and preparing the data to ensure that the model was able to generate the best possible results. Additionally, we fine-tuned the model using a variety of techniques to further improve its performance on this specific task.
In addition to the challenges mentioned above, the team also faced challenges related to container security. Since most of the team was new to best practices in this area, we had to do a lot of research and learning in order to ensure that the application was secure. This involved exploring different container security options, implementing security measures, and exploring the Slim.AI platform. Overall, this required a significant amount of time and effort, but it was crucial to ensuring the security and stability of the Librum application.
Accomplishments that we're proud of
We are proud to have finished something to show! It is more difficult than we originally thought to come up with an idea, implement that idea, and have a working prototype to show the world! For many of us on the team, it's our first hackathon that we are submitting to DevPost.
We are also proud of the overall concept of Librum and its potential to make classic literature more accessible and engaging for modern audiences. We believe that our application has the potential to inspire a love of reading and help bring classic books to life for a new generation of readers.
What we learned
Through the process of building Librum, we learned a lot about AI text-to-image generation technology and the challenges of generating high-quality images from older texts. We also learned about the importance of container security and the various options available for securing applications. Additionally, we learned about the Slim.AI platform and how it can be used to build and deploy machine learning models.
Overall, we gained valuable experience working on a team, developing a concept from start to finish, and using cutting-edge technologies to create a functional prototype. We also learned a lot about ourselves and our abilities, and we are excited to continue learning and growing as developers.
What's next for Librum
The next steps for Librum would be to continue improving and expanding the features of the application. This could include allowing users to have their own libraries of processed books, adding more styles to choose from, and supporting more export formats such as ePub and Kindle. And potentially creating other types of visual aid like knowledge graphs for character relationships.
We could add features such as a gallery of processed books, the ability to upload and process books, and the ability to search for public-domain books. We could also explore the idea of a marketplace for AI-generated books, where users can share and vote on their collections of processed books.
Finally, we would focus on improving the user interface and overall user experience to make the Librum application even easier and more enjoyable to use.
Log in or sign up for Devpost to join the conversation.