-
Homepage
-

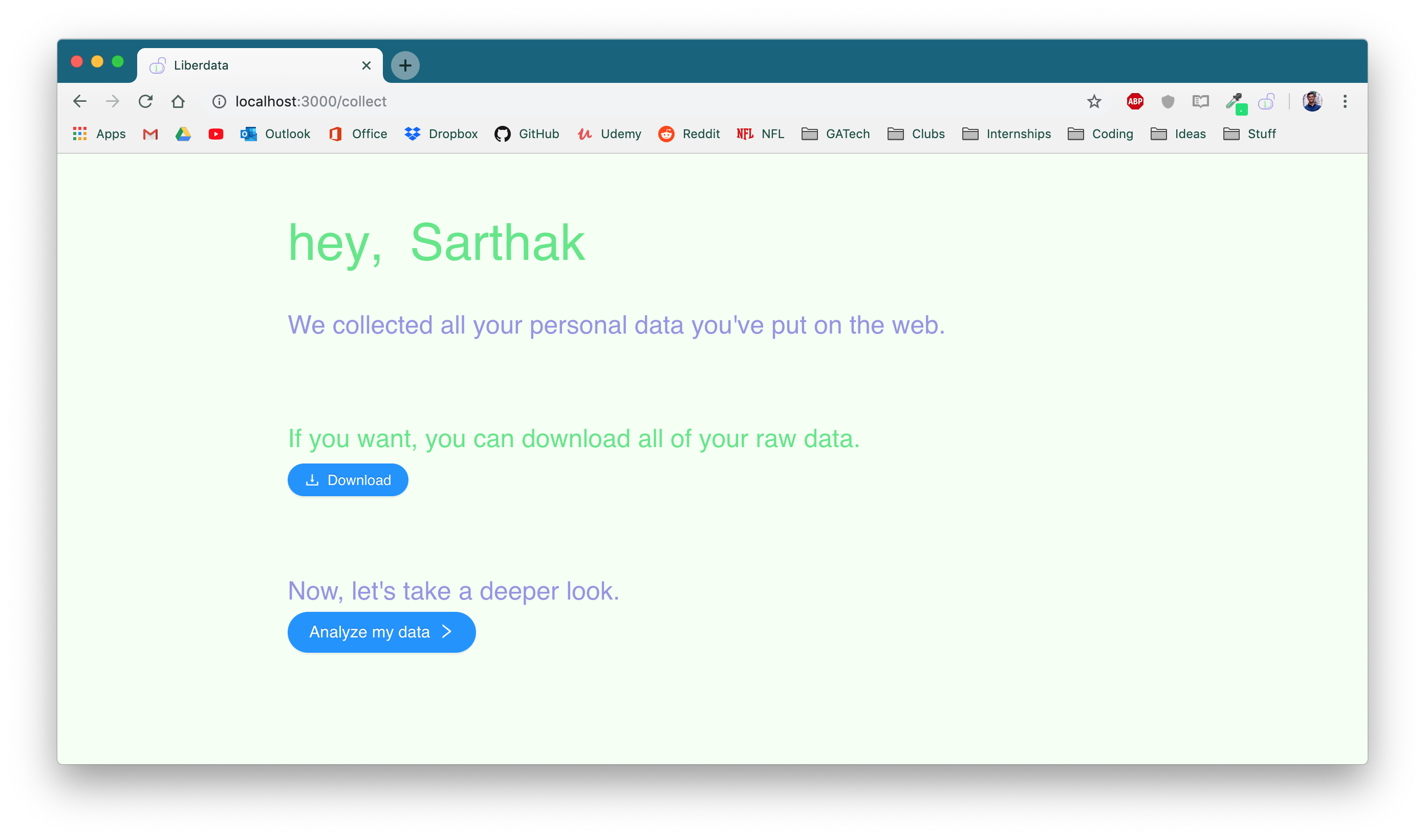
Collect raw data
-
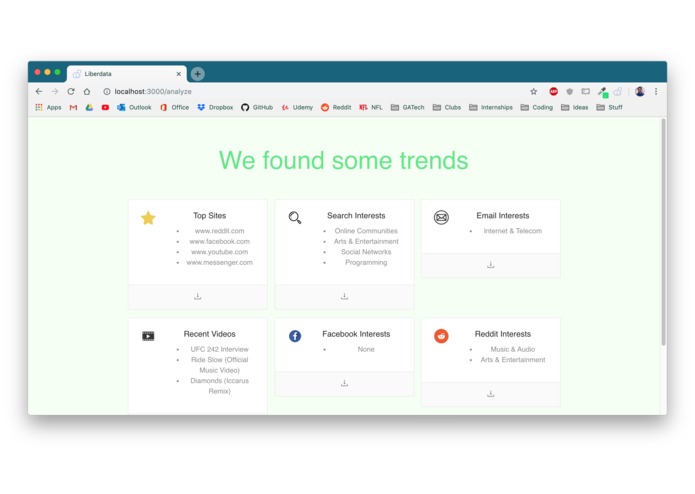
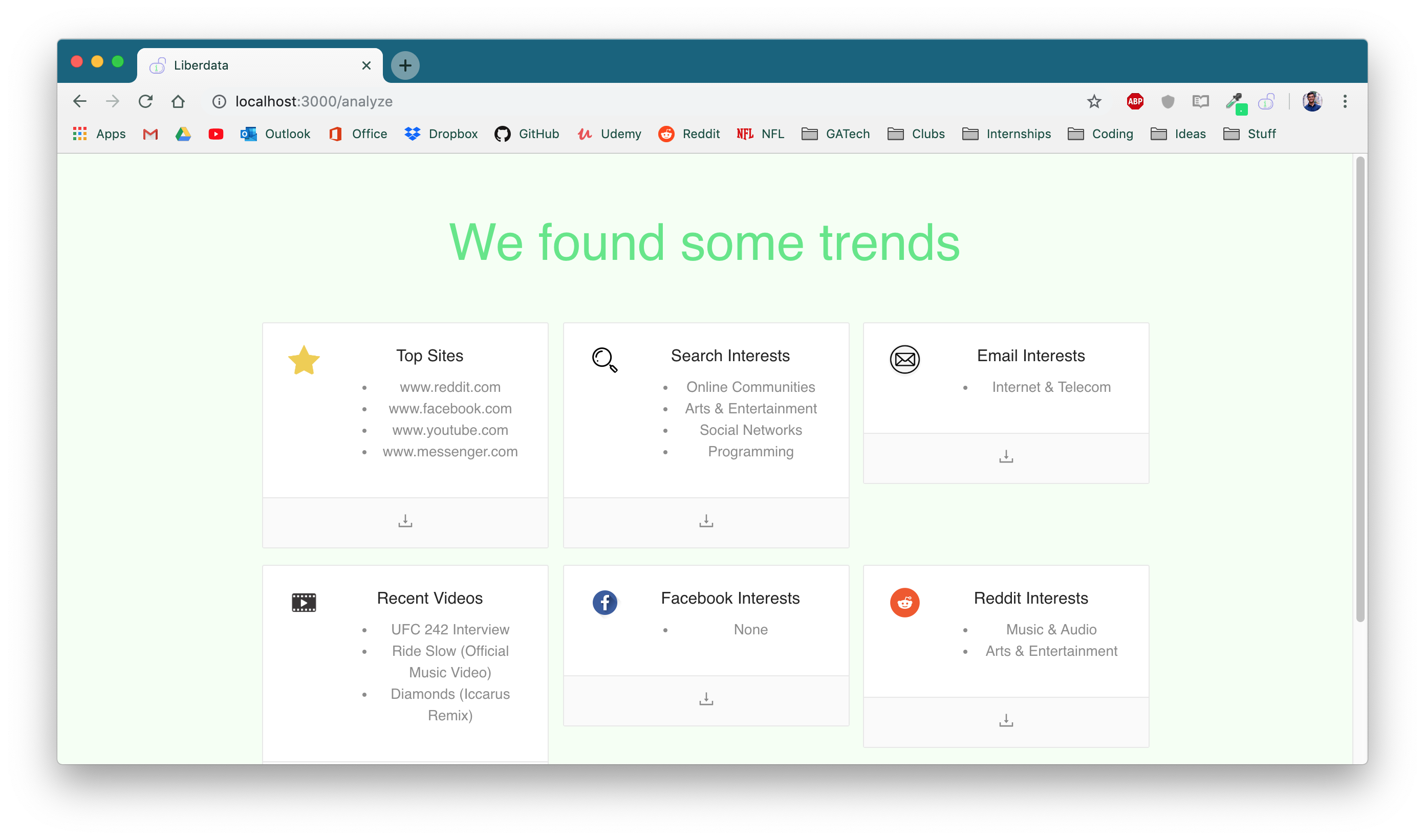
Analyze data with NLP
-
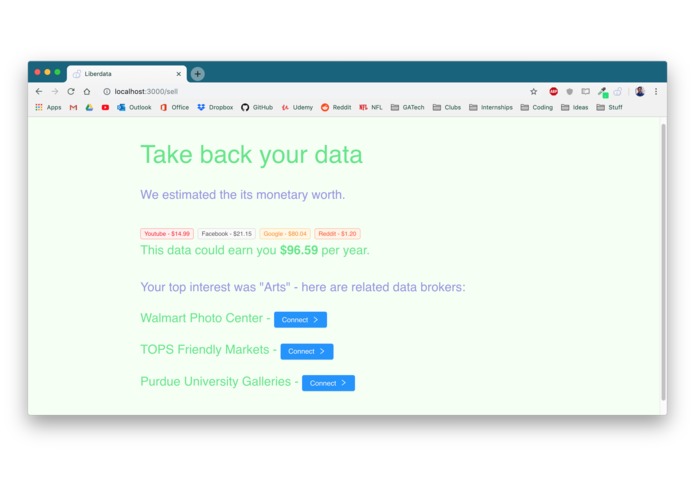
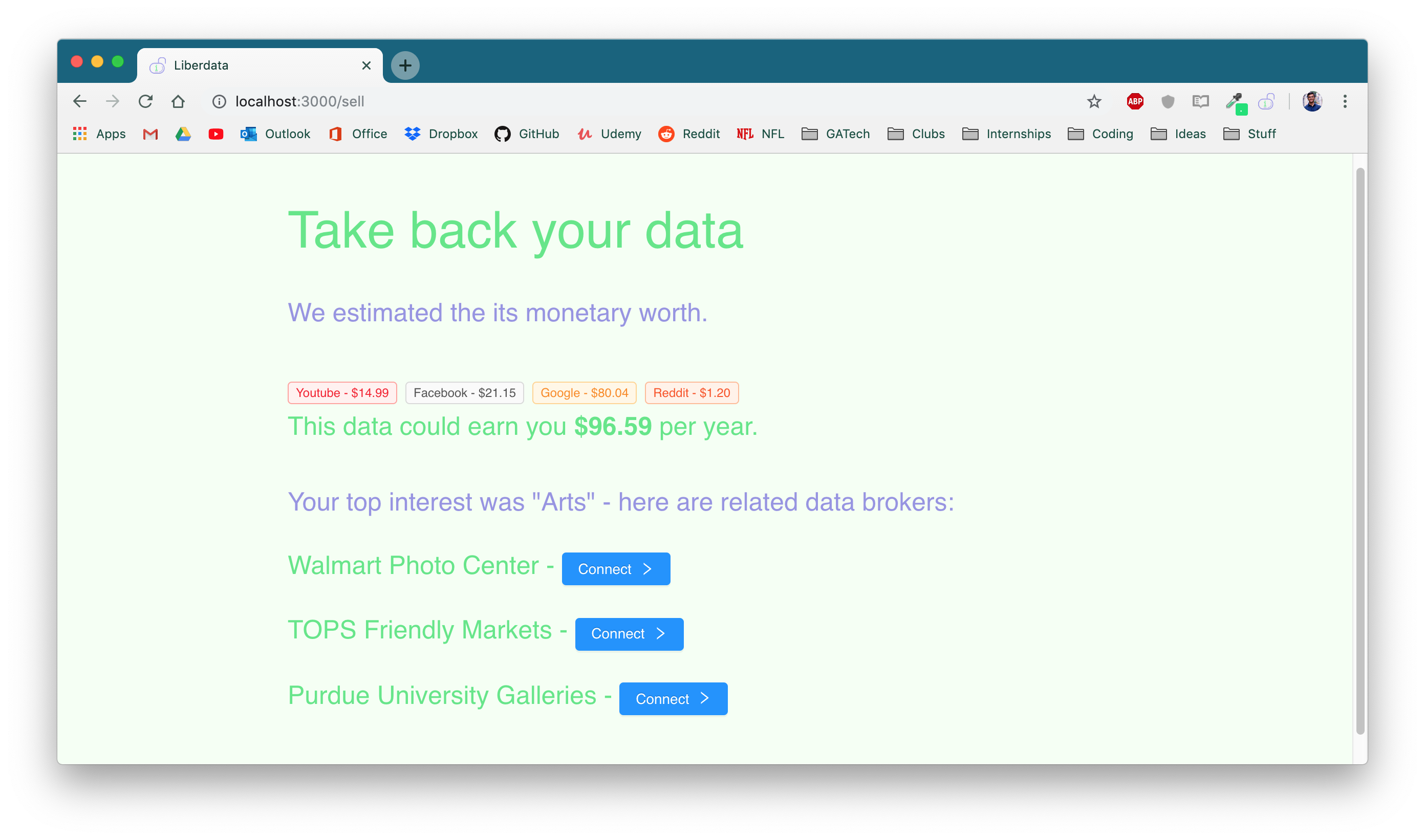
Calculate worth and pair with vendors
Inspiration
Your personal data is everywhere. Everyday, you make searches, browse websites, and enter information, all while leaving tidbits of your data scattered across the internet. Tech giants, like Amazon and Facebook, capitalize on this, by selling data you've left behind on their sites to data brokers, who use them for purposes such as targeted adds. Our goal is to completely disrupt this market. While we can't take this data away from these platforms, Liberdata strives to democratize personal data by letting people see what data they have out on the internet, and then sell it themselves.
What it does
Liberdata starts by using the user's credentials and local chrome data to collect the majority of their relevant personal data from the internet. This includes visited websites, google searches, emails, YouTube history, and even Facebook and Reddit activity. From there, we leveraged Google Cloud NLP programs to synthesize this data into common themes and interests. Both the raw data and the analysis is presented the user to provide them full knowledge of their online data. Finally, based on market research, we estimate the annual price the user could earn from their data and use the Capital One API to pair them with data brokers who match their top interest.
How we built it
The frontend is built in React. The backend is built in Express, Node, and Firebase. We used Google Cloud APIs for our NLP synthesis and Capital One APIs for our marketplace.
Challenges we ran into
We had some troubles pairing the frontend and backend which we troubleshooted using Postman.
Accomplishments that we're proud of
We're really proud of the idea itself honestly. We really believe this is something that's right for the common internet user, and we're glad we made a tangible hack about it.
What we learned
So much about API endpoints.
What's next for Liberdata
Flushing out our marketplace!








Log in or sign up for Devpost to join the conversation.