-
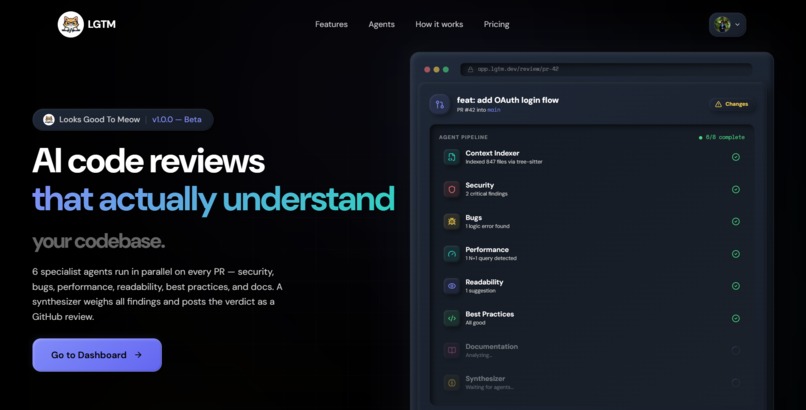
Home Page
-
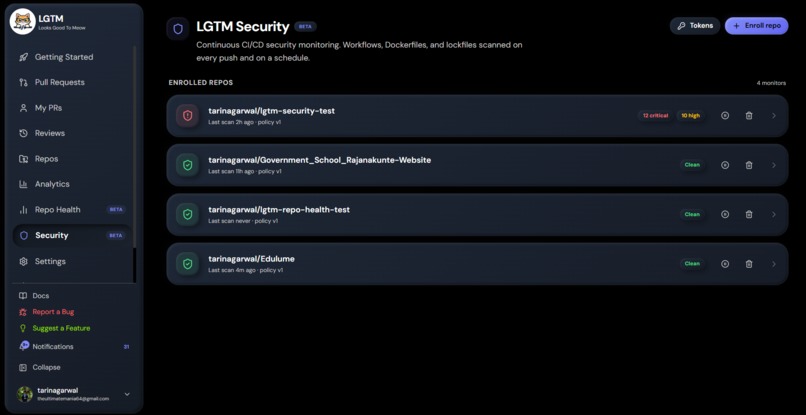
LGTM Security
-
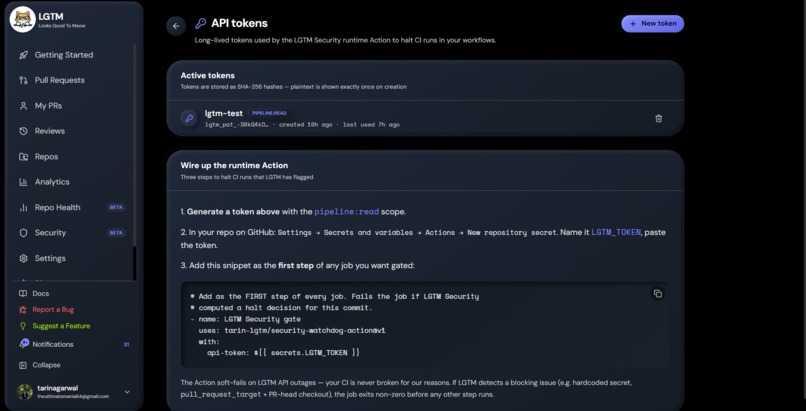
API Token for LGTM Security
-
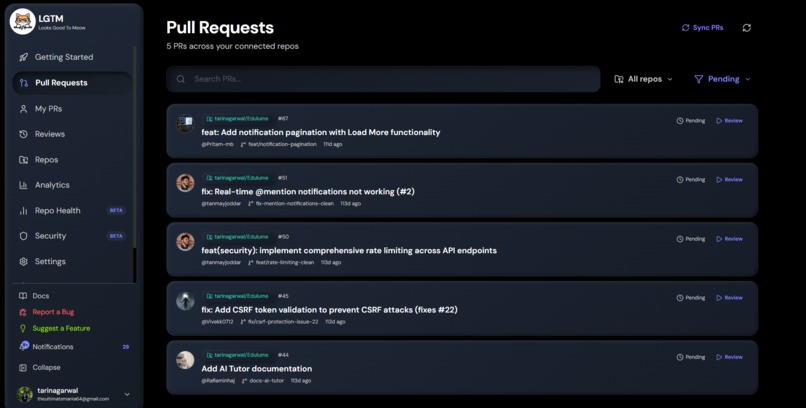
All PRs
-
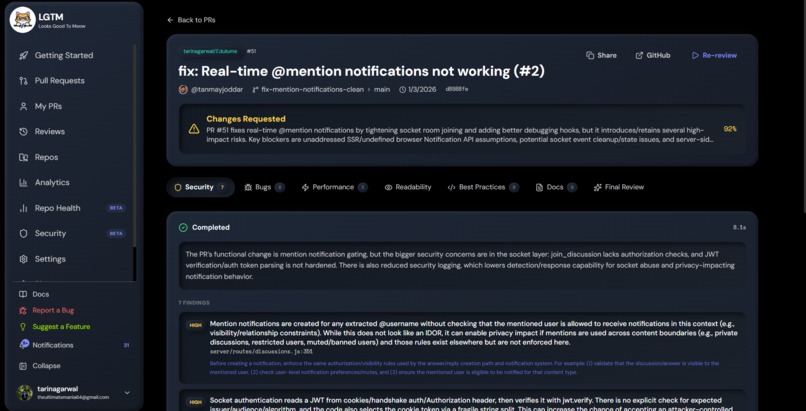
A review
-
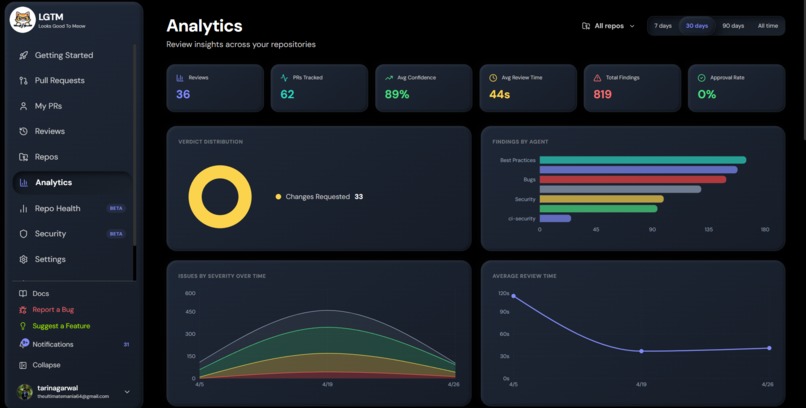
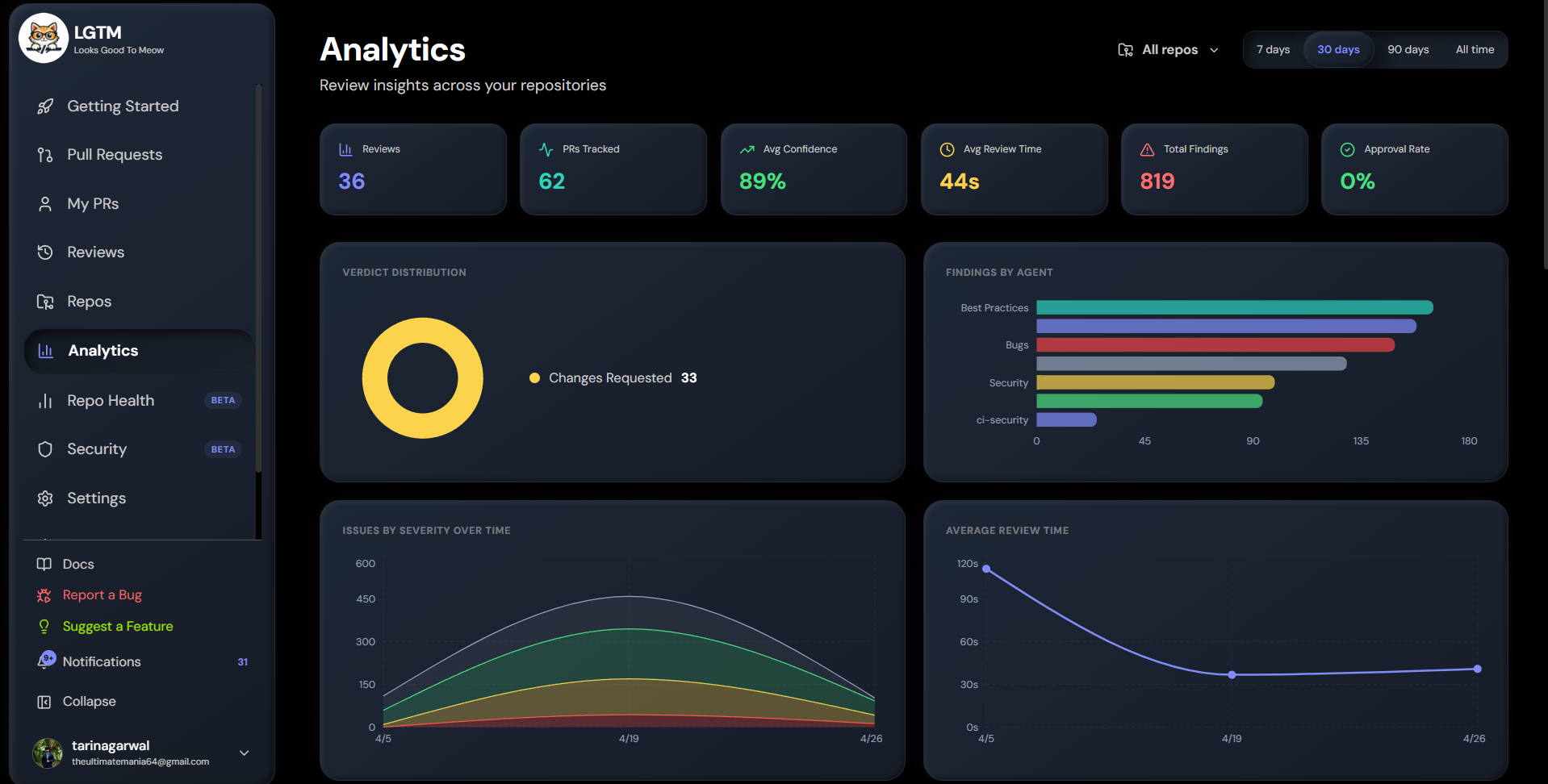
Analyticcs
-
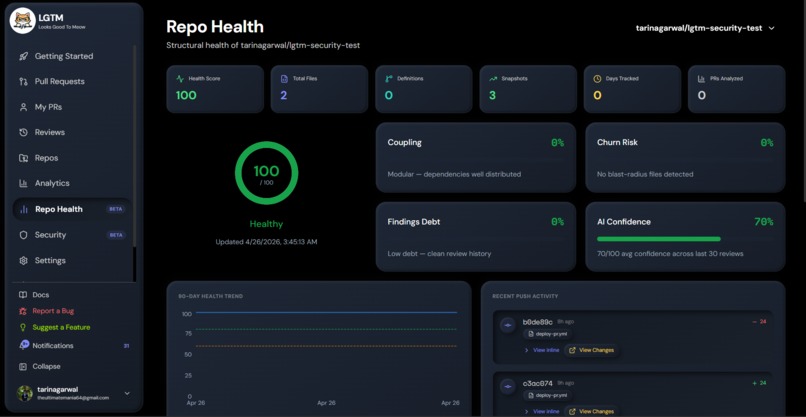
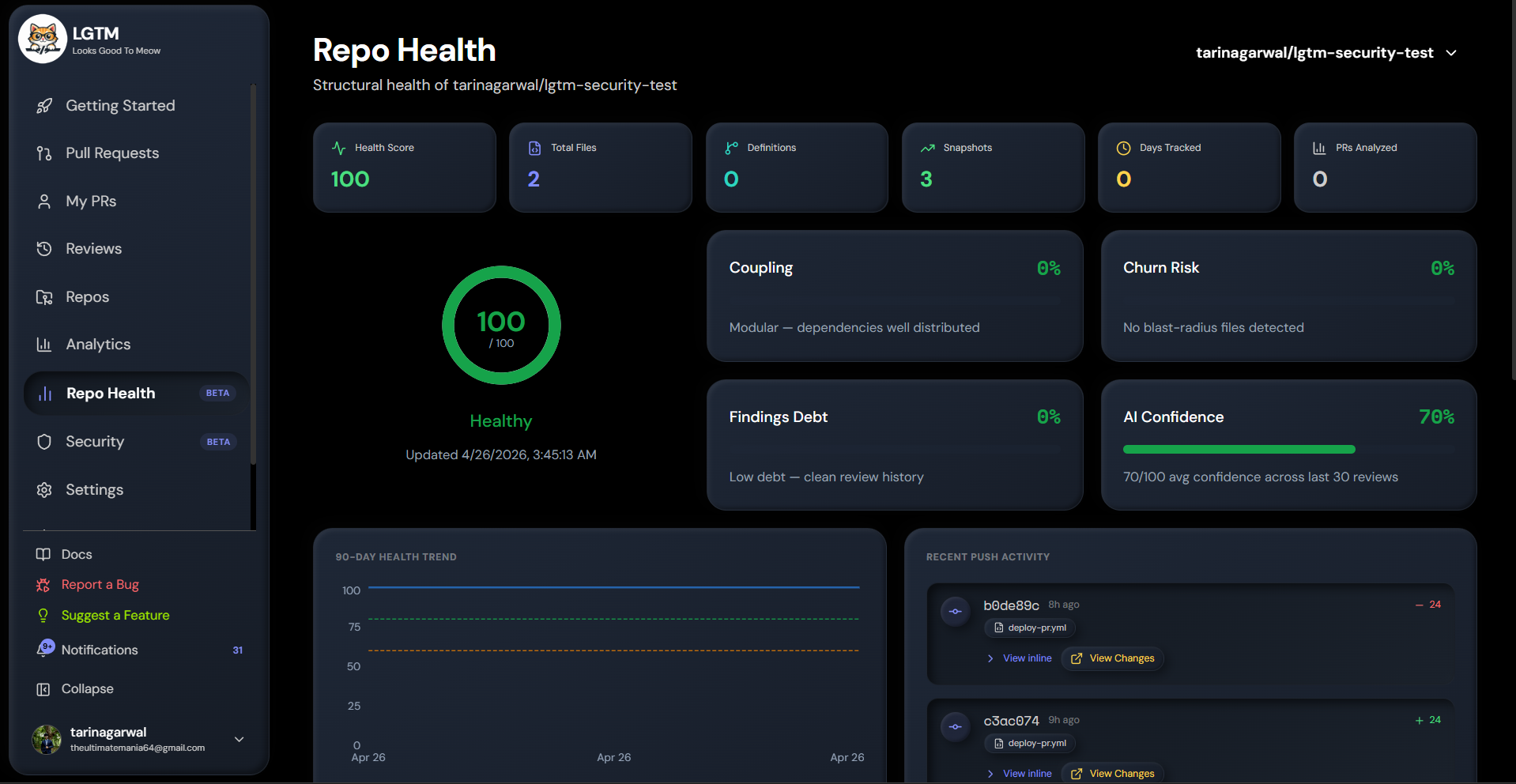
Repo Health
-
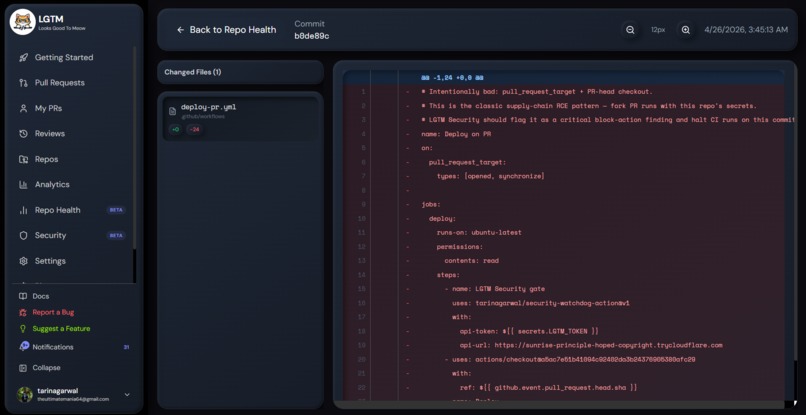
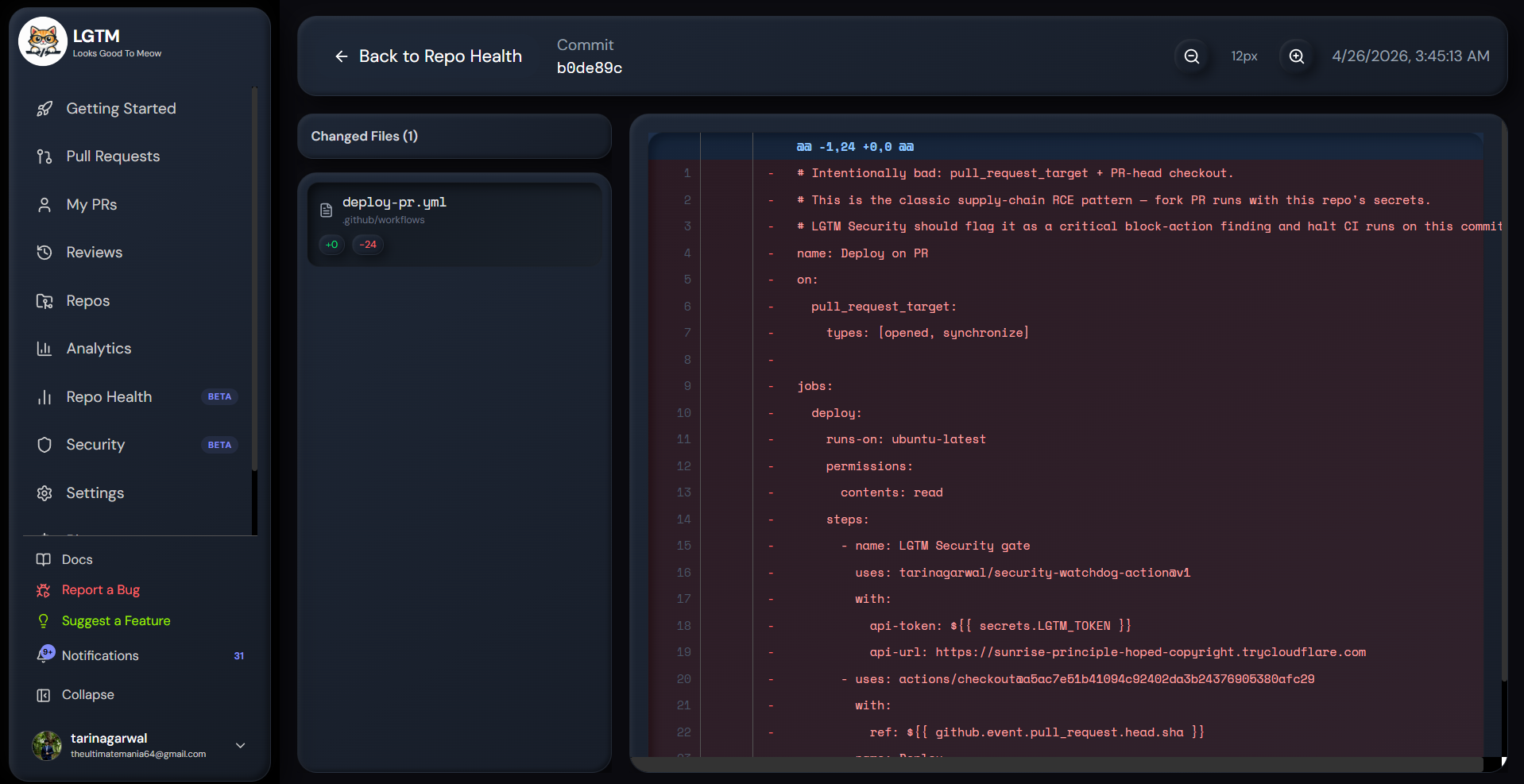
Diff Viewer in Repo Health
-
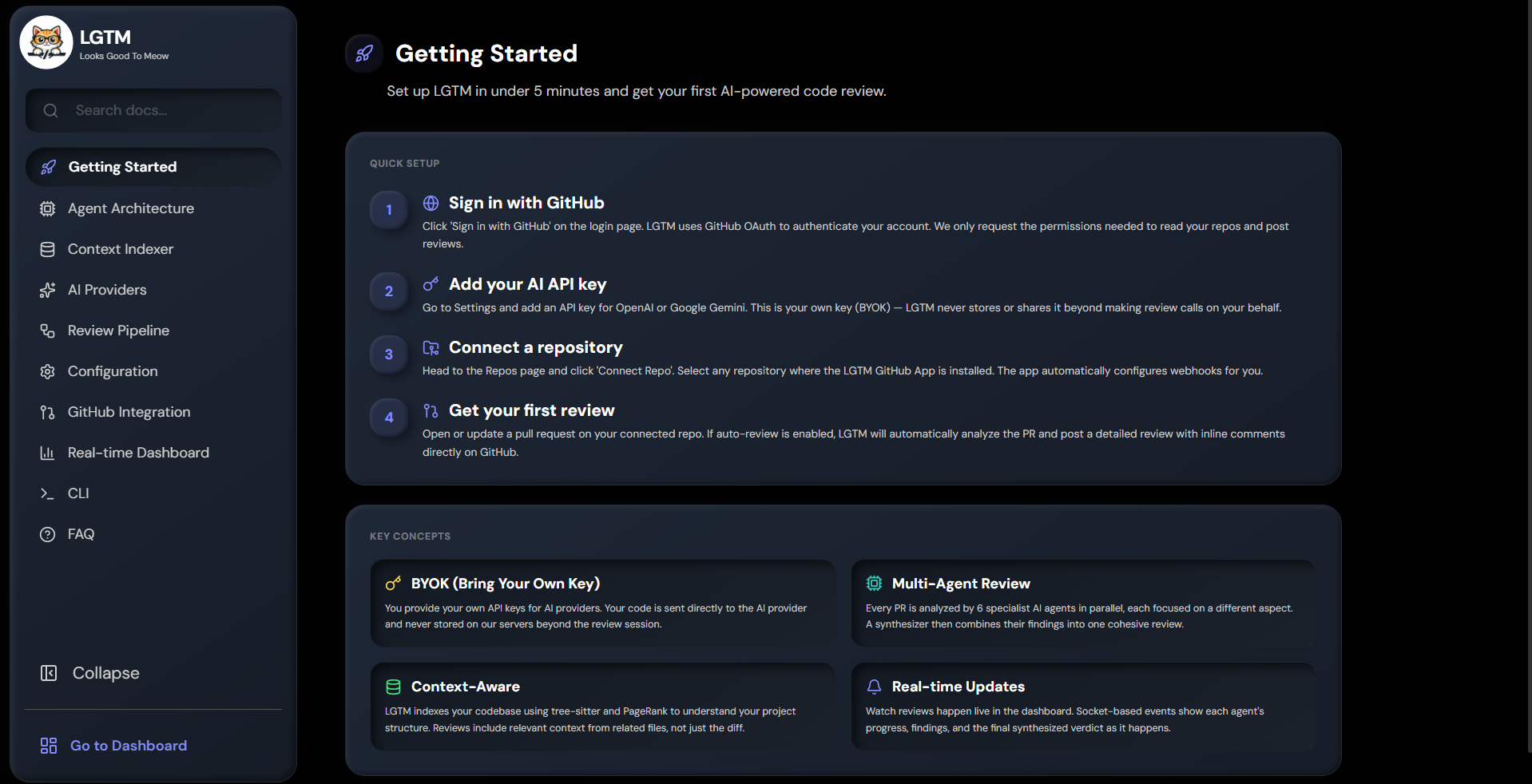
LGTM Docs
-
Repositories
-
Settings
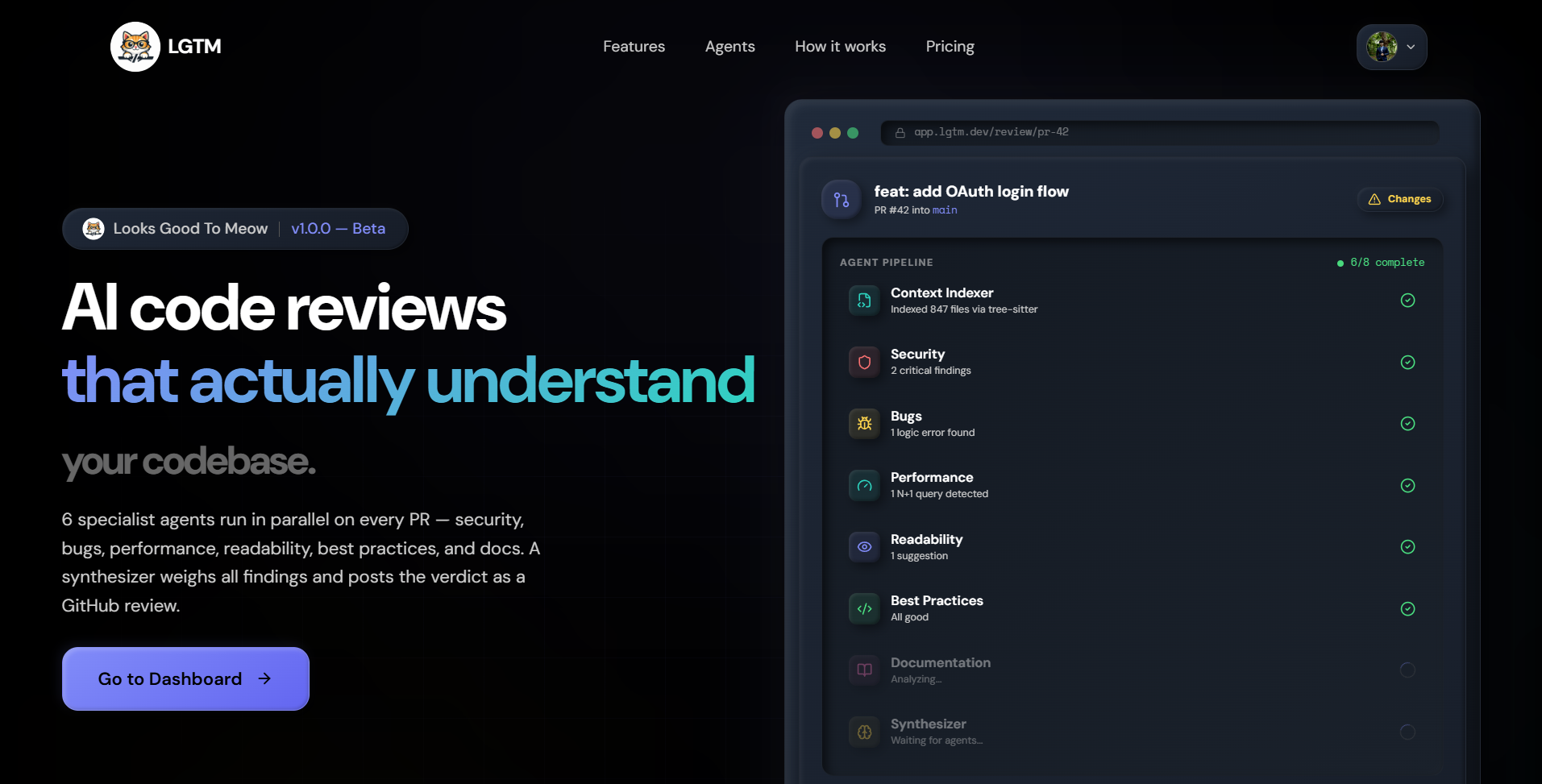
LGTM
Looks Good To Meow — code review and CI/CD security, before bad code merges and before bad pipelines run.
Inspiration
The idea came from being a maintainer on Edulume during SWOC (Social Winter of Code). Reviewing 80+ PRs from contributors I'd never met taught me two things very fast.
The first was that most "review feedback" is the same feedback over and over. "You forgot to handle the empty state." "This useState is going to cause a re-render loop." "Why is your AWS key in this commit?" After about week three, I started writing the same five comments on autopilot. That's when it hit me that almost none of what I was doing actually needed me — it needed someone, but not specifically me.
The second was scarier. A contributor opened a PR that added a workflow file with pull_request_target and a checkout of the PR head. If I'd merged it without thinking, any future fork PR could've run arbitrary code on our runner with our repo's secrets. I caught it because I'd seen that exact pattern in a security writeup the week before. Pure luck. I started wondering how many of these I hadn't caught — and how many other maintainers were missing them.
So LGTM started as "what if a bot did the boring 80% of review for me." But the part that made it actually worth building was the security half — the stuff a tired maintainer at 1am will miss every time.
What it does
Two surfaces, one product.
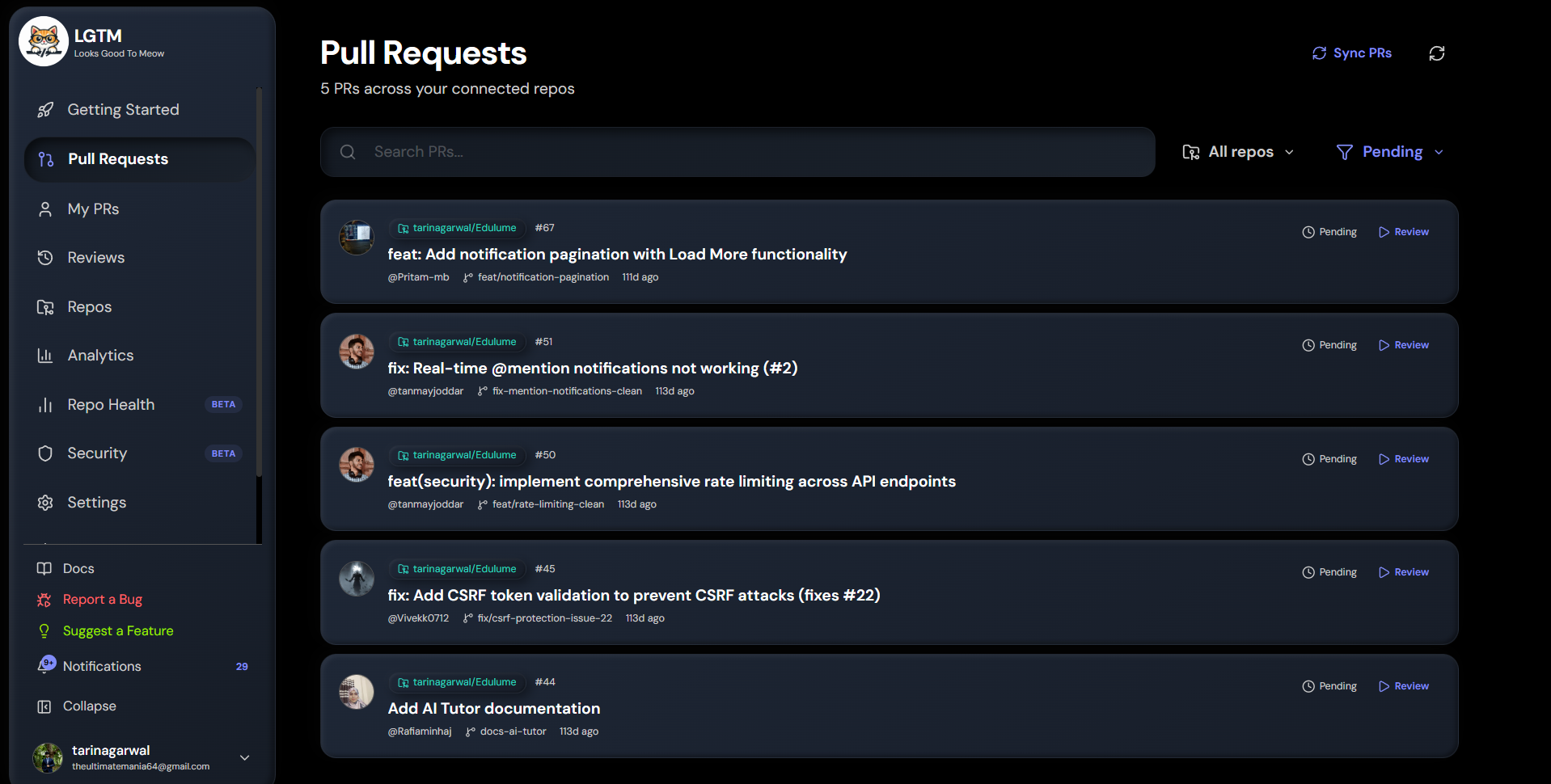
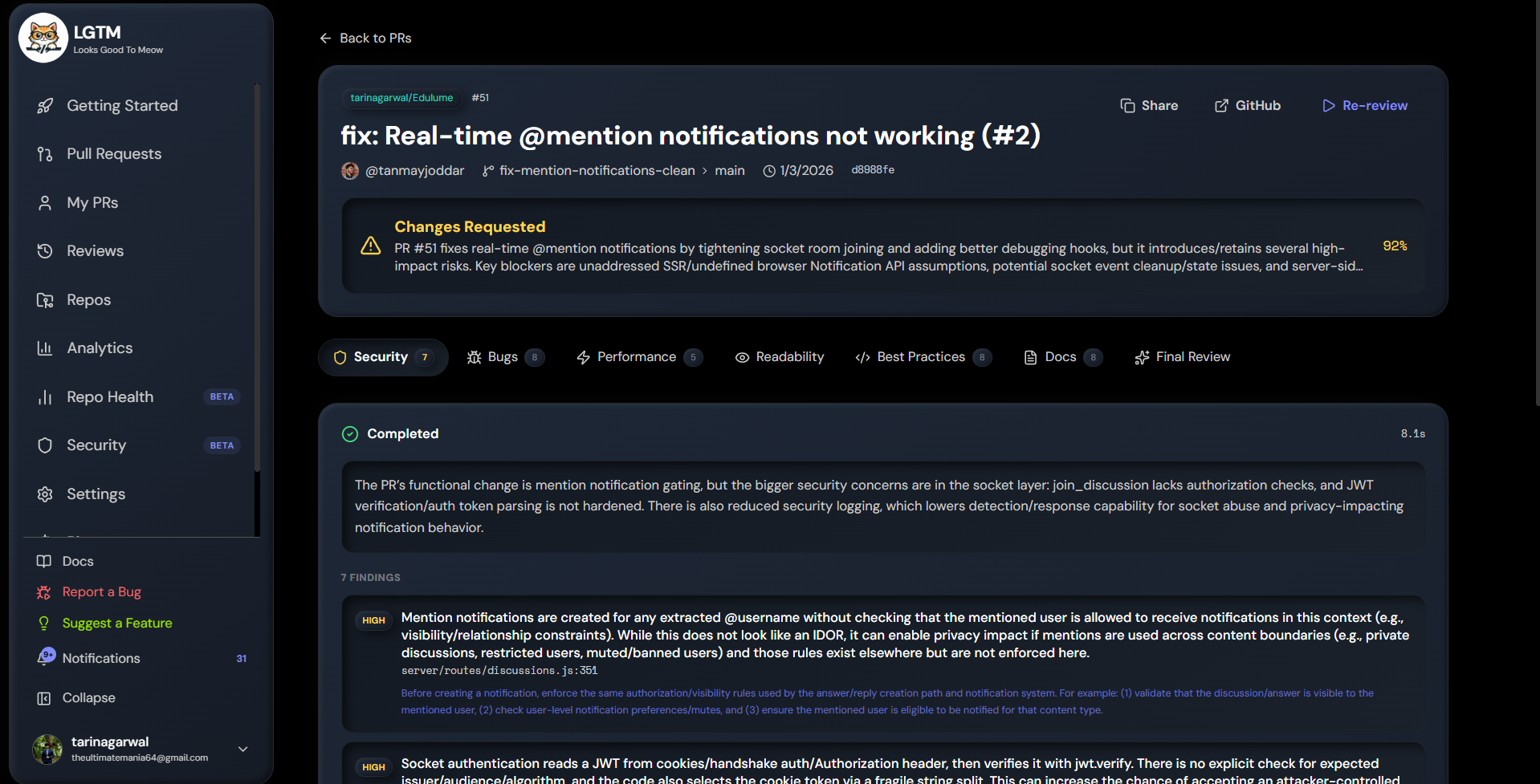
Code review. Connect a GitHub repo, open a PR, and within 30 seconds you get a review with inline comments from six specialist agents — security, bugs, performance, readability, best practices, documentation. They run in parallel, then a synthesizer agent combines their findings into a single verdict (approve / request changes / comment) and posts it to GitHub like a human would. You bring your own OpenAI or Gemini key.
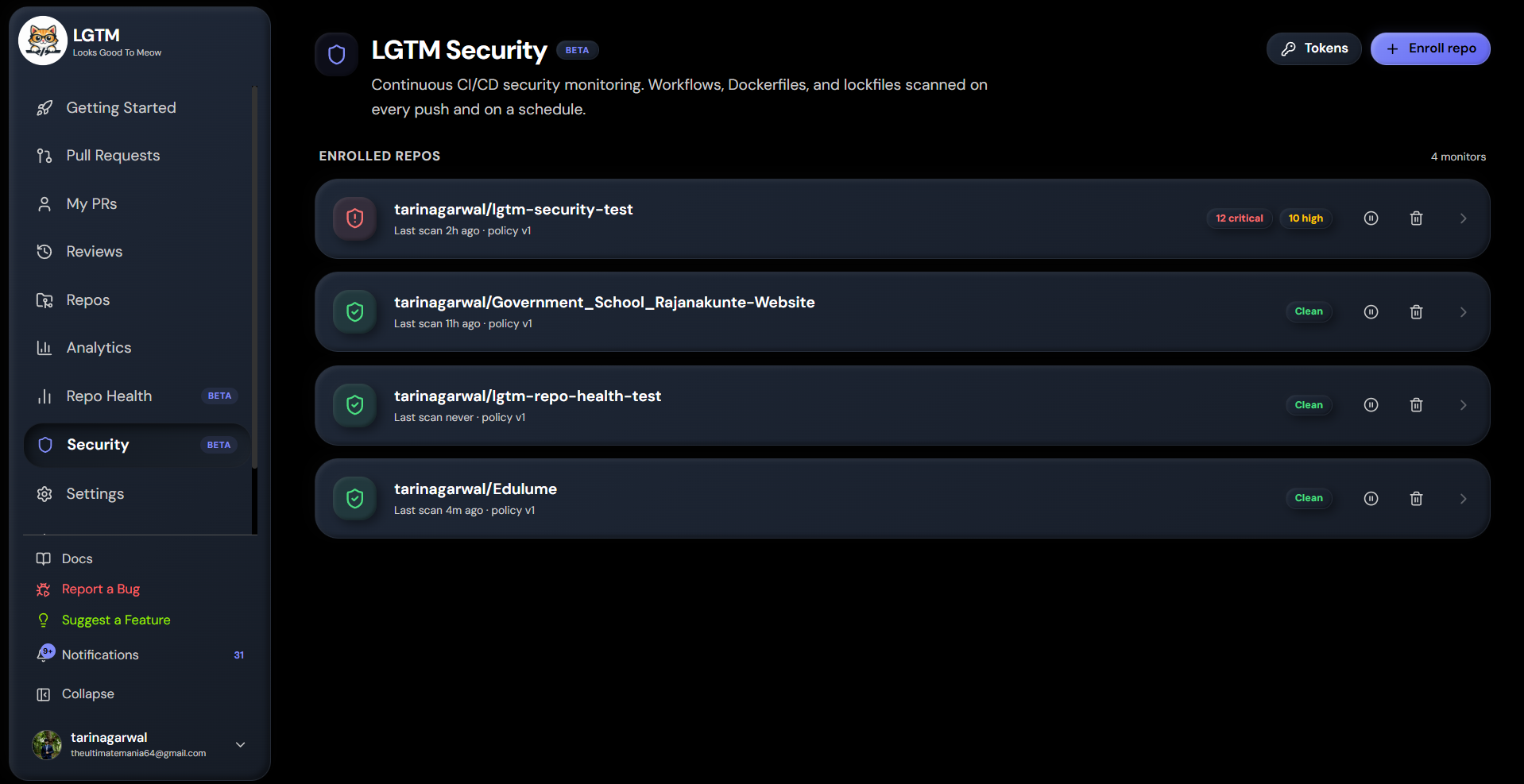
LGTM Security — the part I'm most proud of. A separate product surface inside the same dashboard for catching the things that aren't really "code review" but absolutely matter:
- Hardcoded secrets in workflow files, Dockerfiles, anywhere they shouldn't be.
pull_request_target+ PR-head checkout — the supply-chain RCE pattern.- Privileged containers, untrusted PR titles being interpolated into shell commands,
permissions: write-all, self-hosted runners exposed to fork PRs, unpinned third-party actions, lockfile-only edits, outbound network calls to non-allowlisted domains, and several more.
LGTM Security has three enforcement gates that all share the same rule library:
- Inline review — when a PR touches CI/CD config, the findings appear in the PR review next to the regular code-review comments.
- Merge block — a GitHub Check Run failure for any block-action finding. If the repo has branch protection requiring "LGTM Security" to pass, the merge button greys out.
- Pipeline halt — a separate GitHub Action customers add to their workflows. It runs as the first step of every job, calls our API to ask "is this commit safe to run?", and exits non-zero before any other step runs if the answer is no. This catches the cases branch protection doesn't — direct pushes to main, scheduled cron runs, tag-triggered deploys.
Per-repo policy: each rule can be set to block, warn, or off. Per-repo allowlists for trusted action sources, internal mirror domains, and runner labels. False-positive rates surface in the policy editor so you can mute genuinely noisy rules with evidence, not vibes. Email + in-app alerts when new blocking issues land.
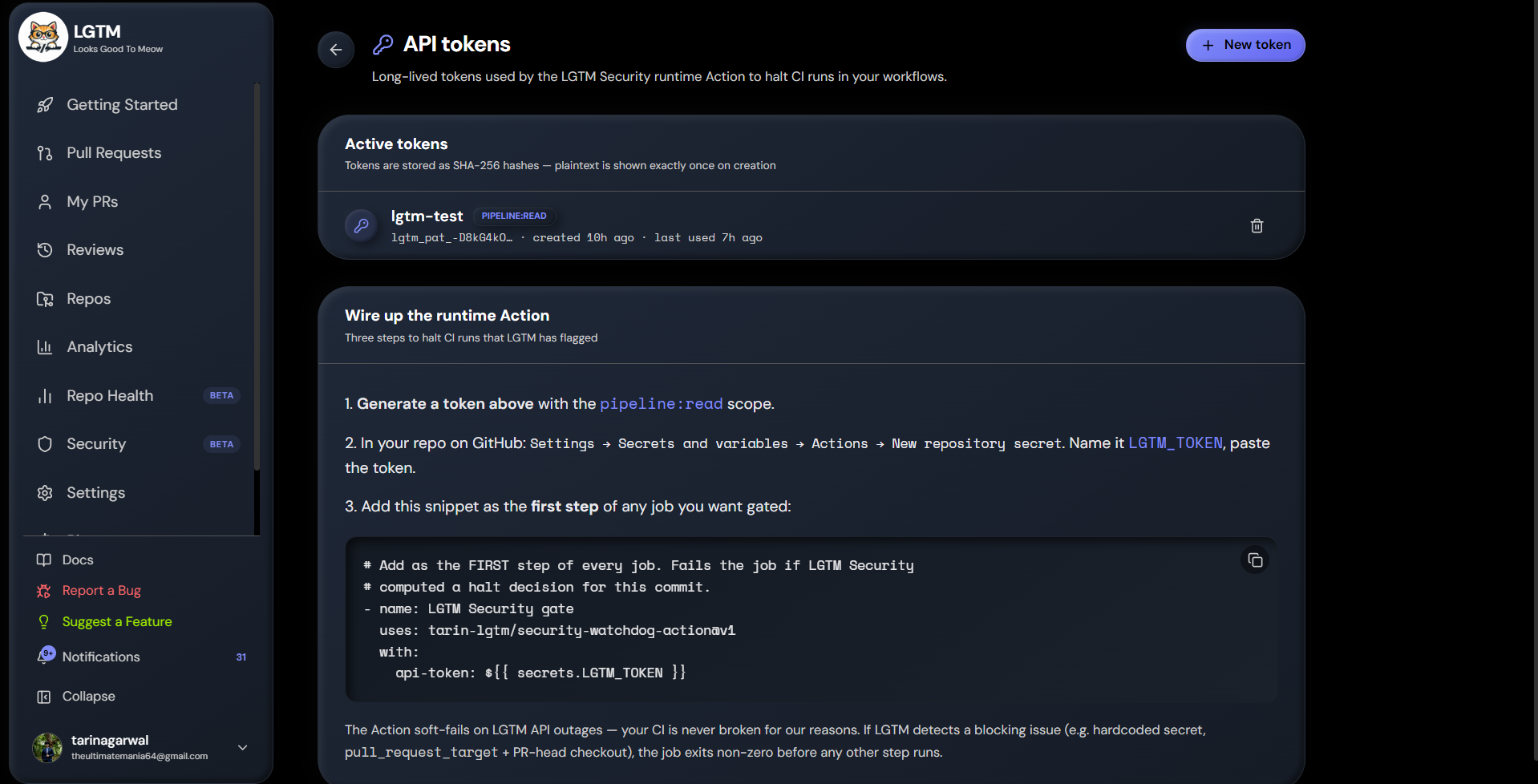
There's also a CLI (lgtm review) for reviewing local diffs before you push, a runtime watchdog Action published as a real GitHub Action you can uses: from any workflow, and an audit log that's immutable at the schema level — the resolution fields are mutable so you can mark fixed/false-positive, but the finding itself can never be retroactively edited.
How we built it
Backend is Express + MongoDB + Redis. BullMQ for the queues — three of them: review jobs (PR-triggered), context indexing (tree-sitter parsing, dependency graphs, PageRank for relevance), and security scans (push-triggered, scheduled, manual). Workers can run inline with the API or split into a separate process for production. Socket.IO pushes live progress to the dashboard so when a scan kicks off, you actually see it happening.
The rule library that powers LGTM Security is pure functions — no I/O, no DB, no LLM. 16 detectors written as plain TypeScript: regex pre-scans for secrets, YAML AST walks for workflow files, Dockerfile tokenizers, lockfile diffing. This was a deliberate choice — when LGTM tells you "this is a critical finding," that needs to be deterministic and reproducible. Same input, same output, every time. The exact same rule library is consumed by the PR-side agent and the monitor-side worker, so PR findings and scheduled-scan findings can never disagree.
The runtime halt Action is a small composite GitHub Action bundled with @vercel/ncc. It reads a halt decision from a Redis cache keyed by repo + commit SHA, with a 24-hour TTL. The cache is written by both the monitor worker and the PR review pipeline, so a commit's halt verdict travels with it regardless of which path computed it. The Action soft-fails on network errors by design — we never want LGTM going down to take customer CI down with it.
Frontend is React + Vite + Tailwind v4, with a custom claymorphism design system — chunky drop shadows, soft inset highlights, large radii. We built our own Select, Modal, Button, and SearchInput primitives because every native browser control would've broken the visual coherence.
Challenges we ran into
The race condition between push and CI start. When a developer pushes a commit, GitHub fires a push webhook to our server and starts the CI workflow on that same commit at the same instant. The runtime watchdog Action runs as the first step of CI and asks "do you have a halt decision for this commit?" — but we might still be scanning. The Action polls for up to 90 seconds. In production this is two HTTP round-trips before scan completion. We learned that "real-time" needs to be backed by polling for the cases your event system can't quite cover.
github.context.sha lies on pull_request events. Spent embarrassingly long on this. On pull_request events, GitHub injects a synthetic merge-commit SHA into the Action context — not the PR head SHA. Our halt cache was keyed by the head SHA the review job actually scanned, so the Action's lookups never matched and every PR was soft-passing. The fix was three lines but the diagnosis took an hour.
Silent failure cascades. Early on, if our GitHub Check Run API call failed (App permission gap, transient 5xx), the entire downstream chain — audit log persist, halt cache write, scan completion — got skipped because they were all nested inside the same try/catch. PRs were producing valid findings that simply never made it to the database. The fix was splitting each side-effect into its own independent try block. Lesson: best-effort means best-effort, not "best-effort if everything else also worked."
Stale state across review reruns. When you re-run a review on the same PR, the same findings are produced again. Our first version of the audit log de-duplicated on insert, which seemed clean until we realized customers wanted to see "this finding has reappeared 3 times across 3 different commits" as a signal that the contributor isn't fixing it. So now every detection is its own row, dedup happens at read time, and resolution is a separate concern.
Tailwind v4's important syntax. This is dumb but real. We had buttons collapsing into invisible nubs across the security pages because we'd written p-2! (the v4 canonical form) but our older Button component still used !p-2 internally, and the two clashed. The fix was a sweep across six files. The lesson: when you upgrade major versions of a styling system, do it on a separate branch and run actual visual diffs.
Accomplishments that we're proud of
The end-to-end halt loop actually works. We ran an aggressive test against 8 PRs, each adding a different bad pattern. All 8 hit the exact rule we expected. The 4 with block-action findings had their CI jobs halted at step 1 — before checkout, before tests, before deploys could run. The 4 warn-action ones surfaced findings without blocking. The clean control passed cleanly. End-to-end, with the runtime Action calling our API through a public tunnel and hitting Redis. Watching that work for the first time was the best moment of the build.
The rule library is something we'd genuinely use in our own projects. The pull_request_target rule, the shell-injection rule, the privileged-container rule — these aren't theoretical. They're patterns that have caused real breaches at real companies, written down as detectors that fire in under 50ms per file.
The improved suggestions ship the user's actual code back at them. When the rule fires on ref: ${{ github.event.pull_request.head.sha }}, the suggestion echoes that exact line and shows two refactor options (switch to pull_request, or keep pull_request_target but drop the head checkout) as copy-pasteable code blocks. Most security tools tell you what's wrong and walk away. We try to tell you what to do next.
The whole feature is auditable. Every finding is an immutable row with provenance — which rule, which detector (regex / YAML AST / Dockerfile / lockfile), which scan, which PR, which commit. Resolution is mutable but tracked. If a customer's compliance team asks "show me everything we caught and how we resolved it," the answer is one CSV export.
What we learned
If you can make something deterministic, do — even if an LLM is shinier. The PR review agents use LLMs because the input is open-ended source code. But every CI/CD security rule we wrote runs without an LLM, because workflow YAML and Dockerfiles are structured, and the bad patterns are well-known. Determinism means reproducibility, audit trails that mean something, sub-second scans, and zero per-finding cost. The LLM only earned its place where the alternatives didn't exist.
Side effects don't compose for free. The clean way to add "post a Check Run + write audit log + cache halt decision" is three independent try blocks, not one big one. Every time we coupled them, one of them failed, the others got dropped, and we found out days later by looking at empty tables. Decoupling looks like more code; it isn't.
A second product surface is sometimes the right call. We could've shoved CI/CD security into the existing PR review pipeline as just another agent. Initially we did. But security people don't think in PRs — they think in posture, audit logs, and policy. Giving them a dedicated tab that shares infrastructure with the review side but presents differently turned out to be the move that made the feature actually demoable. The architectural overhead was worth it.
The halt cache is the spine of the runtime feature. One Redis key — pipeline:decision:{repoId}:{sha} — written by the monitor worker, the PR review pipeline, and the runtime Action through a single endpoint. Three components, one source of truth. Most of the bugs we shipped during development were "this third place wasn't writing to the cache." Once we fixed all three, the feature stayed fixed.
What's next for LGTM
Auto-fix PRs. When a finding has a deterministic fix (pin this action to a SHA, replace ${{ github.event.pull_request.title }} with an env-var passthrough), open a PR with the fix already applied. We deliberately deferred this because the blast radius is real — but it's the obvious next step.
Per-rule false-positive learning across customers. Right now FP rates are computed per-repo. If a rule is consistently false-positive across many customers, we should be downgrading its default action, not just letting each customer independently mute it.
Org-level enrollment. A single click that enrolls every repo in a GitHub org, with org-level posture rollups in the dashboard. The data model is already future-compatible.
More detector breadth. Kubernetes manifests (privileged pods, hostPath mounts), Terraform (publicly exposed S3 buckets, default-deny missing), package-manager post-install scripts. Each of these is its own well-known class of supply-chain risk, and the rule library design makes adding them a one-file change.
A self-hostable build. Right now LGTM Security is SaaS only. A docker-compose with the worker, server, MongoDB, and Redis would let regulated customers run it inside their own VPC. The architecture already supports it; we just haven't packaged it.
Built With
- fastify
- gemini
- github-jobs
- google-cloud
- mongodb
- node.js
- openai
- react
- tree-sitter

Log in or sign up for Devpost to join the conversation.