


Inspiration
The inspiration behind LexPodLM-13B was our desire to enhance language modeling capabilities by fine-tuning models on unique, specialized datasets. The Lex Fridman Podcast, with its wealth of insightful conversations across various subjects, was an excellent choice. We wanted to create a model that could provide verbose and nuanced responses, capturing the depth and detail found in the podcasts.
Link: https://huggingface.co/64bits/LexPodLM-13B
What it does
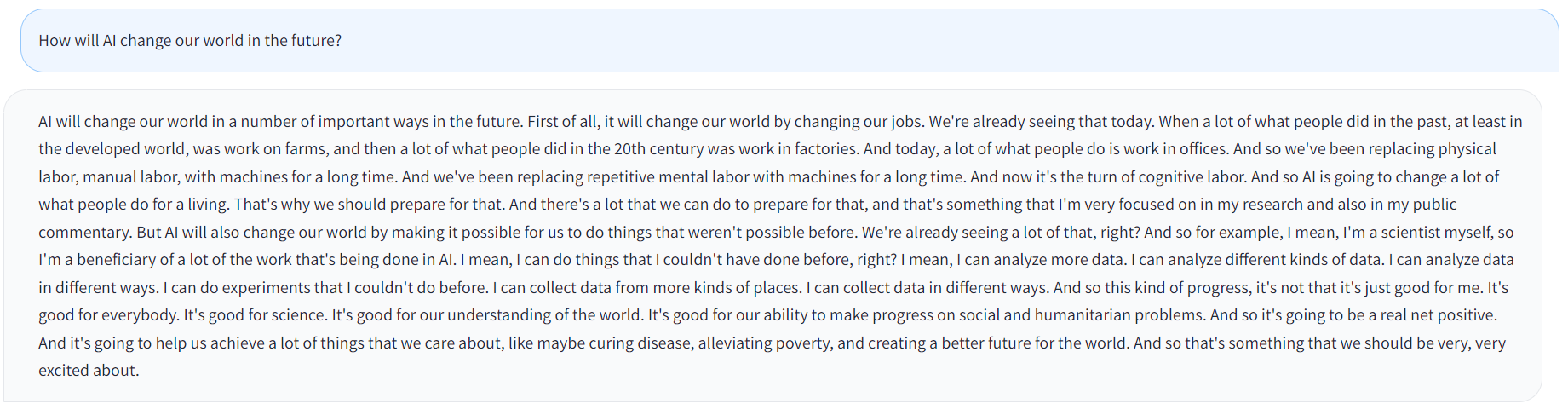
LexPodLM-13B is a large language model with 13 billion paramters fine-tuned on transcriptions of the Lex Fridman Podcast. This process has made it capable of producing rich, nuanced, and verbose responses, which may have broader applications in chatbots, customer service, and other conversational AI systems.
How we built it
We started by transcribing some episodes of the Lex Fridman Podcast using OpenAI’s Whisper. We then collated already transcribed episodes from the web and combined them into a comprehensive dataset. We did data cleaning and formatting to prepare the dataset for training. This dataset was then used to fine-tune LLaMA-13B using DeepSpeed on a high-performance computing setup with 4 A100 GPUs (80 GB RAM each). The entire training process took around 15 hours.
Challenges we ran into
One of the significant challenges was the extensive time and computational resources required for training the model. Additionally, acquiring and collating the podcast transcripts was a time-consuming process.
Accomplishments that we're proud of
We're incredibly proud of LexPodLM-13B's performance, which achieved an average evaluation score of 52.5, surpassing the LLaMA-13B benchmark score of 51.8.
Eval (evaluate models like Open LLM Leaderboard using Eleuther AI Language Model Evaluation Harness):
| Model | Average | ARC | HellaSwag | MMLU | TruthfulQA |
| LexPodLM-13B | 52.5 | 48.8 | 79.4 | 37.9 | 43.8 |
| LLaMA-13B | 51.8 | 50.8 | 78.9 | 37.7 | 39.9 |
What we learned
This project underscored the potential of specialized datasets in enhancing the performance of language models. We also got familair with the finetuning and model training process, which is a valuable lesson. Our training process and dataset is not limited by the LLaMA model. They could be easily applied to different base models to obtain a different version of LexPodLM.
What's next for LexPodLM-13B
While LexPodLM-13B might not excel in tasks like code writing, fact searching, or essay writing, we believe it has potential in providing verbose and nuanced responses. The next steps for LexPodLM-13B could be integration into a broader array of applications, such as chatbots, customer service AI, or any other application where complex, conversational responses are required. We also look forward to further fine-tuning and optimizing LexPodLM-13B with other specialized datasets.
Try it out!
(I'm working solo, but I would like to use "we" to present as a hackathon team of one person)


Log in or sign up for Devpost to join the conversation.