Inspiration
We wanted to make language-learning faster, more omnipresent, and a less burdensome process, so we built lexi to automate the web for you so you can focus on your everyday internet use instead of the barriers to language learning. The English lexicon is different for everyone. We aimed to provide a novel and efficient personalized language-learning for anyone browsing the Internet. That meant providing an application for both experienced and new English speakers alike, and not getting in the way of your normal browsing experience.
What it does
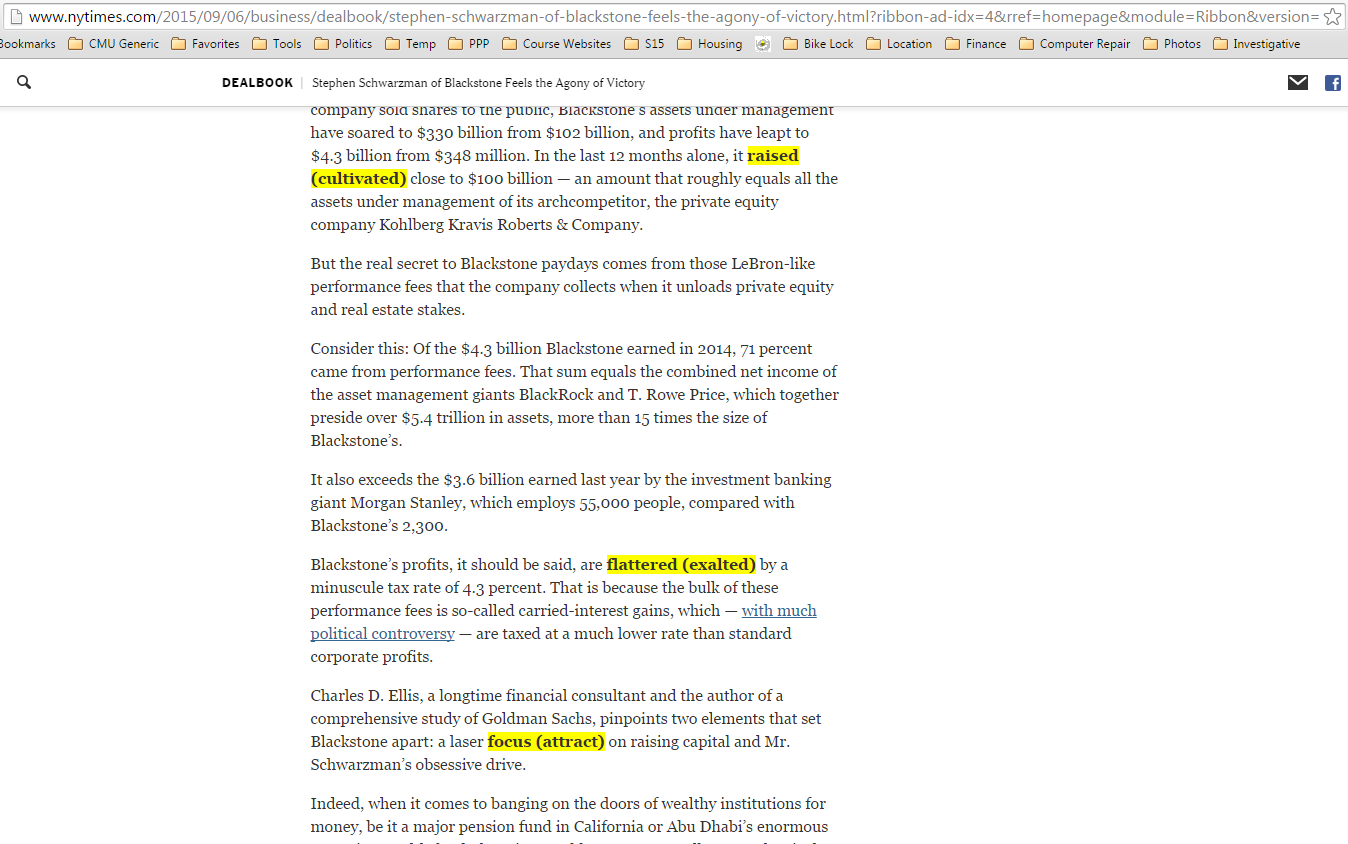
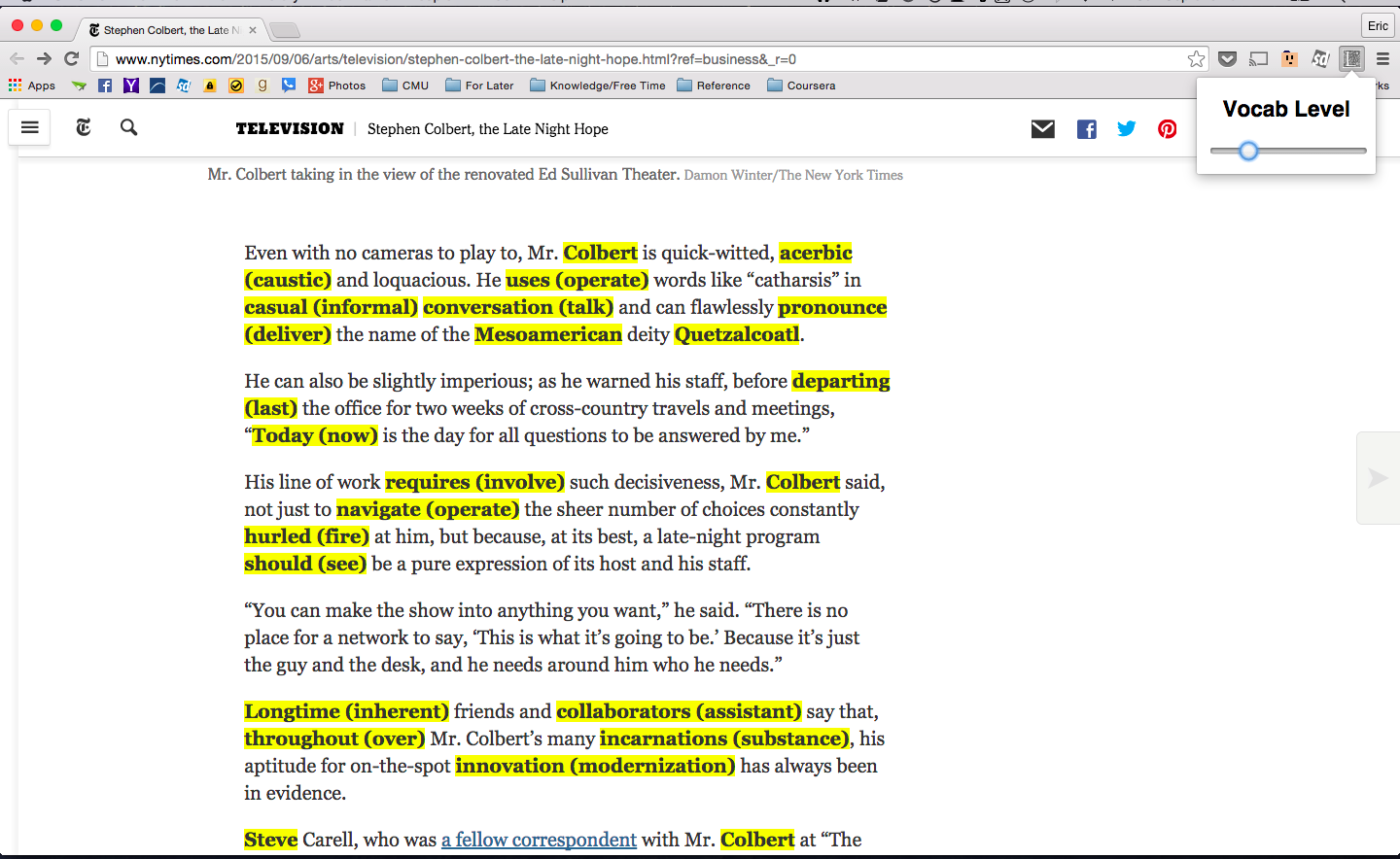
lexi knows the words you don’t. It instantly turns your daily Internet browsing into a personalized language-learning experience. It doesn’t matter if you already speak English or not: lexi will calibrate to the words you need.
lexi works by highlighting the words on a webpage that it thinks you don’t know and then providing synonyms on the page in unobtrusive parentheses. It provides a sliding scale to instantly adjust both the words it predicts and your proficiency level.
How we built it
The back-end of lexi runs on a blazing-fast Microsoft Azure server, with Node.js set up to provide optimal performance. Word difficulties, synonyms, and definitions are retrieved from a third-party service using an API we built and are then cached both locally and on our server to ensure high performance and availability, even in the face of a potential third-party outage. This API is then utilised by a Google Chrome extension which compares the words on the user’s web page to the user’s personal difficulty level to determine which words will require clarification and inserts helpful synonyms in parentheses. We further boost performance by filtering each request to avoid re-fetching words that have already been cached in Chrome local storage.
Challenges we ran into
Scraping all the plaintext from the DOM of an arbitrary website proved to be quite difficult. Every website is unique in its design, but we still managed to build a robust parser from the ground up to handle this challenge.
Another significant challenge was improving lexi’s speed to the point where users could seamlessly integrate lexi into their reading experience.
Finally, we found that there was a lack of API’s for analyzing word difficulty level. To compensate for this gap, we ended up building our own system to retrieve difficulty ratings from a live website and provide them in an easy-to-parse format.
Accomplishments that we're proud of
Creating our own api for our lexical queries.
Building a fast backend that takes advantage of parallelism and caching.
Optimizing our algorithm to extract plaintext from an arbitrary website through applying techniques like binary search.
Scalable and modular software design
What we learned
Parsing of complex website structures to allow seamlessly inserting and removing content without breaking the page
Caching both local and server-side to improve performance.
Building chrome extensions
What's next for lexi
In the next version, lexi will seamlessly handle translations between multiple languages, to help people who are learning a foreign language other than English. We will also continue working to make lexi more accurate, more responsive, and more predictive. This may be done by computing our own difficulty ratings for words by analyzing word frequencies on Wikipedia and other common domains, as well as aggregate reading patterns for lexi users. Furthermore, we will give users the ability to provide feedback to lexi, training lexi to be even more personalized and accurate.



Log in or sign up for Devpost to join the conversation.