-
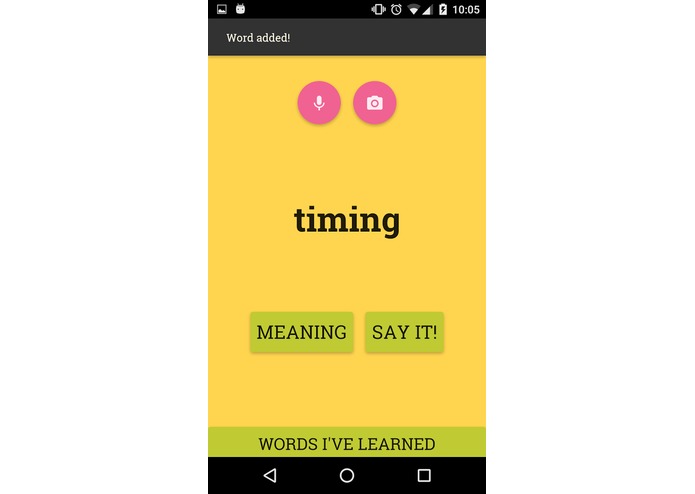
Word
-
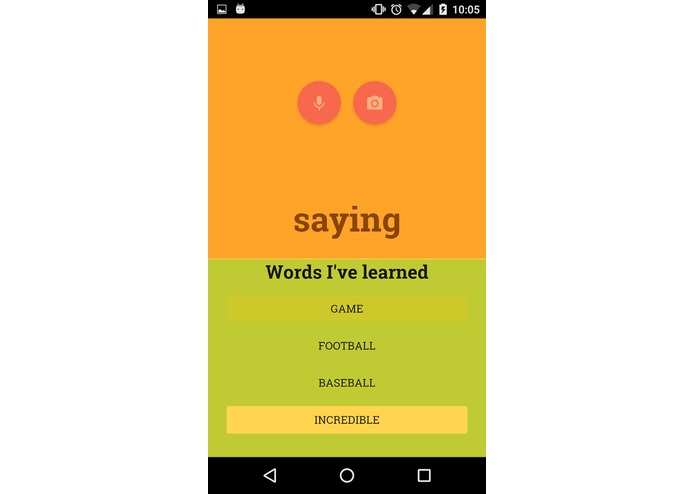
Interesting Saved Words
-
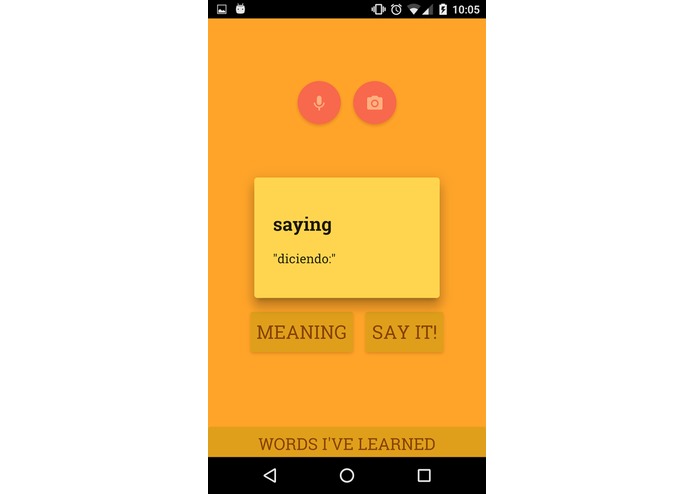
Translation
-
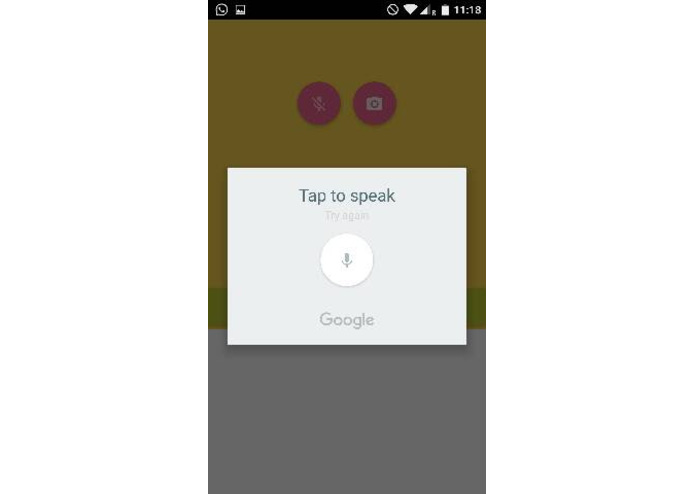
Speak Recognition




Inspiration
Our team is formed by two members from Cambridge University and two members from Politechnic University of Catalonia, located in Barcelona. We first met in Slack with the aim of making an application or utility related to Machine Learning and Big Data. We quickly organized ourselves and made a Trello board and posted our ideas and possible tools/libraries to use in the hackathon. When we met in Cambridge, the day before the show, we thought that the best thing to build would be a learning application that takes advantage of Big Data and Machine Learning to recommend words that the user might be interested in learning.
What it does
Our application is based on widely known utilities like Duo Lingo that aim to help the user to learn vocabulary in foireign languages. The essential difference is that our app accurately predicts what the user needs to learn according to what they currently know, conversations they have with other people, and photographies that the user has taken (e.g. when reading a sign). Thanks to our word predictor, the voice speech recogniser and the image caption system* we are able to predict with a great degree of accuracy relevant unknown words for the user.
*The image recognition system is not fully implemented.
How we built it ? by typing letters using a keyboard?
The architechture consists of separate backends and a single frontend (“the application”). One backend is in charge of the Big Data and Machine Learning recommendation system. It’s entirelly written from scratch in Python and receives data from a Flask-based REST API. The recommendations are sent back to the other backend, which is further described below.
The second backend ensures that everything is wired together and that both the frontend and the recommendation system receive consistent data. This backend is essentially a Node.js REST API supported by a Mongo database that saves some of the data sent by the user.
Challenges we ran into
None of the members of our team had worked on a project of this size in a previous hackathon. Hence at the beginning we were a bit scared of the scale of things. However, we quickly managed to get a basic prototype working; then we were able to add some extra functionality, such as a voice recognition module and the ability to read words using the camera. The most challenging part, however, was building an stable front-end with AngularJS and getting it working on an Android application.
Accomplishments that we're proud of
We are proud of having managed to build two servers (wow!), one with Nodejs and the other with Flask for different purposes. The Machine Learning part was really impressive and AngularJS was just awsome and easy to get it working. We are really happy that we finished a really decent application with real uses in the real world.
What we learned
We learn lots of new things! Angularjs, Machine Learning, Flask.. and also improved on many others, like Node.js (the best programming language in the world :P)
What's next for LexicOh!
We would like to build a native Android application written in Java, as well a fully implemented image recognition system. Another amazing thing would be to build a proper user database with the chance of logging from other platforms like Google, Twitter, Github or Facebook. Also, getting data from the phone contacts and other applications (respecting the user’s privacy) to give even better predictions.






Log in or sign up for Devpost to join the conversation.