-
-
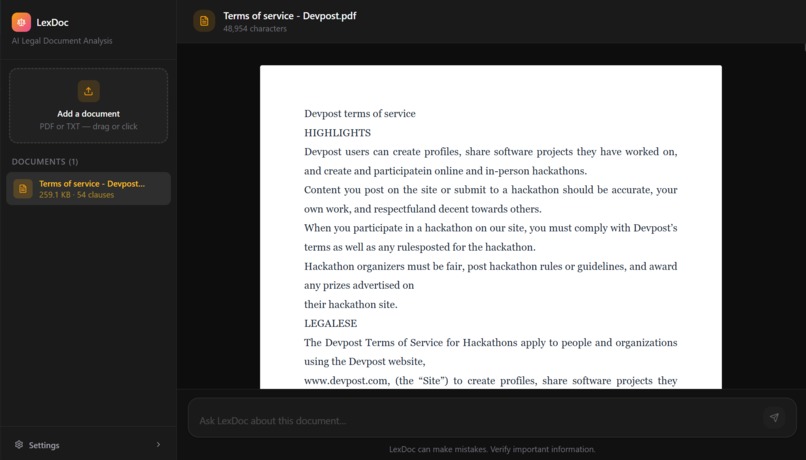
DevPost ToS
-
Home page
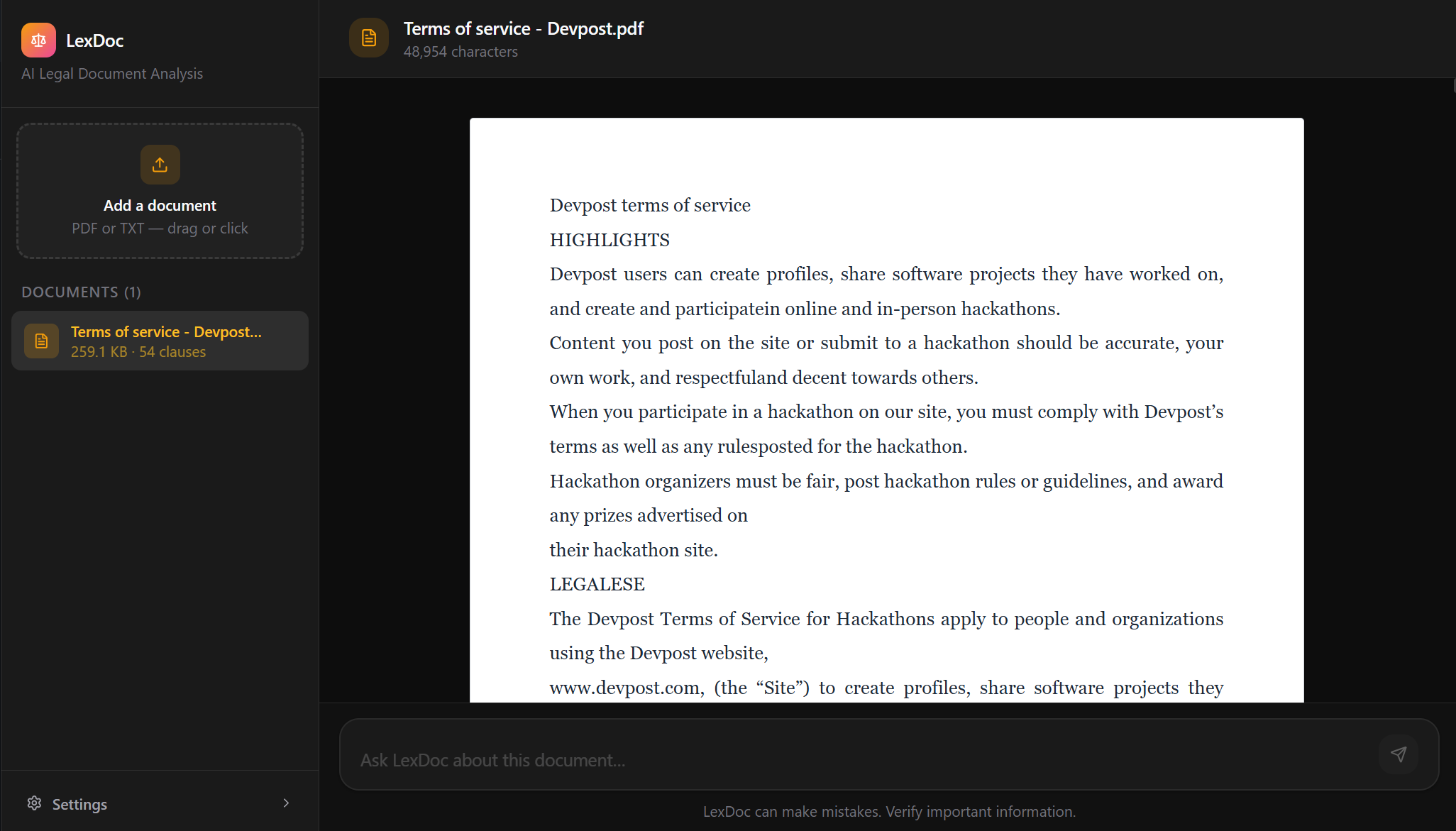
Inspiration
Legal documents are written by lawyers, for lawyers. But ordinary people sign them every day. Lease agreements, employment contracts, NDAs, loan terms. Nobody reads them properly because nobody can. We wanted to fix that. Not by simplifying the law, but by building something that could sit next to a contract and actually explain it to you in plain language, on demand.
What it does
You upload a PDF and it becomes something you can talk to. Ask a broad question like "what are my termination rights?" and LexDoc finds the relevant clauses and explains them. Highlight a specific paragraph and ask about it directly. The answers stream back in real time, and the interface shows you exactly what the system is doing at each step, whether it is searching the document, or just thinking through a general question. You always know where an answer came from.
How we built it
The frontend is Next.js on Vercel. The backend is Flask running in Docker on Render's free tier, which gives you 512 MB of RAM and not much else. We built a clause-aware document chunker that splits contracts along their natural structure: articles, sections, numbered clauses. Those chunks get embedded using Legal-BERT and stored in Milvus on Zilliz Cloud for vector search. Generation runs through Qwen2.5-72B. Both models run remotely on the HuggingFace Inference API. No GPU, no weights on disk, no memory pressure. The system is also agentic: before every query it decides whether the question actually needs document retrieval, or whether Qwen can just answer it directly.
Challenges we ran into
The first big wall was memory. We originally wanted to run Legal-BERT locally for embeddings. It worked fine on a laptop. On a 512 MB server it crashed on every single deploy. We moved all inference to remote APIs and our resident memory dropped from around 1.2 GB to about 80 MB.
Getting Legal-BERT to work as a proper encoder took some work. Out of the box it was not configured for feature extraction, so we had to optimize how we were calling it and how we handled the outputs to get clean, usable embeddings for retrieval.
The sneakiest problem was Milvus. Zilliz Cloud's free tier caps text fields at 8,192 UTF-8 bytes. Not characters. Bytes. Legal documents are full of curly quotes, section symbols, and other characters that take up two or three bytes each. We thought we were safely capping chunks at 6,000 characters. A chunk would hit 9,998 bytes and the entire upload would crash. It took a stack trace and some byte math to understand what was actually happening.
Accomplishments that we're proud of
Fitting a real RAG pipeline into 512 MB is something that genuinely surprised us. The whole backend, parsing, chunking, embedding, storing, retrieving, and streaming generation, runs on what most cloud platforms consider a throwaway free instance.
We are also happy with how the document itself looks. Uploaded PDFs render as clean, readable pages with proper typography and justified text. Highlighting a clause and asking a question about it feels natural. It does not feel like querying a database.
What we learned
The biggest lesson was to stop fighting infrastructure and work around it. Trying to run Legal-BERT locally cost us a lot of time. Once we accepted the memory constraint and moved to remote inference, everything got simpler and actually faster too.
We also learned that bytes and characters are very different things in production, and databases will remind you of that at the worst possible moment.
What's next for LexDoc
The next step is making the chunker byte-aware from the start, so the Milvus limit is never an issue regardless of what language or character set a document uses. After that, we want to add cross-document comparison, a clause risk-scoring pass that flags unusual or potentially unfavorable terms before you even start reading, and citation anchoring that jumps the PDF to the exact paragraph behind each answer.
Built With
- bert
- flask
- huggingface
- legalbert
- milvus
- next.js
- python
- qwen
- rag
- react.js
- render
- tailwind
- typescript
- vercel
- zilliz

Log in or sign up for Devpost to join the conversation.