-
-
-
280 datapoints
Leveraging LLMs for Assessing TikTok Reviews with RAG
This project focuses on automatically classifying reviews into four categories. Traditional machine learning approaches require large, pre-labeled datasets, which are difficult to obtain in real life. To overcome this, the project employs a Retrieval-Augmented Generation (RAG) systems combined with an ensemble of three language models (LLMs). This approach improves classification accuracy while remaining computationally efficient on a local machine.
Inspiration
Moderating reviews manually is time-consuming and prone to errors, especially when identifying spam, irrelevant content, or rants. Existing automated solutions, such as deep learning approaches, often require large labeled datasets, which are difficult to collect and annotate. This inspired us to explore LLMs and RAG for content classification, leveraging their ability to reason and generalize from a small number of examples. With Tracks 1 and 4 in mind, we also built a user-friendly UI for easy interaction.
Features and Functionality
Automatic Review Classification: The system classifies reviews into four categories: valid, advertisement, irrelevant, and rant_without_visit.
Rationale Generation: Each classification is accompanied by a rationale explaining why the review was categorized, providing transparency and insight into the decision-making process.
Local Deployment: Designed to run efficiently on standard hardware, using small LLMs for computational efficiency.
User Interface: Users can input reviews via a simple UI, making the system accessible for non-technical moderators or evaluators.
Retrieval-Augmented Generation (RAG): Enhances the LLMs’ ability to reason and generalize from limited data by retrieving relevant examples.
Ensemble Approach: Combines the predictions of three LLMs to reduce errors and improve classification performance
How we built it
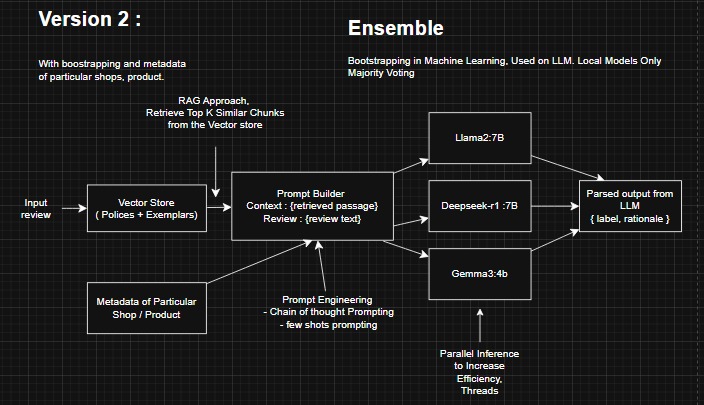
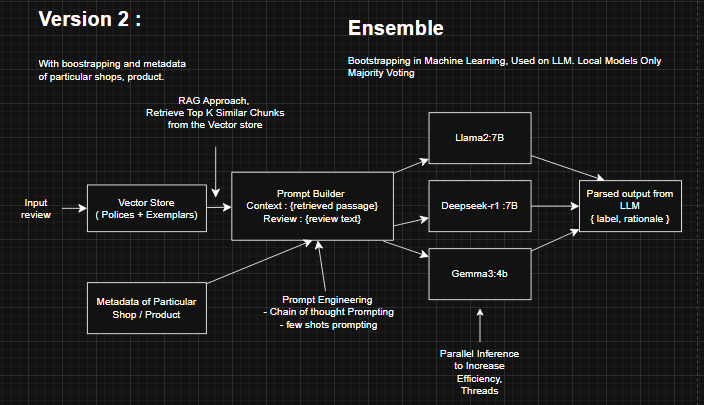
The project was broken down into three main parts. First, we implemented a RAG-based back-end, followed by an ensemble approach to improve classification accuracy. Finally, we connected the system to the Lynx interface through API calls.
RAG-Based Back-End: We created a vector store containing policies and examples of policy violations. When a review is submitted, the RAG system retrieves the top k relevant vectors to provide context for the LLM. Additionally, users can inject metadata about the business or shop into the query, giving the model more context to make accurate judgments. This approach improves the reasoning capability of the LLM and enables better classification decisions.
Ensemble Approach: To enhance reliability, we combine predictions from three differently pretrained LLMs using bootstrapping and majority voting. Bootstrapping is a simple yet powerful technique that allows us to leverage the strengths of all models without adding unnecessary complexity, improving the overall robustness of the classification pipeline.
Front-End Integration via API: Once classifications are made, results and rationales are sent through API calls to the web interface developed with Lynx. This provides users with a smooth, interactive experience to test and evaluate reviews using our system.
Challenges we ran into
- Limited Labelled data made traditional training difficult which forced us to find a alternative solution.
- Balancing performance and computational efficiency, with multi threading.
- Designing effective prompts to guide the models for accurate classification.
- Unfamiliarity with this specification of AI and Lynx as well provided a significant challenge.
Accomplishments that we're proud of
We successfully developed a system capable of accurately classifying reviews into four categories, even when using a relatively small dataset. This demonstrates that our approach can achieve high accuracy without relying on massive amounts of labeled data, which is often difficult and costly to obtain.
Our project also demonstrated that combining a Retrieval-Augmented Generation (RAG) system with an ensemble of multiple LLMs can significantly improve classification performance, leveraging the strengths of each model to handle nuanced or ambiguous reviews.
Finally, we optimized the system to run efficiently on a local machine. By carefully managing computational resources and implementing best practices in prompt design and model selection, we ensured that our solution is practical and accessible, even without high-end cloud infrastructure.
Relevance and Impact
This system directly addresses the problem of assessing review quality and relevance by:
- Identifying valid, helpful reviews versus advertisements or irrelevant content.
- Reducing the need for manual moderation, saving time and minimizing human error.
- Providing transparency with rationale explanations for each classification.
- Enabling small teams or low-resource environments to implement automated moderation effectively.
What we learned
- LLMs can generalize well with few examples when combined with retrieval-based techniques.
- Ensemble approaches help reduce classification errors by leveraging multiple model perspectives.
- Careful prompt design is critical for consistent performance.
- Small, high-quality datasets can be more valuable than large, noisy datasets for certain tasks.
Limitations
- Small evaluation dataset may not cover all real-world scenarios. Dataset was adapted and handwritten by us to cover for the lack of unfiltered data online.
- Ensemble of three LLMs can still be computationally heavy for low-resource machines.
- The system may struggle with highly ambiguous or sarcastic reviews.
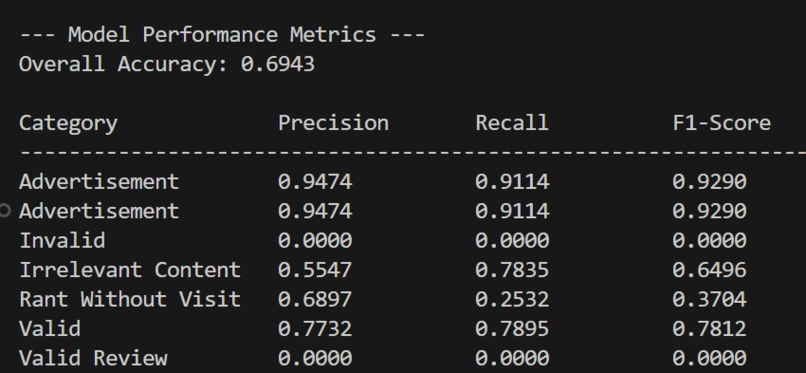
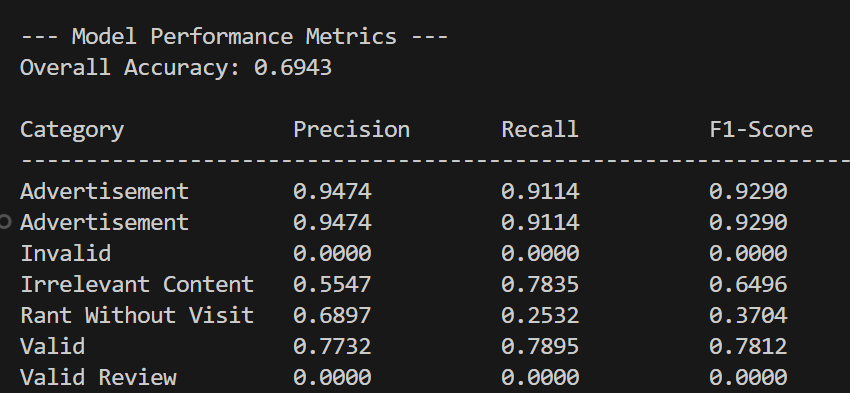
- The system struggles with differentiating irrelevant and rant_without_visit content. However does well identifying valid content. 88% Precision Rate.
- Current method is limited to English-language reviews
What's next for Leveraging LLM in Assessing Reviews
- Expand the dataset to include more diverse and multilingual reviews.
- Explore lighter LLMs or distillation techniques to reduce computation.
- Incorporate feedback loops to improve model predictions over time.
- Integrate the system into TikTok moderation pipelines for real-time review assessment.
- Incorporate clearer distinction of guidelines for the less obvious policies.




Log in or sign up for Devpost to join the conversation.