-
-

Landing Page
-
Simulation and Overview
-
AI Insights

Level - The Spellcheck for Fairness in Your Data
What it does
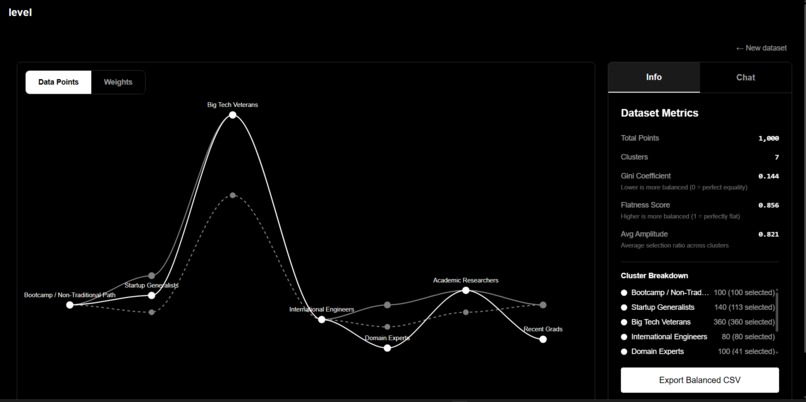
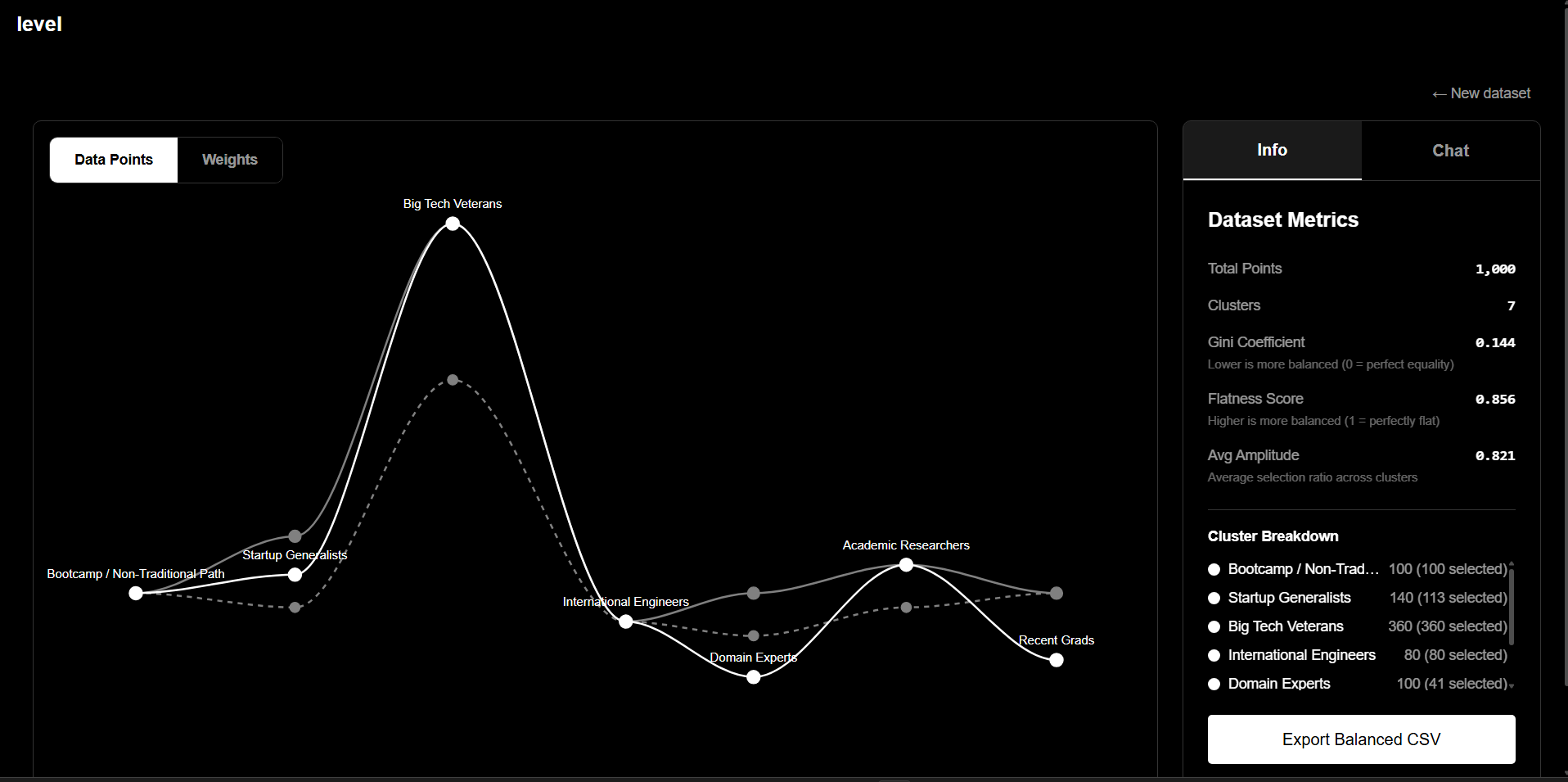
Level helps organizations detect and rebalance bias in the data that powers their decisions. It turns raw applicant information into clusters that show which groups dominate and where representation is missing. Each cluster is visualized as a node, and users can drag them down to reduce their influence before training a model or deploying an AI system.
This is not about deleting data blindly. Some overrepresentation comes from broken collection processes and should be removed. Other overrepresentation reflects real-world truth and should remain. Level surfaces the difference and gives humans the power to decide.
For example, a lending dataset might show that 80% of applicants are from high-income ZIP codes. That is scientifically biased if your collection missed lower-income regions. But it might also reflect reality about who applies for certain loans. Level lets you decide whether that imbalance is a data flaw or a feature you want to preserve.
Why we built it
AI bias is breaking critical systems, but not for the reasons most people think. The word "bias" actually describes two completely different problems that get dangerously conflated:
Scientific bias is data that deviates from reality. Duplicated records, outdated training data, broken collection processes. It makes models less accurate. Everyone agrees it should be fixed.
Political bias is data that accurately reflects uncomfortable truths about demographic differences. It makes models more accurate but raises moral questions about how that accuracy should be used.
The confusion between these has led to catastrophic failures. COMPAS (2016), a recidivism prediction algorithm, was exposed for having different error rates across racial groups. But the model was statistically accurate. It reflected real differences stemming from systemic inequality. The debate was whether statistical truth justifies differential treatment. No one could agree because they were arguing about different definitions of bias.
A healthcare risk algorithm (2019) used spending to predict medical need, systematically underestimating Black patients' needs. This was scientific bias. The data lied because unequal access meant Black patients spent less despite being equally sick. Everyone agreed this needed fixing.
The line gets blurrier with everyday examples. If your name is Thomas in the US, there's a 99%+ chance you're male. Not scientifically biased, but politically biased. Most people accept this. It means don't advertise tampons to Thomas.
If your name is Muhammad, there's a high probability you're Muslim. Should the pork industry avoid advertising to you? One camp says it's discriminatory to treat Muslims differently. Another says it's offensive to show Muslims pork ads. Both claim moral authority. Both cannot be satisfied. There is no technical solution.
These conflicts escalate rapidly. A condo developer advertising luxury units targets high-income ZIP codes. Those areas are disproportionately white and Asian due to historical housing discrimination. The developer never mentions race, but fewer Black and Latino people see the ads. Scientifically accurate. Politically explosive. Potentially illegal under Fair Housing laws.
Most AI fairness tools either ignore political bias entirely or try to flatten it. The first reinforces inequality. The second destroys useful signal and makes systems uncompetitive. Both approaches fail.
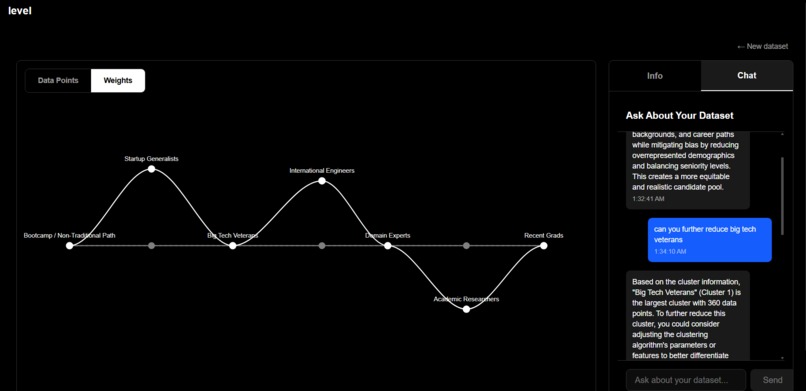
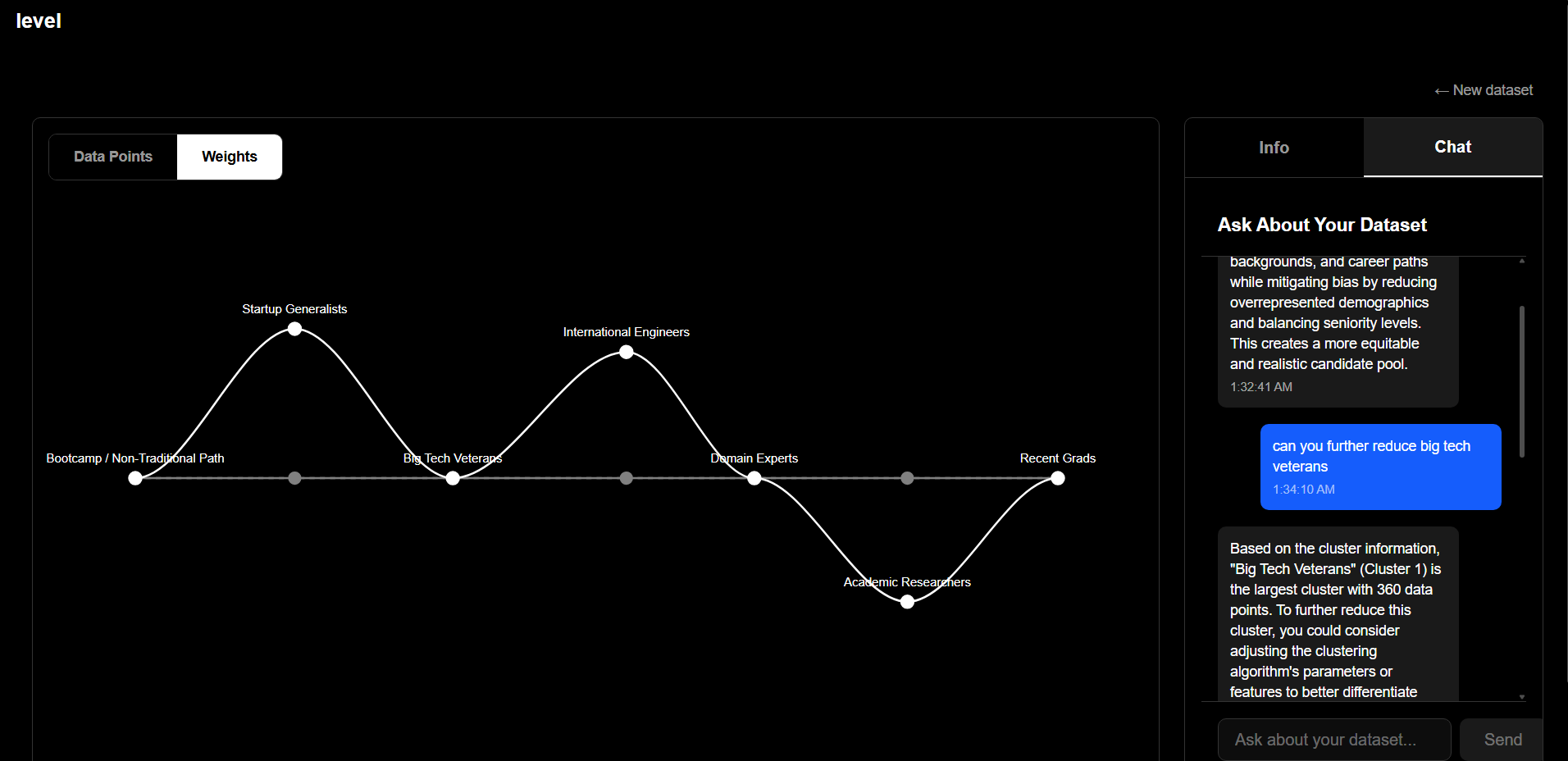
Level doesn't define fairness for you. It gives you visibility into both types of bias and control to make intentional choices. If ZIP code is acting as a proxy for race in ways that violate your values or the law, you can prune that cluster. If applicants named "Elliot" are being misclassified because your training data is temporally limited, you can rebalance it.
The goal isn't to eliminate bias. That's impossible. The goal is to separate lies from uncomfortable truths, and to shape your data before biased decisions become deployed systems.
Tech Stack
Back-end: FastAPI, Python, Cohere API, UMAP, DBSCAN, Gemini API, NumPy, Pandas
Front-end: Next.js, React, TypeScript, Tailwind CSS, Three.js, Auth0





Log in or sign up for Devpost to join the conversation.