

Inspiration
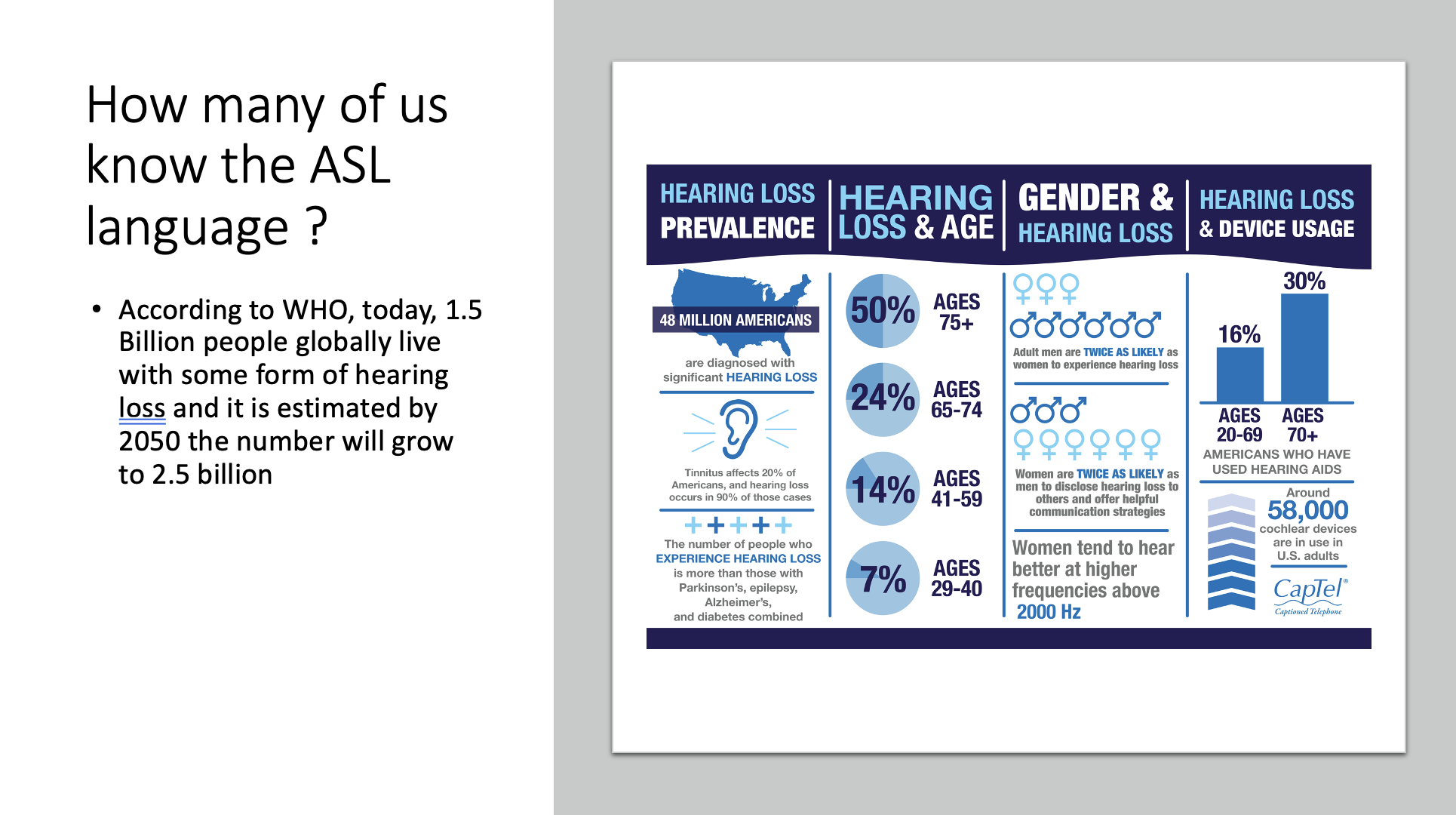
48 million people in America and 63 million people in India are affected by some form of hearing
impairment. However, only 500,000 people or about 1% of all Americans know sign language. According to WHO, today, 1.5 Billion people globally live with some form of hearing loss and it is estimated by 2050 the number will grow to 2.5 billion. However, despite these statistics existing products on the market today that are meant to help people affected by this condition lack features and an accessible UI for everyone to intuitively use. Most products are only capable of spelling out words with signs. With a condition that affects billions of modern lives in mind, our team decided to create Let’s Talk; a virtual tool aimed at bridging the gap of understanding between and connect those that do and do not know sign language. We aim to connect groups of people that understand and do not understand sign language by activity translating sign language (a language that is only known by a portion of the globe) to those that may not have had the opportunity to learn.
What it does
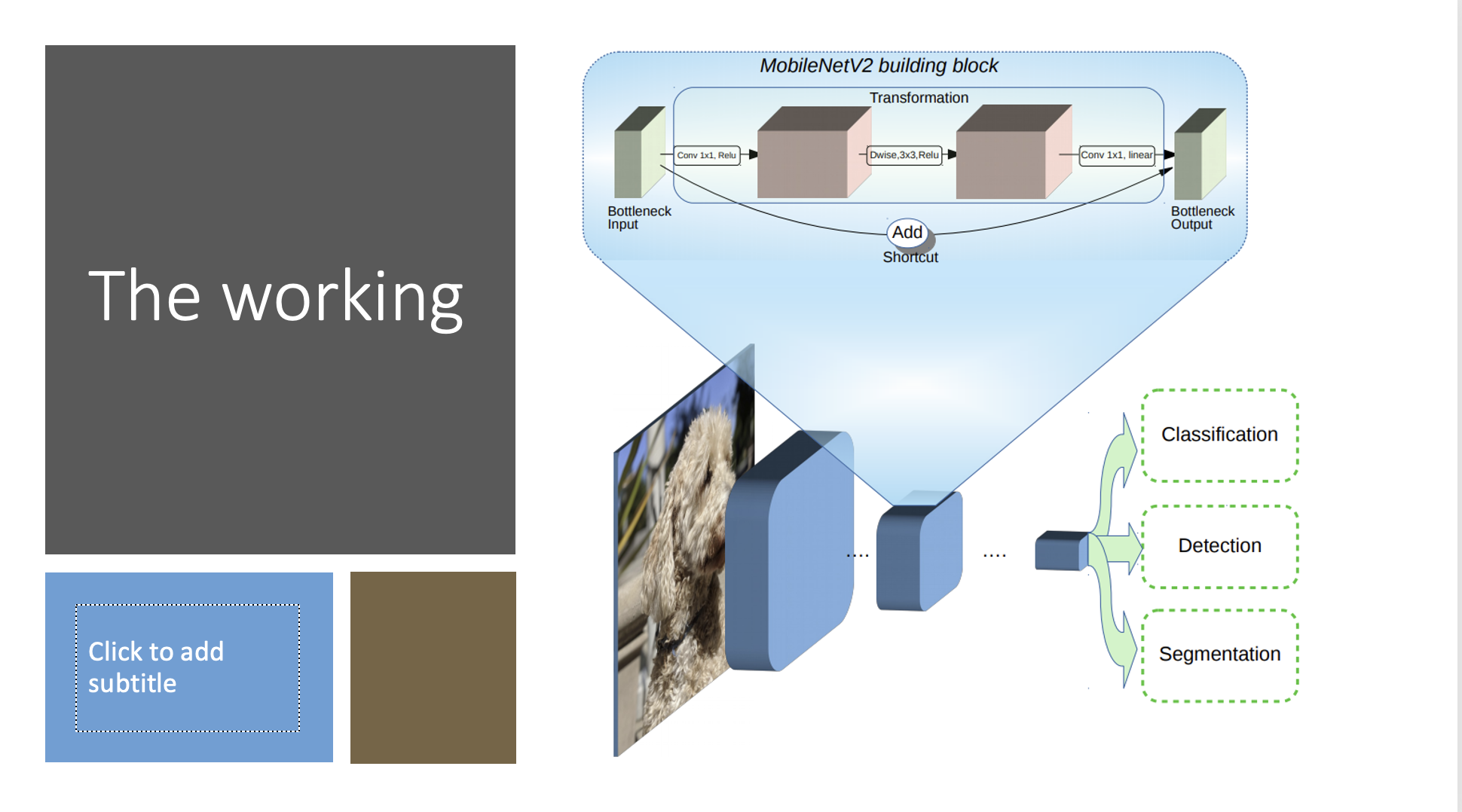
“Let’s Talk” is a virtual tool and assistant that utilizes Image Classification and deep learning to
recognize sign language and translate to a desired language. The underlying sign recognition model utilizes transferred learning using Tensor Flows’s MobileNet and KNN model to predict English words for given signs. In addition, we utilize AWS’ TranslateClientAPI to translate our generated sentences into a sentence of a user’s desired language.
Currently our app supports two modules, one training and one sign recognition model. The training module allows users to upload photos of signs and label them accordingly to train the underlying sign recognition model. The sign recognition module utilizes a device’s camera to capture user’s signs and predicts the English translation. In addition, Let’s Talk provides an additional translation based on a language of a user’s choice.
How we built it
Our team built “Let’s Talk” by utilizing technologies such as Google’s TensorFlow, MobileNet, Bootstrap, and Express.js for our node server. Google’s TensorFlow, MobileNet and KNN-algorithm is employed by the training model to allow user’s to upload photos of their signs and label them their corresponding English word translation. The image training model is used by the recognition module to predict the English translation of other user’s signs. Lastly, AWS’ TranslateClientAPI is needed to provide an additional translation of the predicted English text to a language of the user’s choice.
Challenges we ran into
- Finding the right problem to tackle
- Code capability with React
- Fine tuning and choosing the parameters of the training model
Accomplishments that we're proud of
- Learning how to utilize unfamiliar technologies (Google’s TensorFlow, MobileNet, TranslateClientAPI)
- Not giving up and surviving till the end
What we learned
- Utilizing new technologies
- Prioritization, time management
- Building a minimum viable product (MVP)
What's next for Let's Talk
Our team has many aspirations outside of what we accomplished during the Hackathon. Beyond this event we wanted to focus on making the app more scalable while maintaining speed and reactivity to all end users. We hope to one day expand our training data set to include a larger set of sign images to work from. In addition, we wanted to explore other models and algorithms for Image Classification. Lastly, we wanted to explore the possibility of doing the opposite and predict signs based on words.
Built With
- amazon-web-services
- bootstrap
- css
- express.js
- html
- mobilenet
- node.js
- tensorflow
- translateclientapi

Log in or sign up for Devpost to join the conversation.