-
-
Assessment Page
-
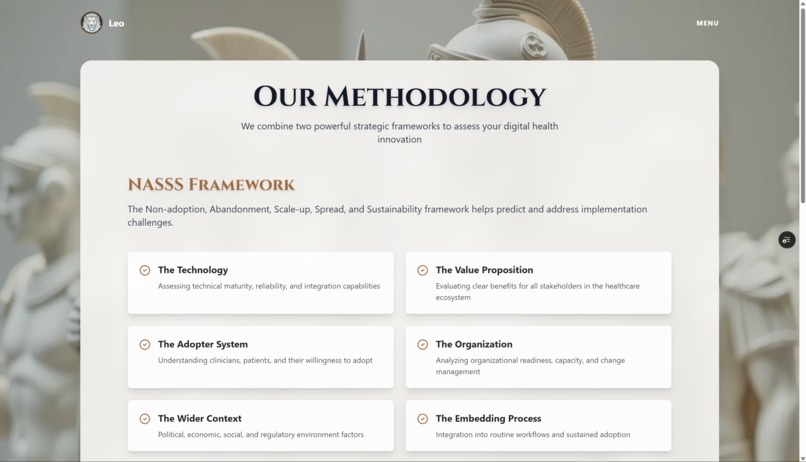
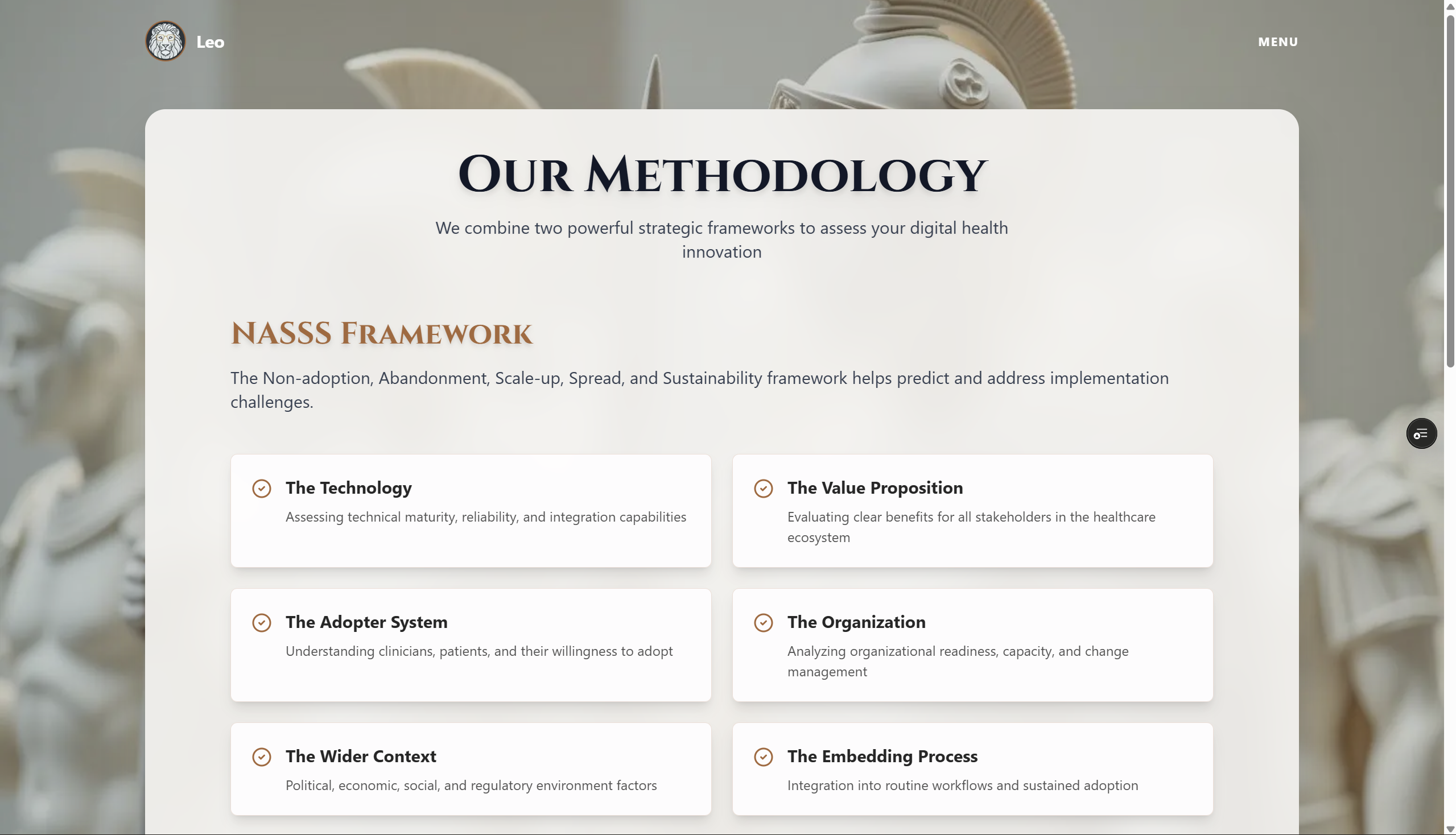
Methods Page
-

Menu Screen
-
Landing Page / Home Page
-
About Page

Leo HealthTech Validator: Saving Health Startups Through AI-Powered Strategic Analysis
The Problem
98% of digital health startups fail within five years—not due to poor technology, but fundamental strategic flaws. Founders chase innovation while overlooking critical adoption barriers, regulatory complexities, and flawed business models. Traditional validation is expensive ($10K+ for consulting) and inaccessible to early-stage founders who need it most.
The Solution
Leo is an AI-powered strategic validator that predicts startup survival probability through a novel two-stage interrogation architecture:
Stage 1 (Interrogation): Claude analyzes the pitch against four healthcare-specific frameworks and generates 3 surgical questions targeting critical gaps—not generic queries like "Who are your competitors?" but specific challenges like "Your 92% accuracy claim from 150 patients lacks a control group—how will you demonstrate clinical utility for FDA approval?"
Stage 2 (Verdict): After founders provide evidence-based answers, Claude synthesizes the complete picture into a comprehensive assessment with framework-specific scores, critical risks, and actionable recommendations.
How it was Built
Architecture: Next.js full-stack application with Anthropic's Claude Sonnet 4 as the reasoning engine.
Knowledge Base: I implemented a "RAG-Lite" approach, injecting four comprehensive frameworks (~15,600 characters) directly into prompts:
- NASSS Framework (adoption risk analysis)
- Play-to-Win Framework (strategic positioning)
- Healthcare Business Model Canvas (economic viability)
- Digital Health Regulatory Framework (FDA/HIPAA/reimbursement pathways)
Extended Thinking: Enabled Claude's reasoning transparency (10-15K token budget) so founders can see how Leo analyzes their startup—showcasing systematic framework application.
Prompt Engineering: Crafted detailed system prompts that force structured JSON outputs, specific questions, and evidence-based scoring (0-100 survival score with framework breakdown).
Challenges Faced
Token Efficiency: Initial prompts used 30K+ tokens. Optimized through framework relevance scoring and two-tier injection strategies.
Output Consistency: Claude occasionally generated generic questions. Solved by adding specific examples and counter-examples in prompts.
Complex State Management: Two-stage flow with cancellation support required careful AbortController implementation and error handling.
Healthcare Domain Depth: Researched FDA pathways, CPT codes, ACO dynamics to ensure frameworks reflected real regulatory complexity—not generic business advice.
Impact & Learning
Leo transforms a $10K, week-long consulting process into a $0.15, 60-second AI audit. Through building this, I learned that prompt engineering is strategic design—every instruction shapes how Claude reasons. Extended thinking revealed that Claude systematically applies frameworks when given proper structure, making AI reasoning transparent and trustworthy.
The 65% survival score Leo gave my test startup (CardioWatch AI) correctly identified thin margins and weak clinical evidence—the exact issues that doom most health ventures.
Leo doesn't just validate startups; it teaches founders to think strategically about healthcare innovation.
Built With
- claudeapi
- nextjs
- react
- tailwind


Log in or sign up for Devpost to join the conversation.