

Inspiration
The law firms supplied us with a Excel sheet they have been builiding every day to keep track of recent changes and developments in the Swiss legislation process. This sheet has to be created manually by paralegals, which requires lots of manual crawling and comparing of different webpages, e.g. the Goverment (Bundesrat) or the parliament. Usually, law firms have 1-2 employees just for this cause.
We want to support the law firms by making this process easier.
What it does
We have built Legislatory with 4 main functionalities in mind:
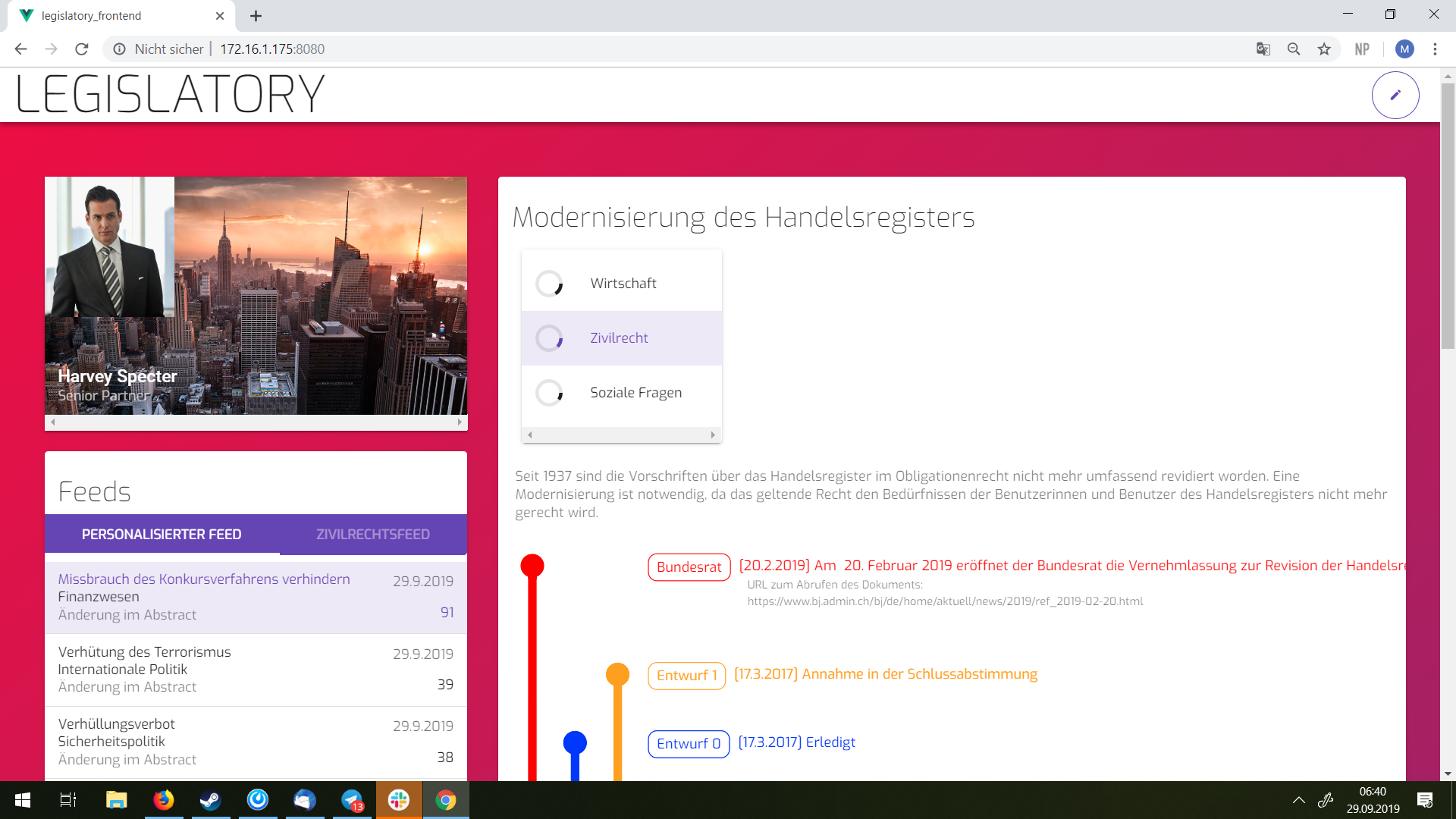
We data mine the Bundesrat's and parliaments websites to create a semantic, connected network of the laws and decisions in progress
We want to improve on the existing categorization that is partly done by the Swiss parliament of current laws-in-progress and built a classifier built on NLP using IBM Watson.
Using this improved classification, we implemented a personal feed that can be deployed to lawyers. E.g. lawyers could focus on international law or civil law and primarily receive notifcations on changes about this topic. Every new development is scored using an algorithm we built and if it's important, it is put into the personalized feed.
Lastly, very important to us was visualization. This is why we wanted to improve on the existing Excel sheet by building an interactive timeline. Each law-in-progress has a detailed timeline that can be easily followed. The events are aggregated over multiple data sources.
How we built it
For the backend, we mainly used Python for data mining as well as the backend server itself using Flask. As a database, we rely on MongoDB. The frontend we built with Vue using the Vuetify framework. The language processing is done using IBM Watson cloud.
Challenges we ran into
As Germans, we firstly needed to understand the Swiss legislation process. Then, the biggest challenge was that the data was unstructured, but we needed links and connections. Thus, it was difficult to built a data mining tool that implements this. Another challenge was to think of a good scoring algorithm.
Accomplishments that we're proud of
We are proud that we really created a dense, interesting dashboard that visualizes lots of the information that previously has to be put together manually. This really is awesome to see, because after talking to our challenge partners from the Legal Tech team, we think this really addresses the needs of our users. Seeing how we went from unstructured text to a nicely looking timeline in just a few hours really made us smile.
What we learned
Firstly, we learned a lot about legislation in Switzerland. In order to mine the data, we needed to learn about the origins of the raw data at first. Also, this was the first time for us using IBM Watson, so we had some interesting insights there. XPath and how to parse unstructured data was also a topic we haven't worked on in a long time.
What's next for Legislatory
Firstly, one needs to improve on the notifcation service, which could also keep in made recent changes and easily be adopted to be sent out via mail/sms/WhatsApp etc. As we focused on Bundesratsinitiativen, more data sources for laws sent into parliament need to be mined and introduced into the system. Then, one could go on to different law systems, e.g. the European or German market.

Log in or sign up for Devpost to join the conversation.