Inspiration
We put ourselves in the shoes of investors. We wanted to offer model portfolios—Growth (Risk-On), Balanced, and Defensive (Capital-Preserving)—to simplify financial decision-making, make the impact of legal documents easier to read and explain, and help investors build durable, long-term wealth.
What it does
LegImpact turns dense legal and regulatory text into a portfolio-ready impact signal that investors can read, trust, and act on.
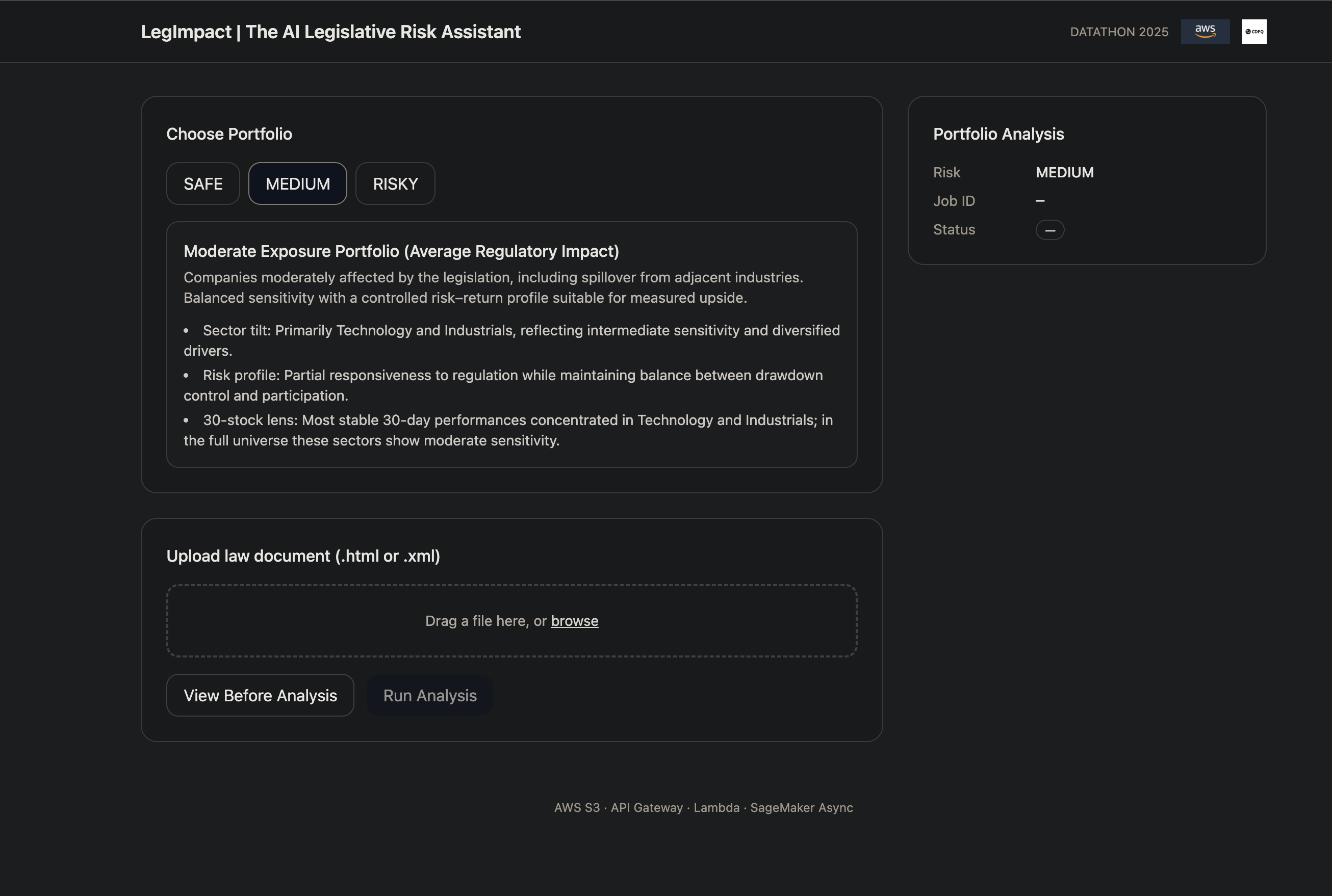
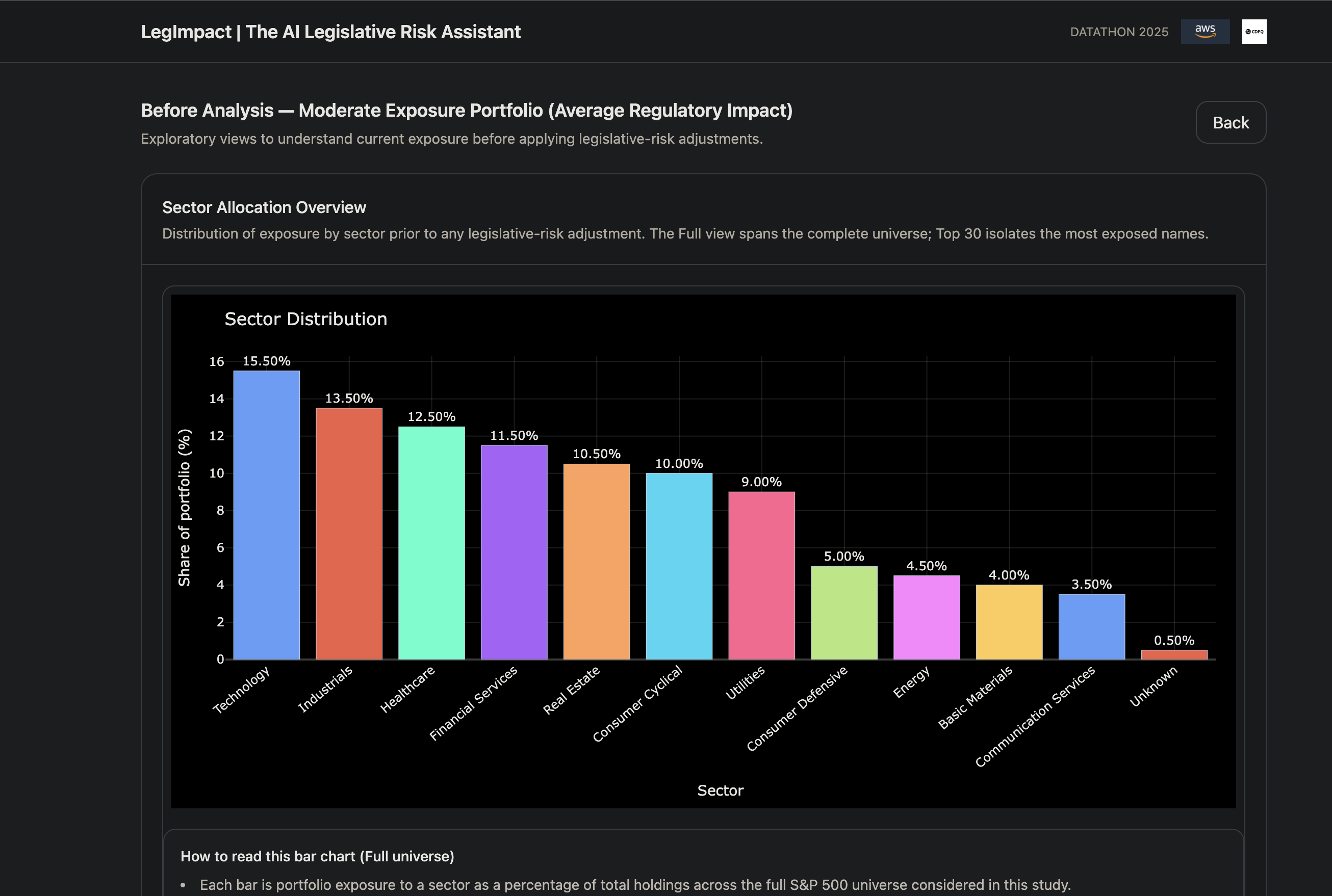
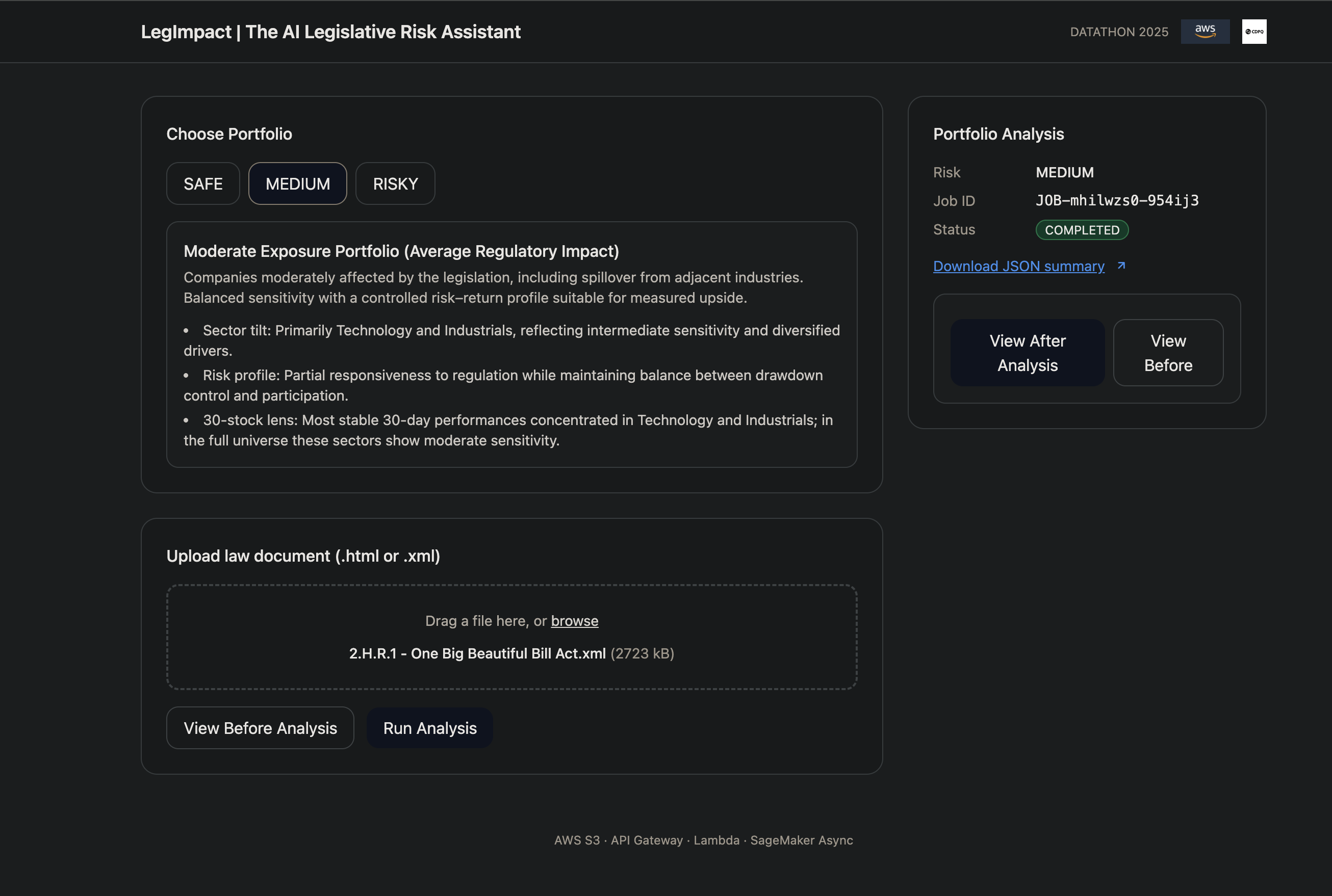
Pick a portfolio (Growth/Risk-On, Balanced, Defensive). You immediately see a pre-diagnosis: sector and regional exposures, return and volatility indicators, and concentration risks.
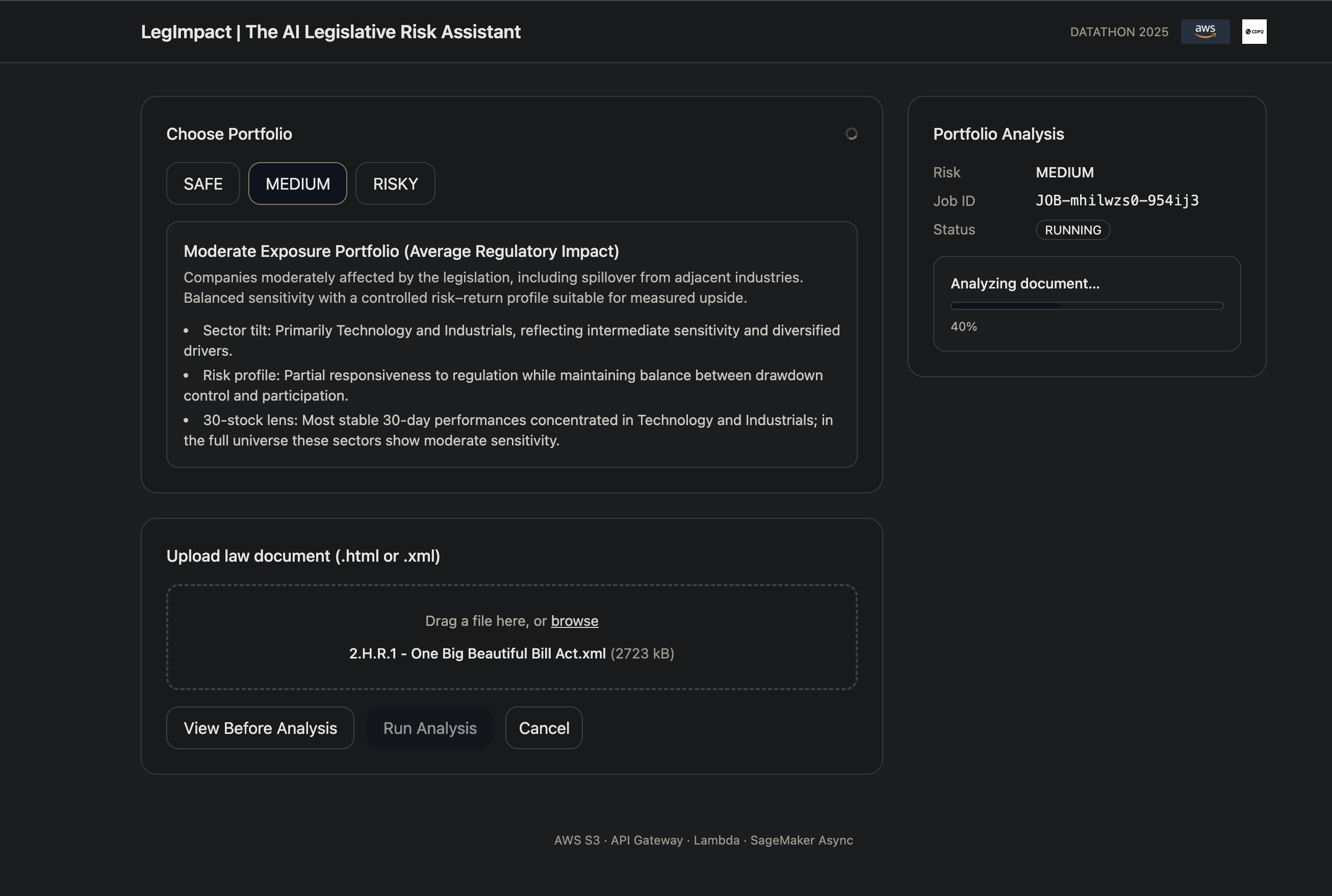
Upload a legal or regulatory document (PDF/HTML/XML, in any language). The UI shows a job card with status and a tracking job_id.
Via API, two complementary layers operate:
An NLP Layer to understand, classify, and structure the content of legal and regulatory documents.
A Financial Analytics Layer that maps the extracted regulatory signal onto company fundamentals, market exposures, and portfolio risk characteristics using structured financial data retrieved through APIs such as yfinance, together with broader quantitative market features.
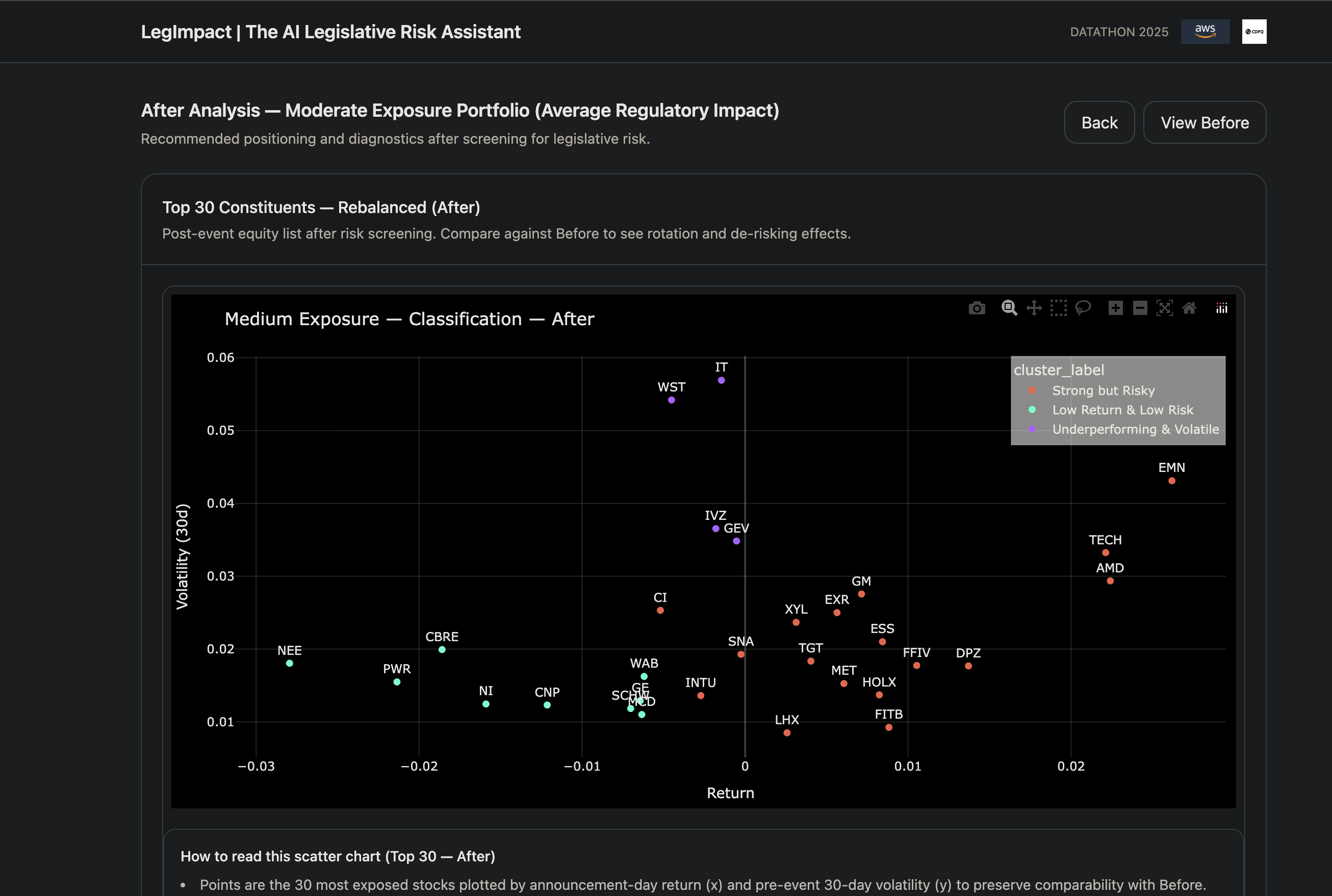
Get an investment-grade output: a quantified view of which companies and portfolios are likely to be affected, and to what extent.
How we built it
1) Investor-first UX
The user selects a portfolio (Risk-On / Balanced / Defensive) and sees a preliminary diagnostic: regional and sector exposures, expected volatility, and potential drawdown risk. They then upload a legal document (PDF/HTML/XML). The interface is designed to remain clean, intuitive, and explainable, with one-click upload, clear job status, and outputs that can be understood quickly by both investors and decision-makers.
2) APIs & Queueing (scalable by design)
API Gateway provides:
POST /jobs → creates a job (DynamoDB), stores the file in S3, and returns a job_id
POST /jobs/{id}/start → launches processing
GET /jobs/{id} → polls status (queued / processing / done / failed)
A DynamoDB-backed queue decouples the user experience from heavier compute workloads and enables scalable orchestration.
3) Quantitative Analytics Pipeline
A. Portfolio & SEC pipeline
We parse 10-K/10-Q filings with sec-parser and use Claude Sonnet 3.5 on key sections—Item 1, Item 1A, and Item 7—to extract geography, revenue exposure, operating regions, and concentration-related signals.
Output: a structured company feature matrix summarizing sector, geographic, and revenue-related exposures.
B. Legal-document pipeline
If the uploaded law is not in English, we translate it with Claude Sonnet via Bedrock, then clean, normalize, and chunk it. Amazon Nova and Claude Sonnet 3.7 are then used to identify jurisdiction, sector, activities, regulatory domain, and impact type.
Output: a structured regulatory representation of the document’s scope and direction.
C. Quantitative scoring & impact index
We compute the document-to-market impact by mapping the regulatory representation onto company and portfolio data through a quantitative scoring framework.
This layer does not rely only on text correlation. We designed an impact scoring index that combines the regulatory information extracted from the legal text with structured financial and market features. In addition to company disclosures, we enriched the framework with a broader universe of market variables and trained traditional machine learning models on these features to better connect legal signals to effective market behavior.
This allowed us to move from a purely qualitative legal interpretation to a more robust, quantitative estimate of impact. The final score incorporates dimensions such as jurisdiction fit, sector proximity, activity overlap, market sensitivity, and portfolio exposure, then aggregates them into company-level and portfolio-level impact measures.
The result is a more investment-relevant signal: not just what the law says, but how strongly it may matter in practice for securities and portfolios.
Challenges we ran into
Scope vs. a 36-hour deadline: designing a full AWS architecture and an end-to-end analytics pipeline in such a short timeframe was challenging. We had to make careful trade-offs between technical ambition and reliable execution.
Granularity of legal analysis: at first, we assumed each article within a law might carry its own effective date and its own market effect. After experimentation, we found that the most robust portfolio-level signal comes from treating the legal text holistically first, and only then drilling down further if needed.
Translating legal language into investment signals: one of the hardest parts was bridging two very different worlds—legal structure and market behavior. Making that mapping both explainable and quantitatively credible required repeated iteration on the scoring methodology.
Accomplishments that we're proud of
Regulatory → Market linkage (a signal investors can act on)
Built a method to transform dense legal text into a structured regulatory signal and align it with a company feature matrix, producing security-level impact estimates and a portfolio-level roll-up.
Multi-format, multilingual ingestion
Implemented robust parsing for PDF, HTML, and XML files, with language detection and translation prior to normalization and analysis.
Quantitative impact scoring index
We differentiated ourselves through the design and backtesting logic of an impact scoring index that does not rely only on financial reports. Thanks to the team’s finance background, we refined the score with quantitative analyses built on market data, making the final assessment more robust and closer to real portfolio behavior.
Correlation & scoring engine
Implemented a scoring stage that produces stable, repeatable impact scores with confidence estimates, combining regulatory features with company fundamentals, market variables, and portfolio exposure characteristics.
Industry-style team organization under a 36-hour constraint
We successfully organized the team in a structure close to a real industry setup, with two quant analysts and two cloud engineers working in parallel on complementary tracks. This division of roles made execution smoother, improved coordination, and helped us ship a coherent MVP under tight time constraints.
What we learned
Deep hands-on experience with S3, API Gateway, Lambda, and SageMaker Async Inference, along with Bedrock model orchestration.
How to parse legal documents across XML, HTML, and PDF formats, detect language, translate content, and normalize the text before downstream analysis.
How to extract jurisdiction, sector, covered activities, regulatory domain, and impact type, and connect those dimensions to company exposures and portfolio construction.
How to go beyond document understanding by integrating broader financial and market features into a quantitative scoring framework that is more robust and more relevant for investors.
What's next for LegImpact | The AI Legislative Risk Assistant
Reactive analytics & live dashboards
Move from static charts to event-driven visualizations that update automatically after inference and market moves, including heatmaps, contribution views, and jurisdiction maps.
Alerting & portfolio automation
Push alerts when new laws match portfolio exposures, with optional policy playbooks for rebalancing or hedging workflows.
Human-in-the-loop review
Add an analyst validation interface to approve, override, and justify labels and scores, improving explainability and creating feedback for future model refinement.
RAG + vector memory for precedents
Store prior decisions, regulatory precedents, and contextual explanations to improve consistency across similar documents.
Enterprise readiness
Add features such as SSO/SAML, audit logs, private deployment options, and secure processing environments for institutional users.
Roadmap to actions
Turn insights into simulated P&L scenarios, regional or sector stress tests, and policy-aware portfolio actions that are both quantitatively and qualitatively defensible.





Log in or sign up for Devpost to join the conversation.