-
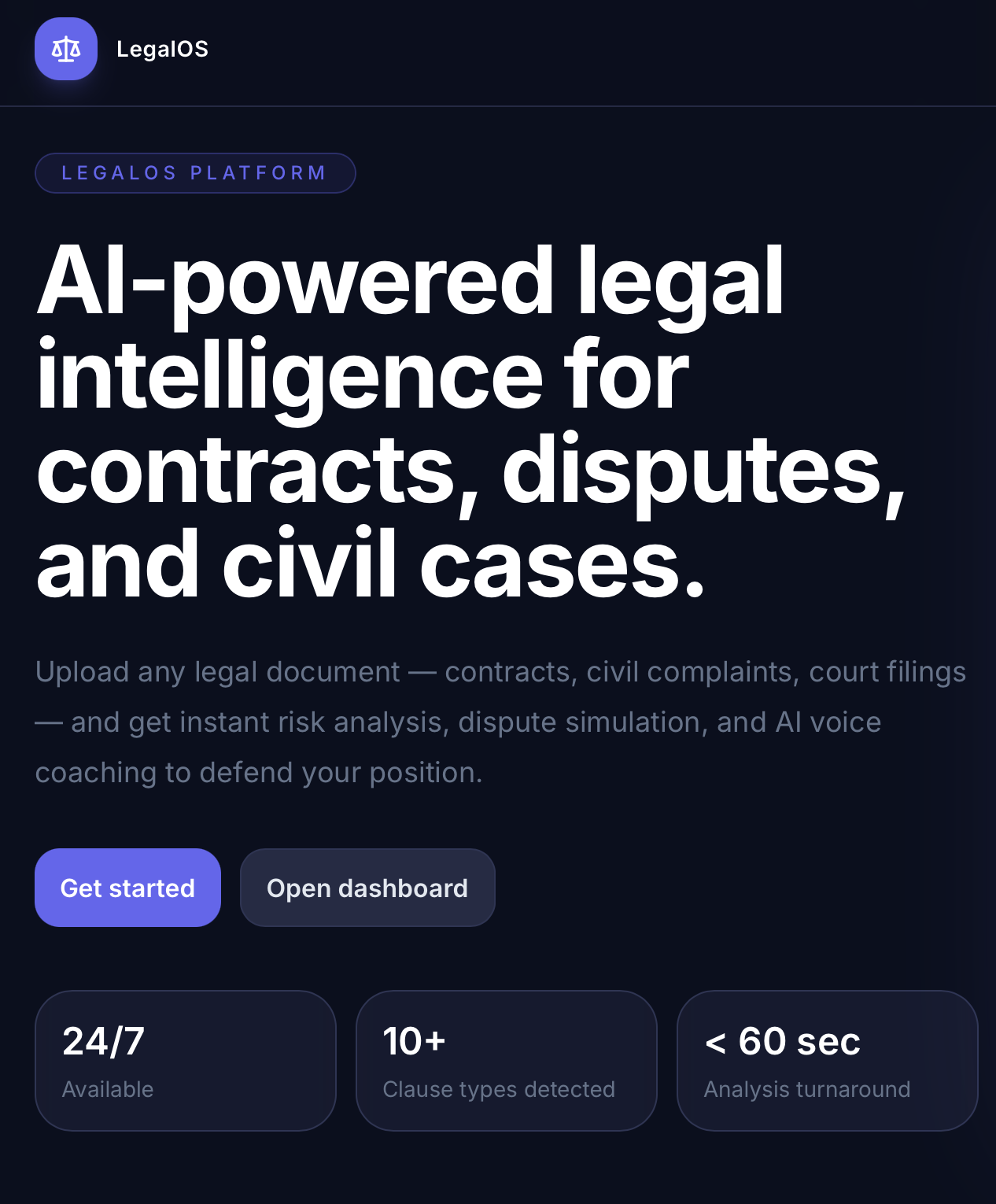
home page
-
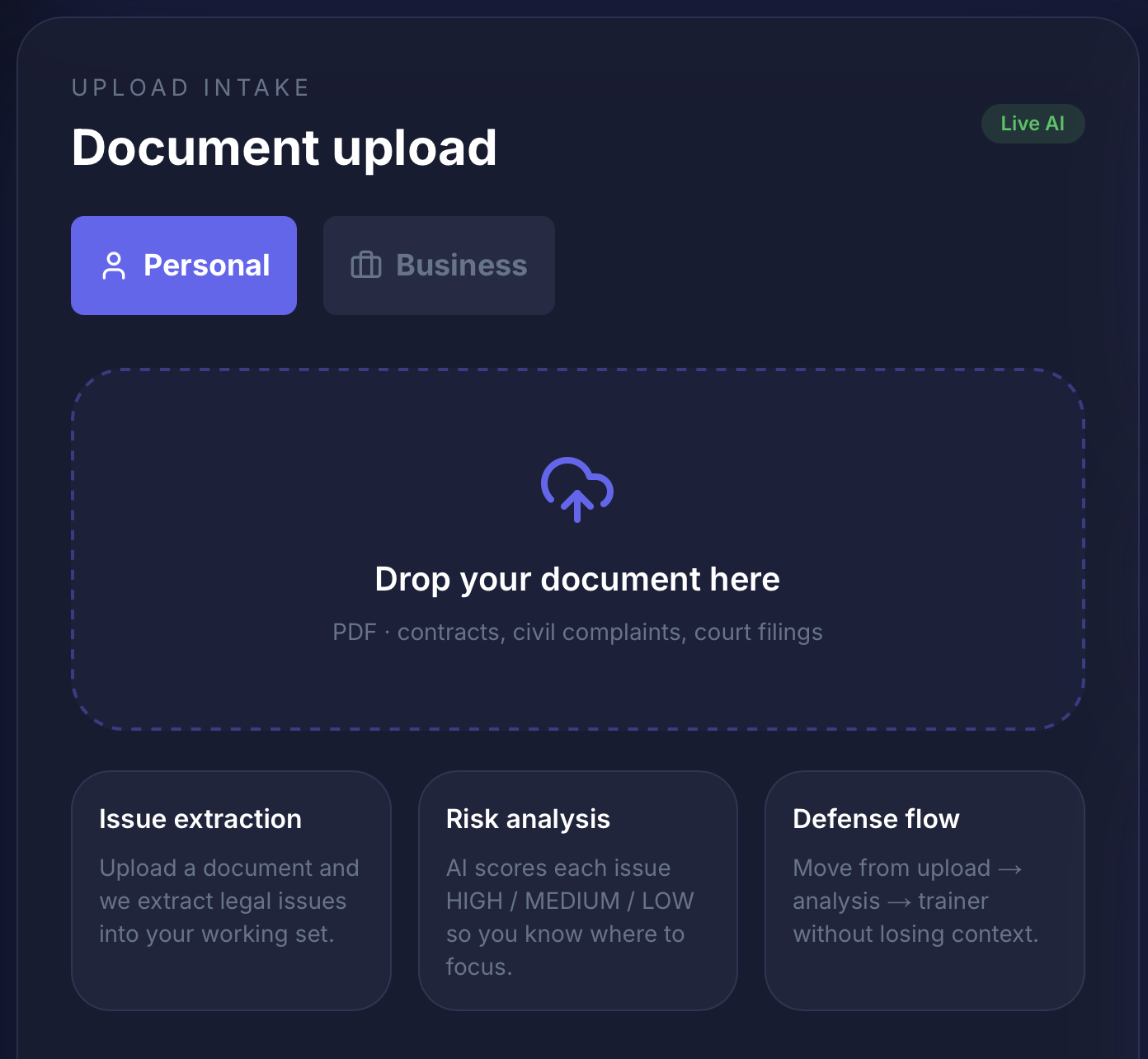
pdf upload
-

example of dispute simulation

Inspiration
77% of Americans face at least one legal issue per year, but most can't afford the $300–500/hour it costs to have a lawyer read their own contracts. People sign bad deals, settle winnable cases, and walk into negotiations blind — not because they're wrong, but because they can't afford to be right. We built LegalOS to change that.
What it does
Upload any legal document — a contract, complaint, or court filing — and LegalOS gives you:
- Clause-by-clause risk analysis — every clause scored HIGH/MEDIUM/LOW with a 0–100 risk score and plain-English explanation
- Overall danger score — one number that tells you how risky the document is
- Precedent case lookup — real US court cases relevant to each clause
- Dispute simulation — Monte Carlo-style litigation prediction with win probability, cost estimates, and a FIGHT/SETTLE/NEGOTIATE recommendation
- Live AI negotiation call — practice arguing against AI opposing counsel who defends the contract in real time with voice, responds to your specific objections, and coaches you on what to say
- Pitch trainer — record your objections and get scored on confidence, clarity, and legal strength
How we built it
Frontend: Next.js 14 (App Router) with Tailwind CSS, Framer Motion for animations, and Recharts for simulation visualizations.
AI/LLM: OpenAI GPT-4o-mini powers all legal reasoning — clause analysis, risk scoring, dispute simulation, opposing counsel responses, precedent search, and plain-English explanations. All through Next.js API routes.
Voice: ElevenLabs text-to-speech (eleven_multilingual_v2 model) gives opposing counsel a realistic voice during live negotiation calls. Web Speech API handles real-time speech-to-text for user input. Falls back to browser speech synthesis if ElevenLabs is unavailable.
Data layer: MongoDB Atlas stores document history and analysis results. We chose MongoDB's document model because legal data is naturally nested — a document contains clauses, each clause has scores, explanations, and precedent cases.
Enterprise intelligence: Palantir Foundry integration via the AIP Actions API. Every analysis syncs 6 ontology object types to Foundry — Legal Documents, Clauses, Risk Analyses, Dispute Simulations, Parties, and Court Cases — enabling cross-document queries and dashboards at scale.
Infrastructure: Deployed on AMD EPYC-powered cloud infrastructure through Vercel (serverless functions) and Render (original Python ML backend). AMD handles the burst compute pattern of our document processing pipeline.
Auth: Clerk for authentication and route protection.
Challenges we faced
- ElevenLabs model deprecation —
eleven_monolingual_v1stopped working mid-hackathon and we had to migrate toeleven_multilingual_v2and add browser speech fallback - Getting GPT to return consistent structured JSON for legal analysis across wildly different document types (contracts vs complaints vs court filings)
- Building the live call state machine — coordinating speech synthesis, speech recognition, API calls, and UI transitions across 6 call phases without race conditions
- Palantir ontology design — figuring out the right object types and relationships to make cross-document queries meaningful
What we learned
- Legal documents are surprisingly varied — a contract risk engine breaks immediately on court filings unless you rethink what "risk" means for each document type
- Voice UX is hard — users need to see what to say while they're speaking, not just before
- Fire-and-forget API patterns (like our Palantir sync) are essential when you don't want third-party latency blocking the user
What's next
- Multi-document comparison (e.g. compare two versions of a contract)
- RAG pipeline with real case law databases instead of GPT-generated precedents
- Export negotiation transcripts as PDF briefs
- Team workspaces with shared document analysis in Palantir Foundry

Log in or sign up for Devpost to join the conversation.