-
-
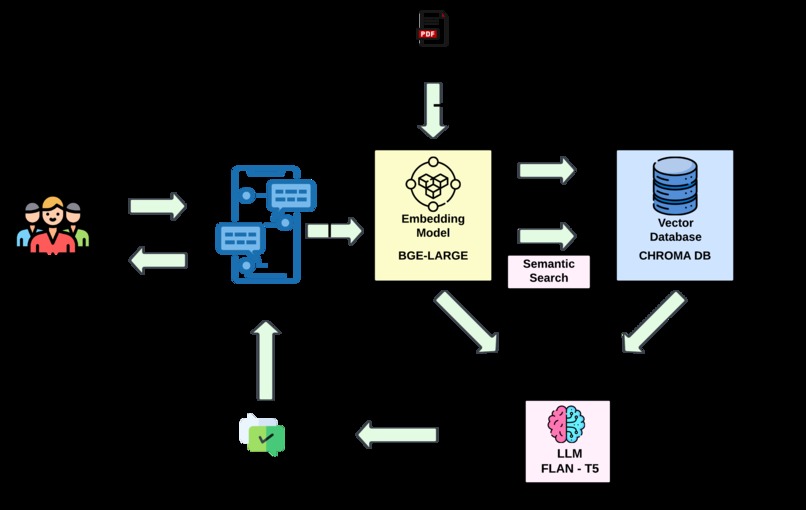
Workflow Architecture
-

Chat logo
-

App Logo
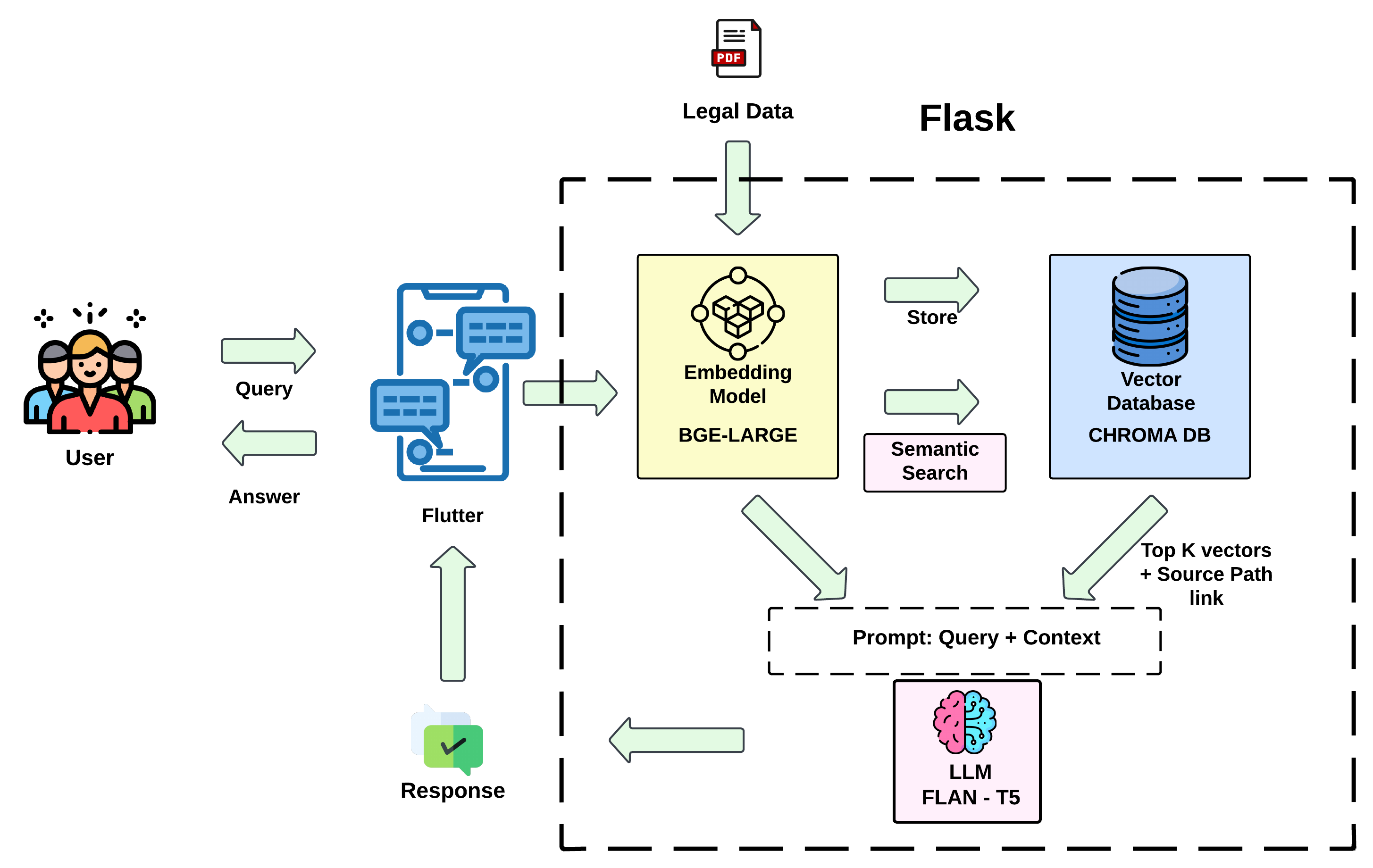


Inspiration
Our inspiration stems from the prevalent issue of individuals enduring discrimination and mistreatment based on race, gender, sex, disability and are often unaware of their rights in such situations. They often struggle to find reliable sources of information or guidance on their rights and avenues for recourse. It contributes to inclusion and diversity in an organization by aiding in drafting inclusive policies, offering unbiased legal guidance, and supporting diverse hiring practices.
What it does
It offers a specialized chatbot application designed specifically for legal documents encompassing human rights, equality laws, and issues relating to sexual orientation. It is designed to respond to specific user queries like "What are my rights on standard of living?" or "What can I do if I feel uncomfortable as an employee?" providing enhanced responses by analyzing relevant legal documents. It also gives user the link to the respective legal document where its easier for the user to further drill down.
How we built it
The base architecture involves a Large Language model called "flan-t5-xxl". As we know, it is nearly impossible to fine tune the LLM as it has 11.3B parameters. Therefore, we employed an approach called as Retrieval Augmented Generation where the documents are created into a vectors using "bge-large-en-v1.5" embedding model from hugging face. Because of the large size of PDF documents, their vectors are stored in ChromaDB and are compared against user queries using semantic search for more efficient retrieval of relevant information using Cosine similarity measure. The retrieved relevant documents combined with query are then sent to the LLM for response. The solution was then deployed locally using Flask and model end points were exposed. The user front end was created in form of a Mobile application using Flutter.
Challenges we ran into
- Testing and deployment of other LLMs with parameters exceeding 20 Billion due to GPU resource constraints.
- Creating the prompt for the Large Language Model (LLM) encountered a limitation when it reached the maximum token limit of 1024.
- Programmatical authentication to hugging face due to token issues and getting 401 http code.
- Finding the right legal documents that could be converted to vector embeddings.
- We tried deploying the model to Azure cloud but we faced issues with Secondary Storage and GPU limitations.
Accomplishments that we're proud of
We are proud of working on this cutting edge technology of LLMs, RAG and Semantic search. This is an effective solution that address a common challenge and will be helping a lot of people. We were also able to deploy the solution by exposing APIs and created an Mobile Application for streamline user interaction. Overall, we created an end to end impactful solution.
What we learned
We have deepened our expertise in tailoring AI solutions to address specific use case, particularly in areas such as human rights and laws. We've utilized cutting-edge technology and gained insights into the end-to-end deployment process. We've also acquired knowledge on effectively delegating tasks, planning, teamwork, and time management skills.
What's next for LegalGPT
- Integration with a comprehensive legal research library, providing access to a vast repository of statutes, case laws, and legal literature for in-depth analysis and citation.
- Improving the model performance by tuning the non trainable hyper-parameters.
- Applying more NLP processing techniques on user queries and raw pdf documents.
- Deploying the solution on public cloud such as Azure.
Built With
- ai
- api
- azure
- cloud
- database
- deep-learning
- flask
- flutter
- llm
- machine-learning
- natural-language-processing
- python
- rag

Log in or sign up for Devpost to join the conversation.