-
-
sample conversation 2
-
sample conversation 1
-
bulk document search app
Inspiration
The field of law contains a diverse set of documents that are usually full of details that may be extremely imperative for the task at hand. Unfortunately, going through these large documents takes a lot of manual labor and there is always a chance of missing key details in the documents.
With LegalAIze, we offer an AI-based solution that takes care of the issues outlined above.
What it does
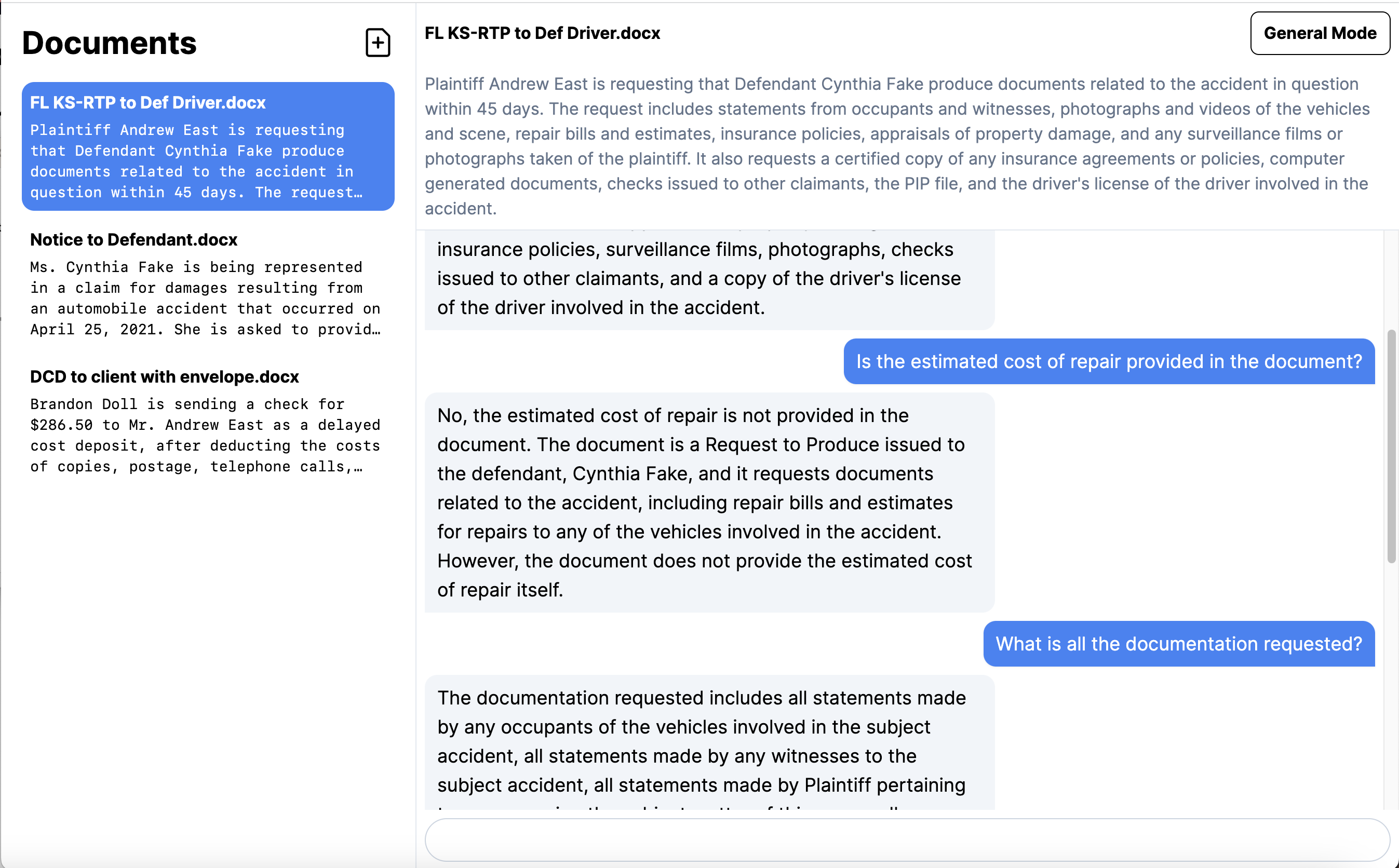
LegAIze allows users to upload both word documents (.docx) and PDFs into a web application. When uploading the document our backend will generate a summary for the document and cache it for later use. Once a document is uploaded a chat-based interface is exposed. This chat based interface allows the user to "chat" with the document.
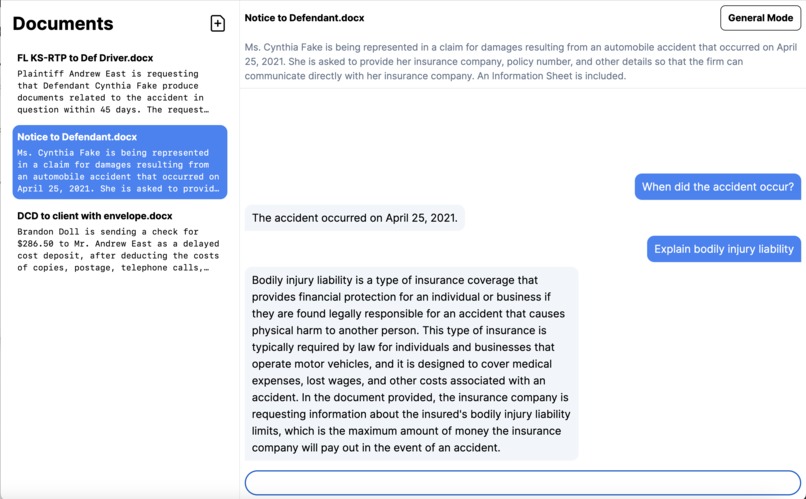
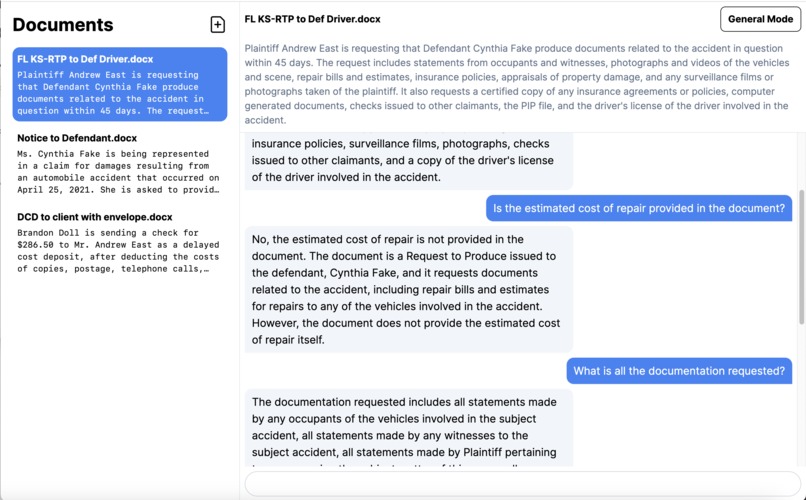
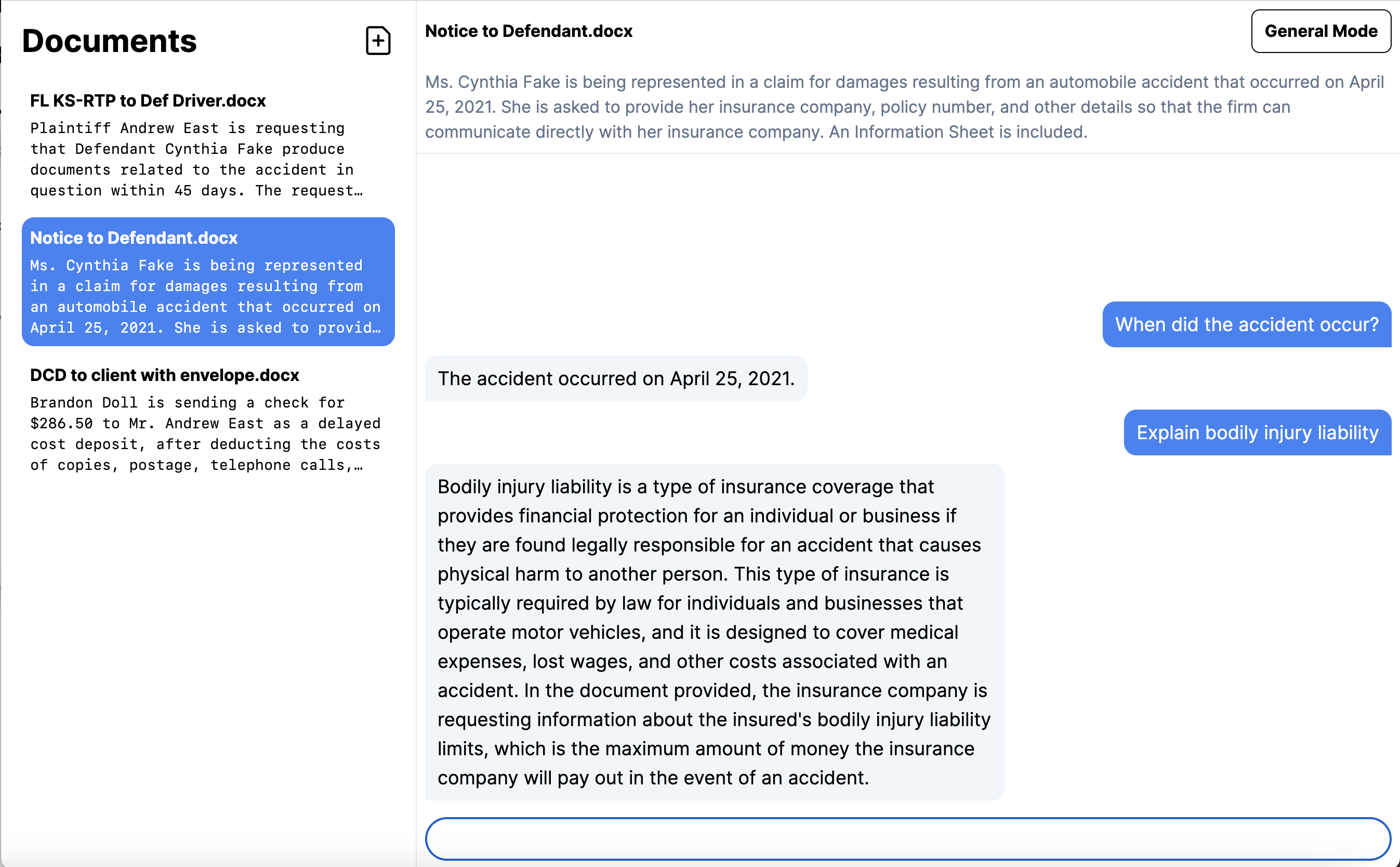
Chat-Based interaction
For example you can ask:
- "Who is the plaintiff in this document?"
- "How much, in dollars, are the damages in this document?"
- "Where did the accident occur?"
Our chat model will then provide natural human-like responses within the chat window.
PDF OCR
In addition to normal PDF documents, we support image-based PDFs via OCR. Sometimes pdfs don't contain digital text but rather scanned in text from a physical paper. In the real world, these are difficult to use since you cannot do a text-based search on them. With legAIze however, we automatically use OCR to deserialize image-based pdf documents to text. As described, above we can then use the chat interface to query the document and extract information with ease.
External Search
Sometimes a user examining a document may have questions that cannot be answered exclusively from the provided document text. Because of this we introduce an external search option. This external search option runs an agent that ingests search engine results and gives the human-like summary back to the user within the same chat window.
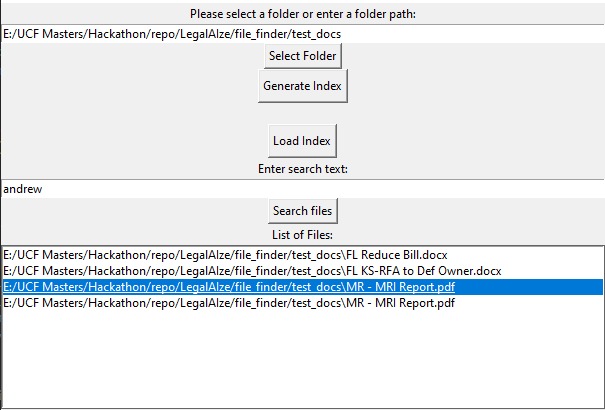
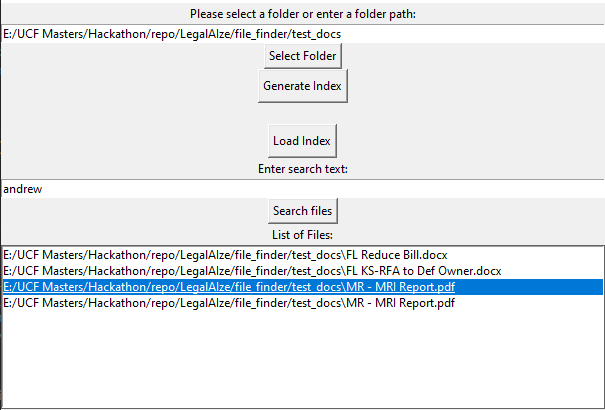
Semantic File-Finder
We offer another standalone application which allows search over multiple documents instead one to find relevant results. For example I can do a document query for a keyword and it will surface all of the documents relating to that query as well as links to open them.
How we built it
Our product was build using lang-chain to create a QA interfaces and an agent that ingests search results. We use a hosted python flask webserver to connect our frontend to our backend. In addition we use a redis cache to cache results from inferences performed on our text model to ensure the application is never slow.
Challenges we ran into
We ran into many issues with uploading and caching the documents. However, after much trial and error we were able to iron out any of those issues. In addition we had some bugs in the chat UI where scrolling would not work and UI would not be responsive. We've done our best to address most of these issues.
Accomplishments that we're proud of
We are proud of the app we developed to help users in the legal industry extract relevant document information.
Additionally, we planned to have a larger team however due to scheduling only two team members could work on this project. We are very happy with how much we were able to accomplish with only two team members.
What we learned
We learned a great deal about LLMs (Large Language Models) and how to tune them for specific domain-specific tasks, via prompt engineering. Additionally we learned how to setup and use some tech that was new like a redis cache.
What's next for LegalAIze, speaking to your legal documents
- Continue to iterate and tune the chat model to provide the best and most informative responses
- Introduce user authentication and user accounts.
- Expand to accept and describe photos.
Built With
- javascript
- langchain
- nextjs
- openai
- python










Log in or sign up for Devpost to join the conversation.