Inspiration
Legal documents are everywhere lease agreements, employment contracts, terms of service but the language is dense and intimidating. We’ve all skimmed a wall of text and clicked “I agree” without really understanding what we’re signing. We wanted to change that. We were inspired by the idea of making legal clarity accessible: not replacing lawyers, but giving people a way to understand documents in plain language, spot potential risks, and know when and where to seek help. Legal Shield was built for AfroPix 2026 with that mission in mind.
What it does
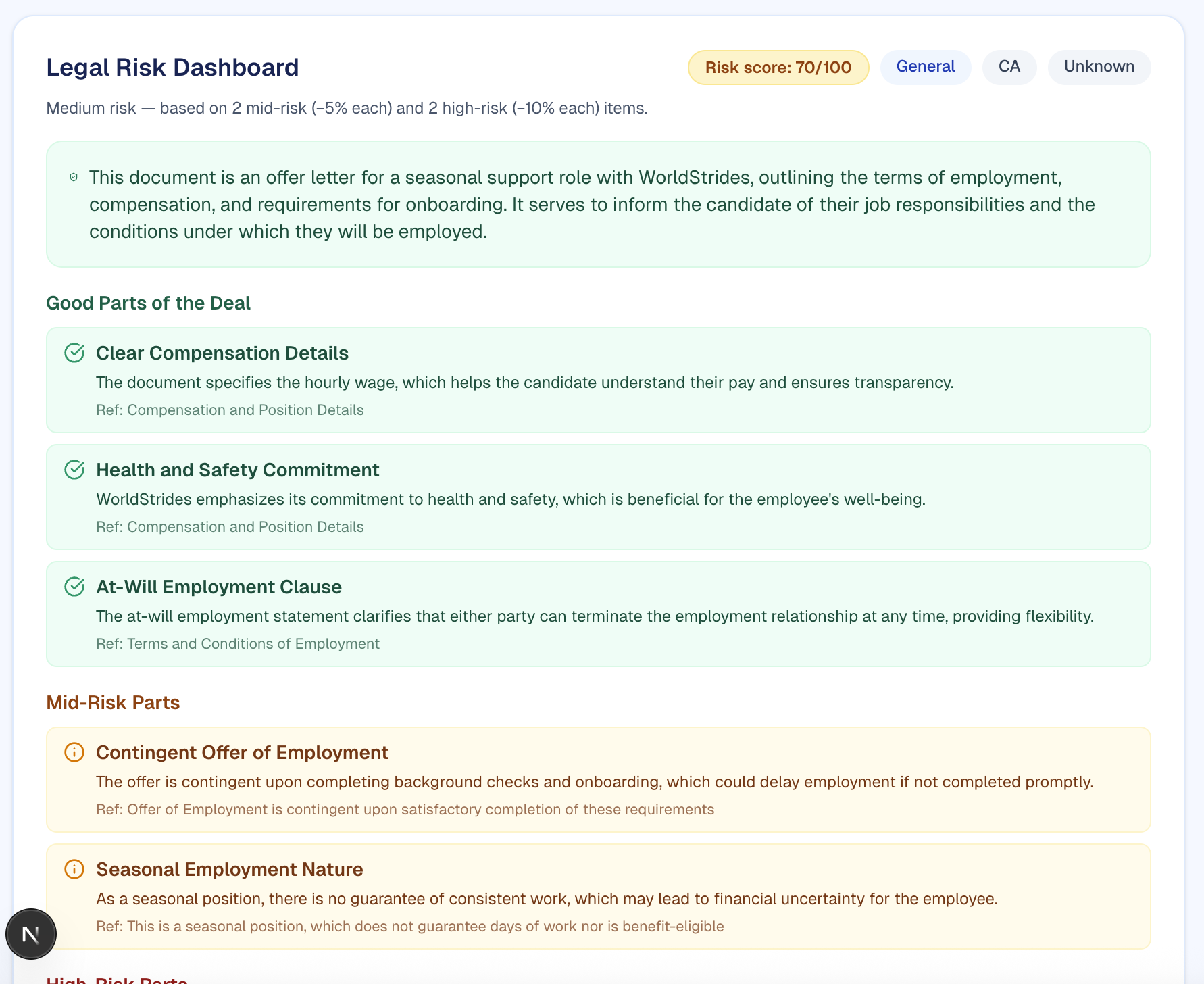
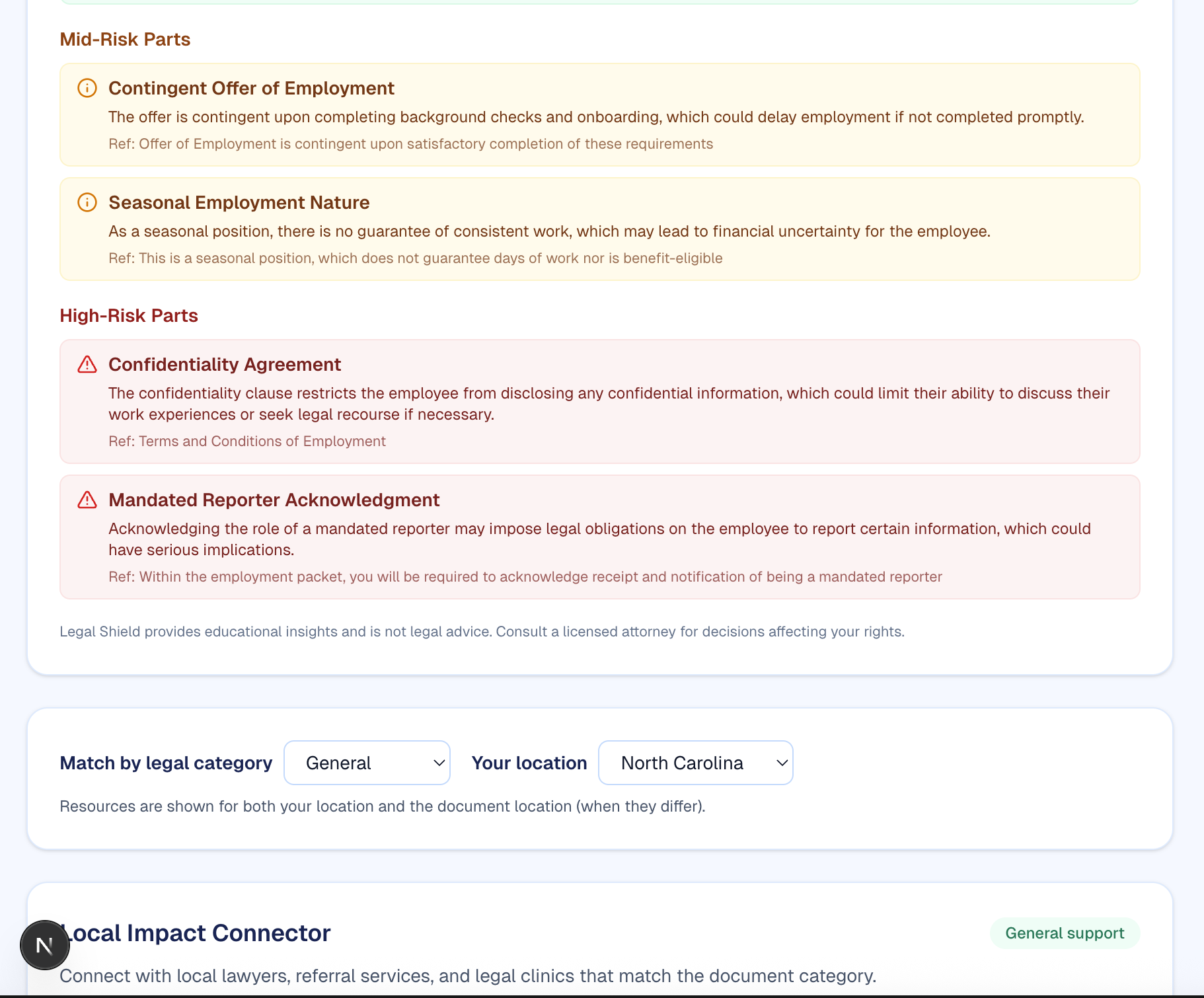
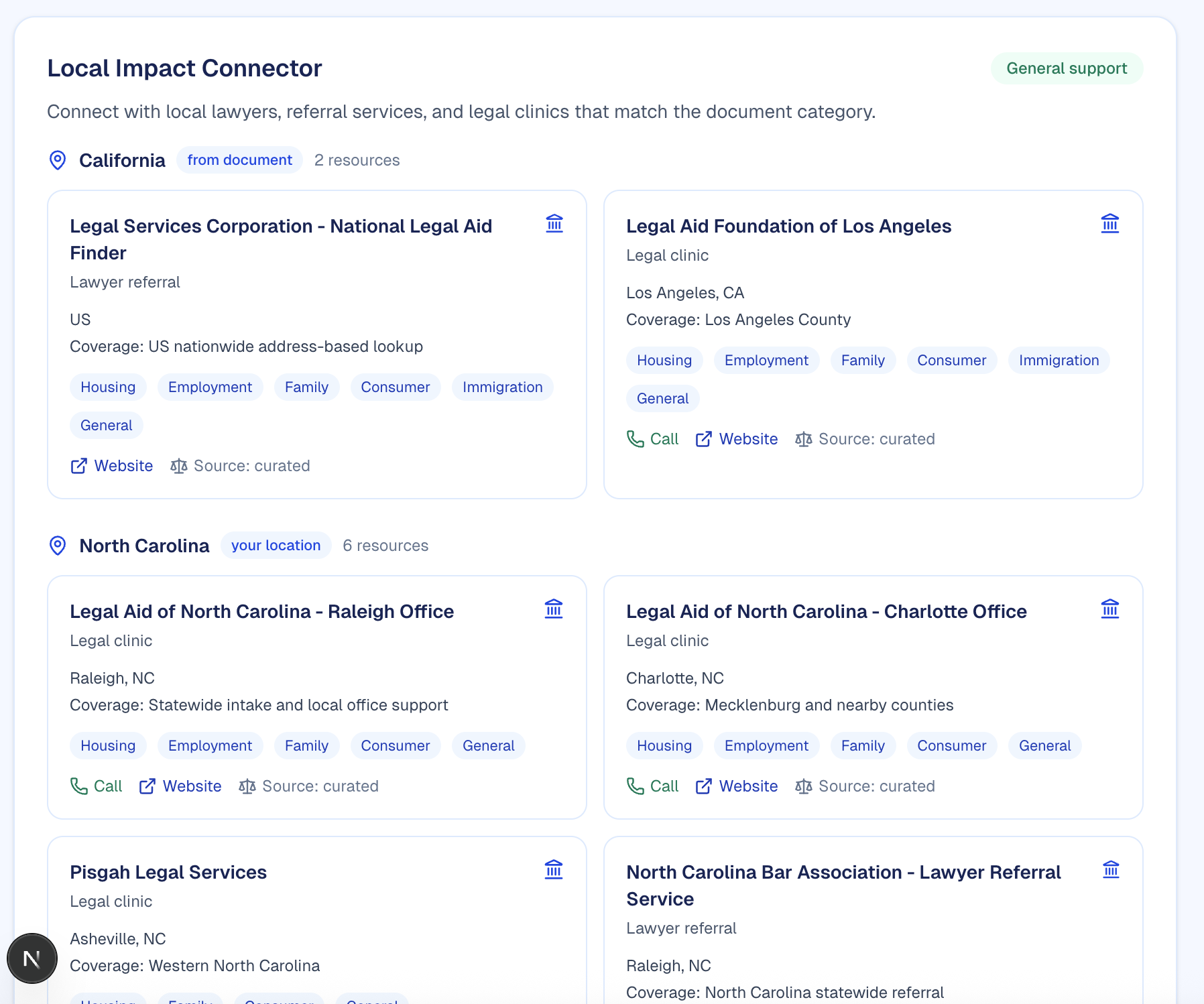
Legal Shield is an AI-powered legal assistant that helps users understand legal documents in plain language. Users can upload a document (PDF, Word, or text); the app converts it to structured text, checks that it’s actually a legal-style document (and rejects spam or off-topic uploads), then runs it through an LLM to produce a plain-English summary, risk tiers (good / medium / high), and highlighted clauses. A Legal Risk Dashboard shows risk and complexity scores on a 1–10 scale so users can see at a glance what needs attention. The Local Impact Connector maps users to real legal support lawyers and legal clinics by category and location using the Pro Bono Net Legal Organizations API (with curated fallback data), so understanding a document can lead to finding the right help.
How we built it
We built a modular full-stack pipeline:
- Frontend: Next.js (App Router) with TypeScript, Tailwind CSS, and Lucide icons. Mobile-first UI with deep blues, white backgrounds, and accent greens for a trustworthy feel. Drag-and-drop upload, analysis results, risk dashboard, and resource finder.
- Document ingestion: User uploads go to a FastAPI backend. We use MarkItDown to convert PDF, DOC, DOCX, and TXT into markdown so the rest of the pipeline works on clean text (with a length cap to keep prompts manageable).
- Classification (CPU-friendly): Before calling a large model, we run a lightweight classifier to ensure the content is legal-related. We support an optional GGUF model (e.g. Phi-3-mini) running on CPU; if no model is present, we fall back to keyword heuristics. Non-legal or spam uploads are rejected with a clear “we can’t provide this service” message.
- Analysis: A dynamic system prompt is built from the document type and context. We send the markdown to OpenAI (e.g. gpt-4o-mini) with a JSON response format to get a structured analysis: summary, document type, jurisdiction, category, and deal points grouped by risk (good_parts, mid_risk_parts, high_risk_parts).
- Legal resources: We maintain an internal DB of law-related resources (state and local government level). Analysis results are combined with this data and formatted for the dashboard; the frontend also calls Pro Bono Net (or fallback) so users can find lawyers and clinics by state and category (e.g. Housing, Employment).
- Resilience: Missing API keys or classifier model don’t break the app: we use heuristic classification and optional heuristic analysis so the demo still works.
Challenges we ran into
- Keeping the pipeline honest: We had to avoid sending random or non-legal content to the LLM. Adding a CPU-based classifier (with heuristic fallback) solved this but required careful prompt design and handling of “reject” cases in the UI.
- Structured LLM output: Getting consistent JSON (summary, risk tiers, deal points) from the model took iteration on the system prompt and response format; we added safe parsing and fallbacks when the model returned malformed JSON.
- Document diversity: Legal docs vary wildly in length and format. We introduced a text length cap, robust conversion with MarkItDown, and clear error messages for unsupported file types.
- External API dependency: Pro Bono Net can be down or rate-limited. We added curated fallback data and made the frontend work even when the external API is unavailable.
Accomplishments that we're proud of
- End-to-end flow: From file upload to plain-language summary, risk dashboard, and local resource lookup in one coherent product.
- Smart gating: CPU classifier (or heuristics) keeps the app focused on legal content and avoids wasting tokens on spam.
- Inclusive design: Mobile-first, clear typography, and category-based matching so users can find help by issue type and location.
- Demo resilience: The app runs with or without OpenAI keys and optional classifier model, so it’s easy to demo and iterate.
What we learned
- Small models are useful: A small CPU-bound model (or even heuristics) can reliably filter document type before calling a larger, costlier LLM.
- Structured outputs need guardrails: JSON-mode plus defensive parsing and default responses kept the product stable when the LLM occasionally misbehaved.
- Legal tech is about trust and next steps: Summaries and risk scores are only part of the value; connecting users to real resources (Pro Bono Net, local clinics) makes the tool actionable.
What's next for Legal Shield
- Richer resource data: Expand the internal DB and improve matching (e.g. by language, practice area, and availability).
- Better prompts and categories: Refine the analyzer for specific document types (leases, NDAs, employment) and more precise risk explanations.
- Optional GPU classifier: Support a small GPU model for classification to improve accuracy and support more languages.
- Accessibility and compliance: WCAG improvements, screen-reader testing, and clear disclaimers that Legal Shield is educational, not legal advice.
- User accounts and history: Let returning users save documents and analyses (with privacy and retention controls) so they can track changes and follow up with the same matter.
Built With
- fastapi
- llama-cpp-python
- lucide-react
- markitdown
- next.js
- node.js
- openai-api
- openrouter
- pro-bono-net-api
- pydantic
- python
- react
- tailwind-css
- typescript
- uvicorn


Log in or sign up for Devpost to join the conversation.