-
-
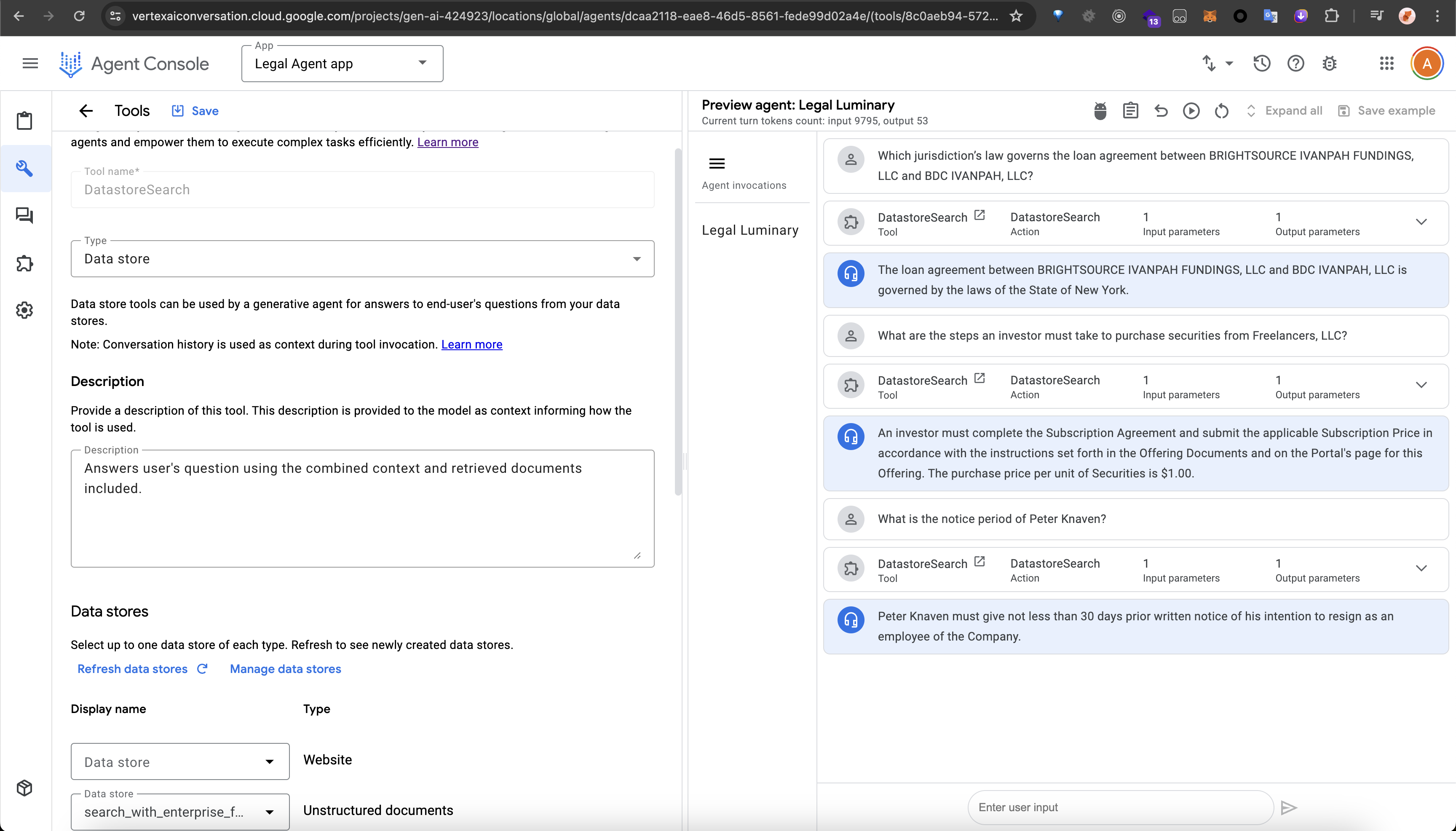
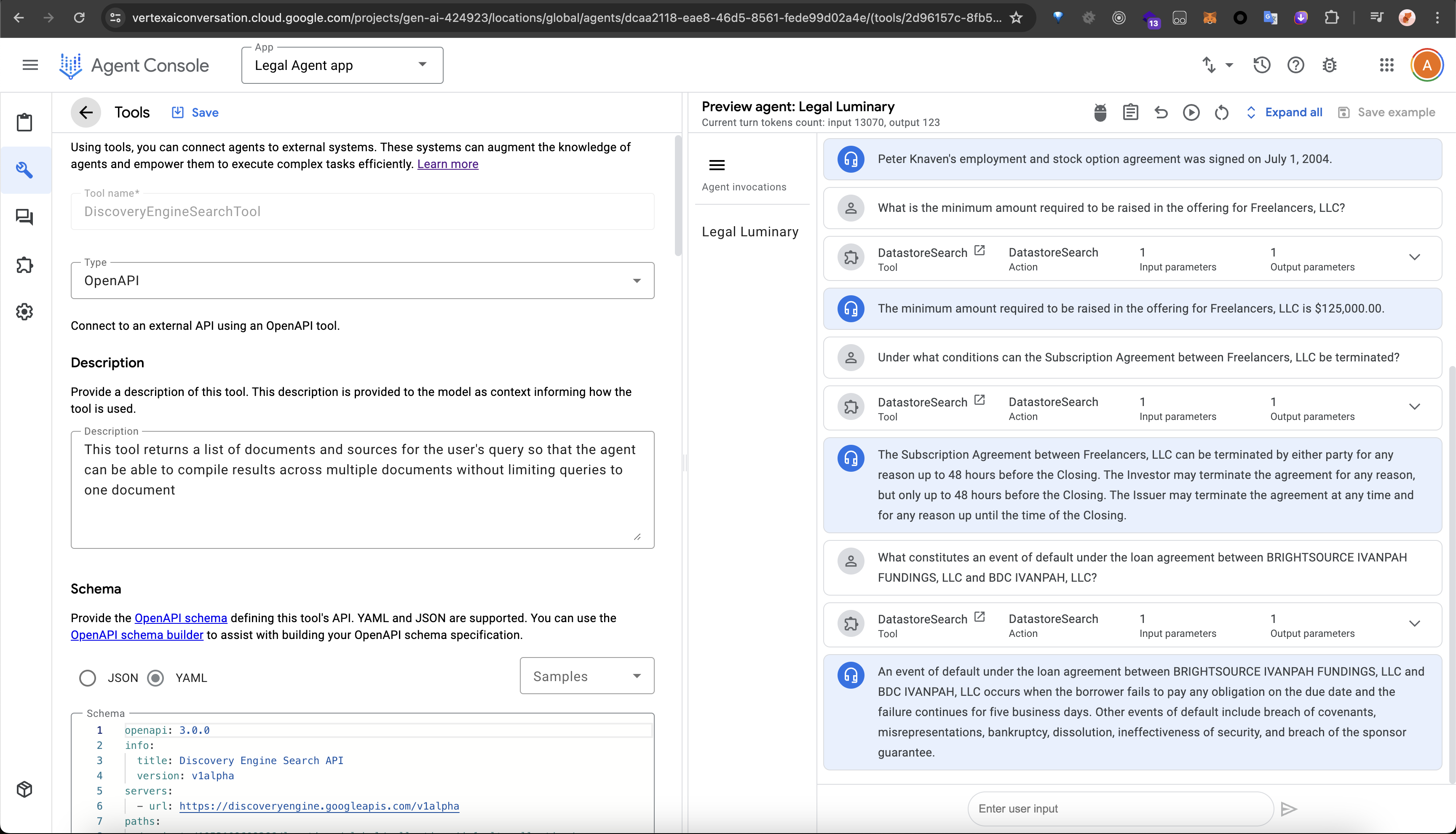
agent question
-
search data store tool
-
discover engine search api tool
Inspiration
"Justice delayed is justice denied." - How can we eliminate delays from document searching and find answers fast?
The legal field is overwhelmed with extensive documents that lawyers must review to find crucial information. This process is often time-consuming and tedious, potentially leading to missed details and decreased efficiency. The inspiration for Legal Luminary came from the desire to streamline this process, providing lawyers with a powerful tool to quickly query and retrieve information from their PDF, DOCX, or even scanned documents, thereby improving productivity and accuracy.
What it does
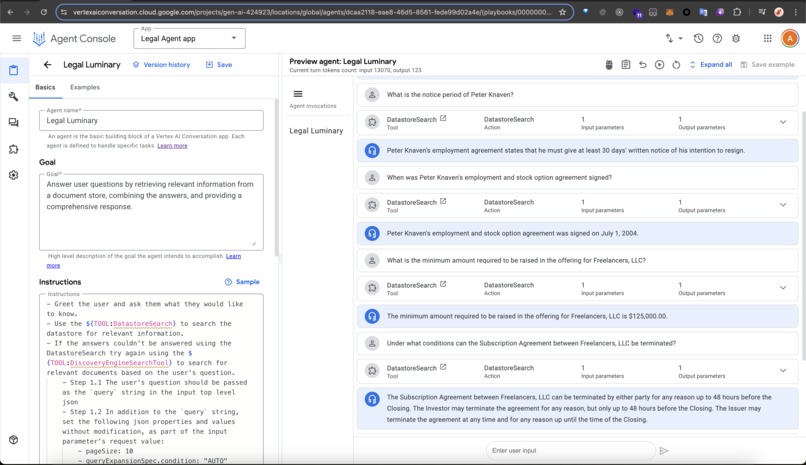
Legal Luminary is an AI-powered assistant designed to help lawyers chat with their documents and query them for information quickly. It allows users to ask questions and receive precise answers without manually searching through pages of text. This also works with physical/paper documents, as lawyers can scan them and the OCR parser support in Vertex data store takes care of it, so they don't have to read through a pile of papers to find answers.
How we built it
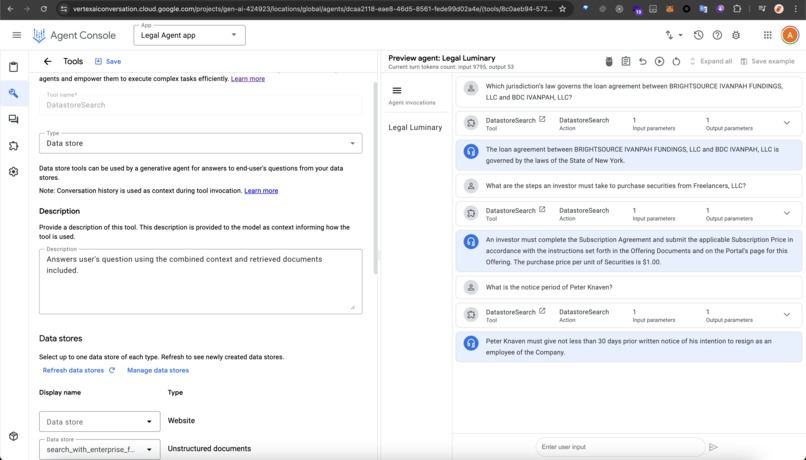
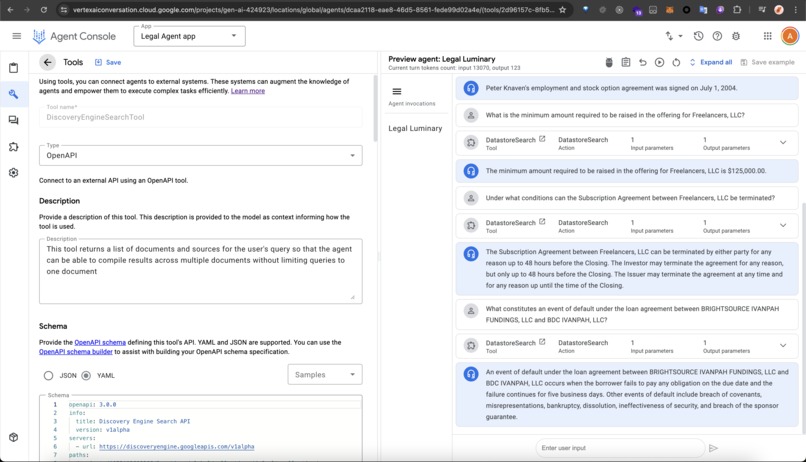
- Agent App: Built using Vertex AI Agent Builder and Datastore tool combined with a Discovery Engine Search OpenAPI tool implemented as a fallback to query the datastore directly with more fine-tuned criteria.
Challenges we ran into
Handling Compilation Queries Across Multiple Documents: Using the AI agent directly with the data store tool struggled to compile answers across multiple documents in one chat response, often responding that it can't make a list from multiple documents. For example, when asking the question "List all contractors on record." This is probably because the datastore tool uses a summary-based approach to get the result. This led to us adding a fallback implementation with the Discovery Engine Search API to query a separate data store. The data store was created via the search app to enable enterprise search features like extractive answers/segments on the document (a hack, shhh...).
Performance and Token Limits: Optimizing the system to manage large documents without exceeding token limits was crucial for maintaining performance and usability when using the Discovery Engine Search API. There was an issue using the API when
chunkingwas enabled, similar to this GitHub issue. However, using a datastore with chunking disabled worked as a quick fix but not the desired best result, as without chunking some queries can lead to exceeding the output token limit of 8192.
Accomplishments that we're proud of
Everything that has been done so far :) and the learnings!
What we learned
This was our first time using any Google AI tool, so it was quite interesting to see how much can be done with an Agent app using the Vertex AI Agent Builder. Looking forward to exploring the other app types in the Agent Builder console.
Seeing the possibilities of the Vertex AI Agent Builder tool was enlightening and motivating for future projects.
What's next for Legal Luminary
- Enhanced Multi-Document Compilation Query Support: Improve the AI’s ability to compile and synthesize information across multiple documents. Allowing users to request a list of data that cuts across multiple documents with improved inclusion of semantically relevant results.
- Combine the current RAG-based solution with general knowledge: This would allow comparison of case files to existing laws and generate answers or find similar public case files.
- UI Integration: Web UI integration with the ability to upload more custom documents.
- Langchain Integration via Custom API Server: Potentially ingesting to Vertex AI search store manually with Langchain and a suitable Vertex AI embedding model, and also doing the nearest k search on the code side for improved relevant search. This would make it possible to add support for compiling and aggregating results/answers across multiple documents, which is good for questions like "List all contractors on record".
Built With
- discovery-engine
- google-cloud
- vertex-ai



Log in or sign up for Devpost to join the conversation.