-
-
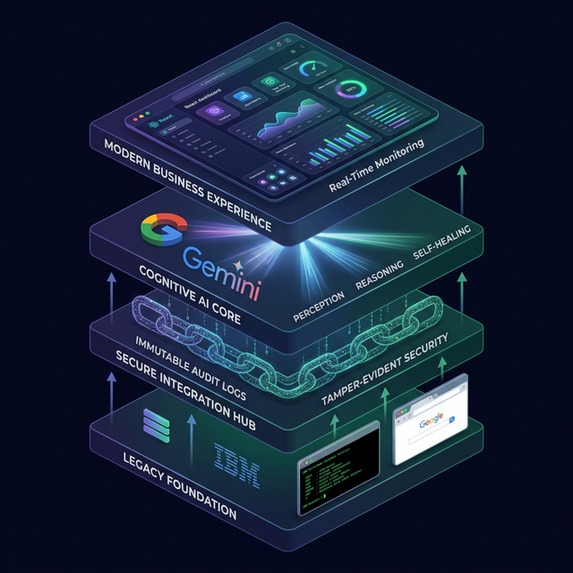
high level stack architecture diagram
-
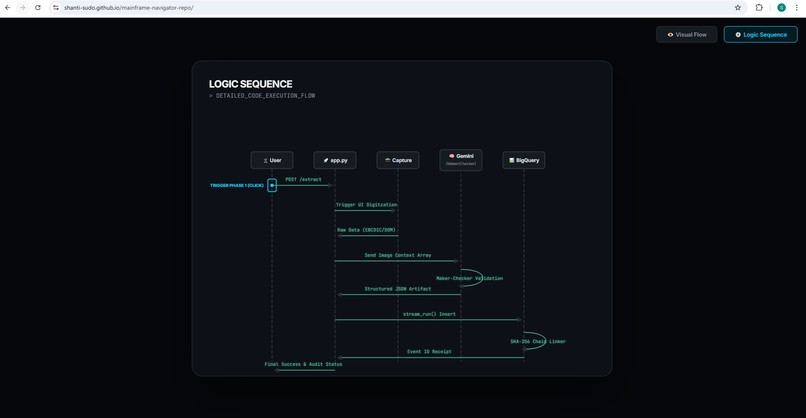
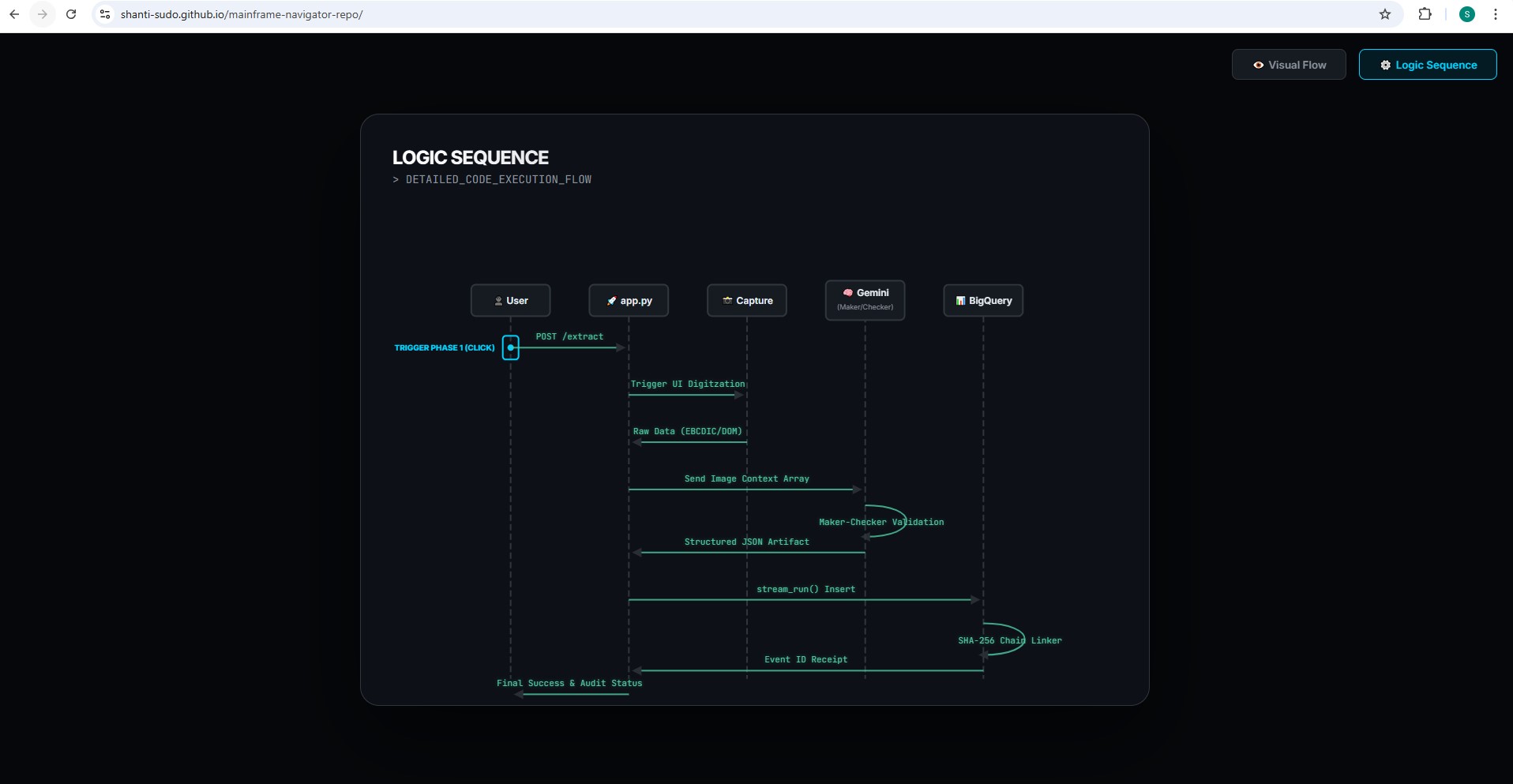
geminiliveagent-logic sequence-interactive-in-githubpage

🖥️ Mainframe Navigator ADK: Technical Summary
The Mainframe Navigator ADK is an AI-powered legacy modernization application. It serves as an autonomous agent that bridges the gap between legacy systems (like TN3270 mainframes) and modern data infrastructure (Google BigQuery) using multi-modal AI (Gemini Vision) and a React-based frontend dashboard.
🏗️ High-Level Architecture
The application acts as a middle-tier orchestrator that captures UI states from various environments, uses AI to extract structured data and reason about the UI, and streams the results into an immutable audit ledger in BigQuery.
Core Architecture Flow
- Frontend: A React (Vite) Single Page Application (SPA) dashboard serves as the user interface to trigger and monitor extraction missions.
- API Layer: A FastAPI backend that exposes endpoints for capture routing (
/capture), real-time status streaming (/stream-task), and data uploads. - Capture Environment Hooks:
- Mainframe:
x3270/s3270emulator wrapping for raw buffer access and grid scraping. - Web: Headless Chromium via Playwright.
- Desktop: Remote canvas / desktop coordinate capturing.
- Mainframe:
- AI/OCR Engine: Gemini Flash (Vision + Text) acts as the cognitive engine for spatial understanding, visual reading, and Optical Character Recognition.
- Data Layer: Google BigQuery is used for persistence. It stores structured UI telemetry and the extracted tabular data.
🔑 Key Technical Features
1. Multi-Modal Fallback (Maker-Checker Pattern)
The application utilizes a Maker-Checker pattern for high-confidence data extraction:
- Maker: First attempts to scrape data cleanly from the Mainframe buffer memory. If the buffer connection fails, the agent automatically falls back to taking a screenshot and using OCR via Gemini Vision to pull the data.
- Checker: An independent CheckerAgent audits the extraction against BigQuery to ensure no duplicates exist and enforces structural validation. If the Checker fails the audit, the insertion is automatically reverted.
2. Tamper-Evident Audit Trail
To ensure strict security and immutability for legacy audit logs:
- SHA-256 Hash Chaining: Every row inserted into BigQuery is cryptographically hashed with the preceding row, creating an unbreakable chain of evidence.
3. Delta Capture Deduplication
The system is heavily optimized to reduce Mainframe MIPS (Million Instructions Per Second) usage and BigQuery storage space:
- Delta Logging: The codebase implements logic to compare the last 50 BigQuery rows with newly extracted data. Only "Delta" rows (data that has actually changed) are uploaded, dropping identical consecutive buffers.
4. Autonomous Visual Self-Healing
If the Gemini-powered agent encounters mainframe system locks (X SYSTEM) or error text strings like "INVALID COMMAND", it triggers a recovery path:
- Synthesizes a recovery UI command (e.g., sending
PF3orClearcommands to the TN3270 buffer). - Resets the UI state completely autonomously without user intervention and attempts the scrape again.
5. Automated Legacy Mapping
The backend provides a /generate-navigation-map endpoint that queries historical UI telemetry from BigQuery. It passes chronological user actions (clicks, inputs, routing) to the Gemini model to synthesize Mermaid State Diagrams (stateDiagram-v2), effectively auto-documenting the legacy application's complex behavior flows.
🛰️ Technical Challenges & Engineering Innovations
Building a bridge between 40-year-old mainframe technology and cutting-edge AI presented several unique engineering hurdles.
1. The "Hallucination vs. Literalness" Tradeoff
- Challenge: Early iterations of the Gemini prompt occasionally inferred or "fixed" data (e.g., expanding partial names or adding relative dates like "3 months ago"), which broke deduplication checks and compromised audit integrity.
- Solution: We implemented Strict Literal Extraction rules and a normalization layer that strips relative time qualifiers. We also moved from exact-string matching to a Fuzzy Deduplication strategy using Cosine Similarity (threshold 0.98). This allows the system to identify "Delta" duplicates even if the AI's phrasing varies by micro-percentages.
2. Mainframe "System Locks" & Asynchronous UI
- Challenge: TN3270 terminals often lock the keyboard (
X SYSTEM) during processing or return unexpected error screens (INVALID COMMAND). Traditional RPA scripts would crash or hang at this point. - Solution: We engineered a Visual Self-Healing Loop. The agent "sees" the error state visually, synthesizes a recovery command sequence (e.g.,
Clear->PF3), and executes it autonomously to reset the buffer before attempting the extraction again.
3. Latency Optimization for Real-Time Interaction
- Challenge: Running multi-modal vision models can introduce several seconds of latency, which degrades the "real-time" feel of the dashboard.
- Solution:
- Pre-warming: The FastAPI context warms up the Agent singleton and the headless browser on container startup.
- Inline Streamlining: We switched from uploading temporary files to AI Studio to sending base64-encoded bytes directly in the reasoning request, shaving ~2 seconds off every extraction loop.
4. EBCDIC Character Normalization
- Challenge: Legacy data often contains non-printable EBCDIC artifacts or weird character encodings that break BigQuery's JSON parsing.
- Solution: We implemented a dedicated Normalization pipeline that executes immediately after the Perception step. It sanitizes non-printable characters and ensures the payload is 100% compliant with standard JSON/UTF-8 before it touches the database.
🛠️ Technology Stack Breakdown
| Domain | Technology / Library |
|---|---|
| Backend API | Python, FastAPI, Uvicorn, Server-Sent Events (SSE) |
| Frontend UI | React, Vite (served as static assets dynamically by FastAPI) |
| TN3270 Emulation | x3270 and s3270 |
| Web Scraping | Playwright (Chromium) |
| AI/LLM | Google Gemini (Gemini 2.0 / 3.0 Flash Vision for multi-modality) |
| Database/Audit | Google BigQuery |
| Cloud Infrastructure | Cloud Run (Serverless), Cloud Build (CI/CD), Artifact Registry |
🚀 CI/CD & Deployment Model
The application is fully containerized using a multi-stage Dockerfile. The CI/CD pipeline is orchestrated via cloudbuild.yaml:
- Builds the Node.js React frontend.
- Copies the static build into the Python container, installing
x3270, Playwright, and Python dependencies. - Pushes the image to Artifact Registry.
- Performs a zero-downtime deployment to Google Cloud Run.
A setup.sh script automates the generation of the GCP project environment, enabling required APIs, creating Service Accounts, and establishing IAM permissions roles (Data Editor, Cloud Run Admin, Vertex AI User, etc.).

Log in or sign up for Devpost to join the conversation.