-
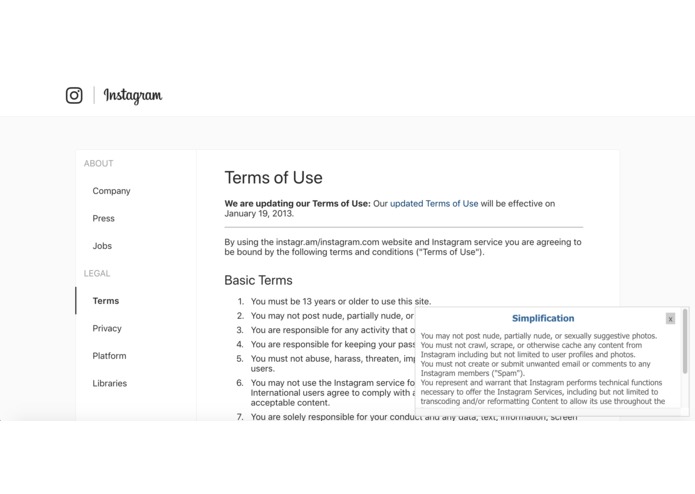
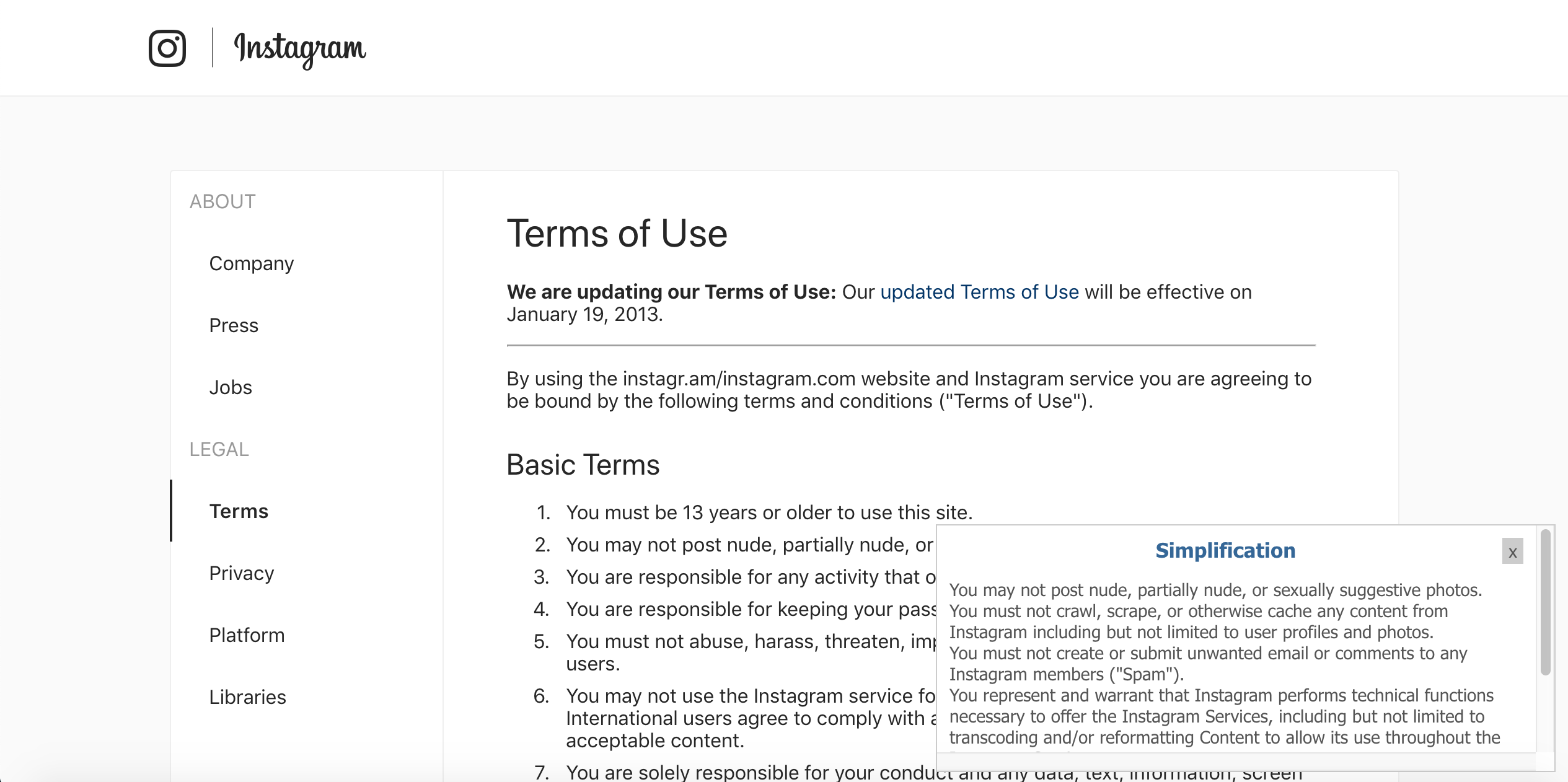
Instagram, simplified
-

Amazon, simplified
-
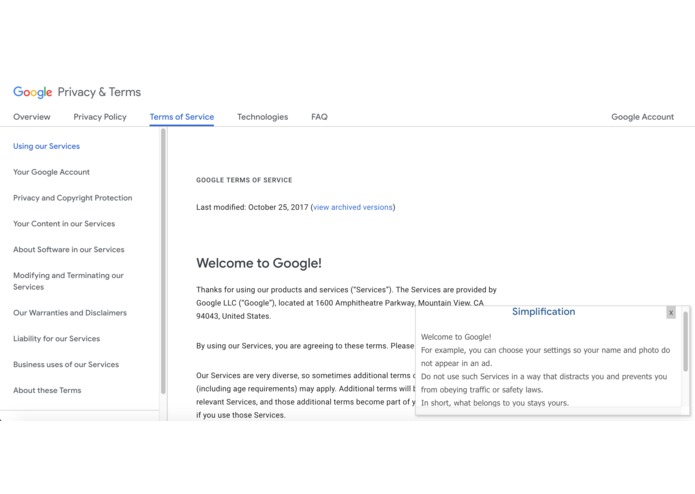
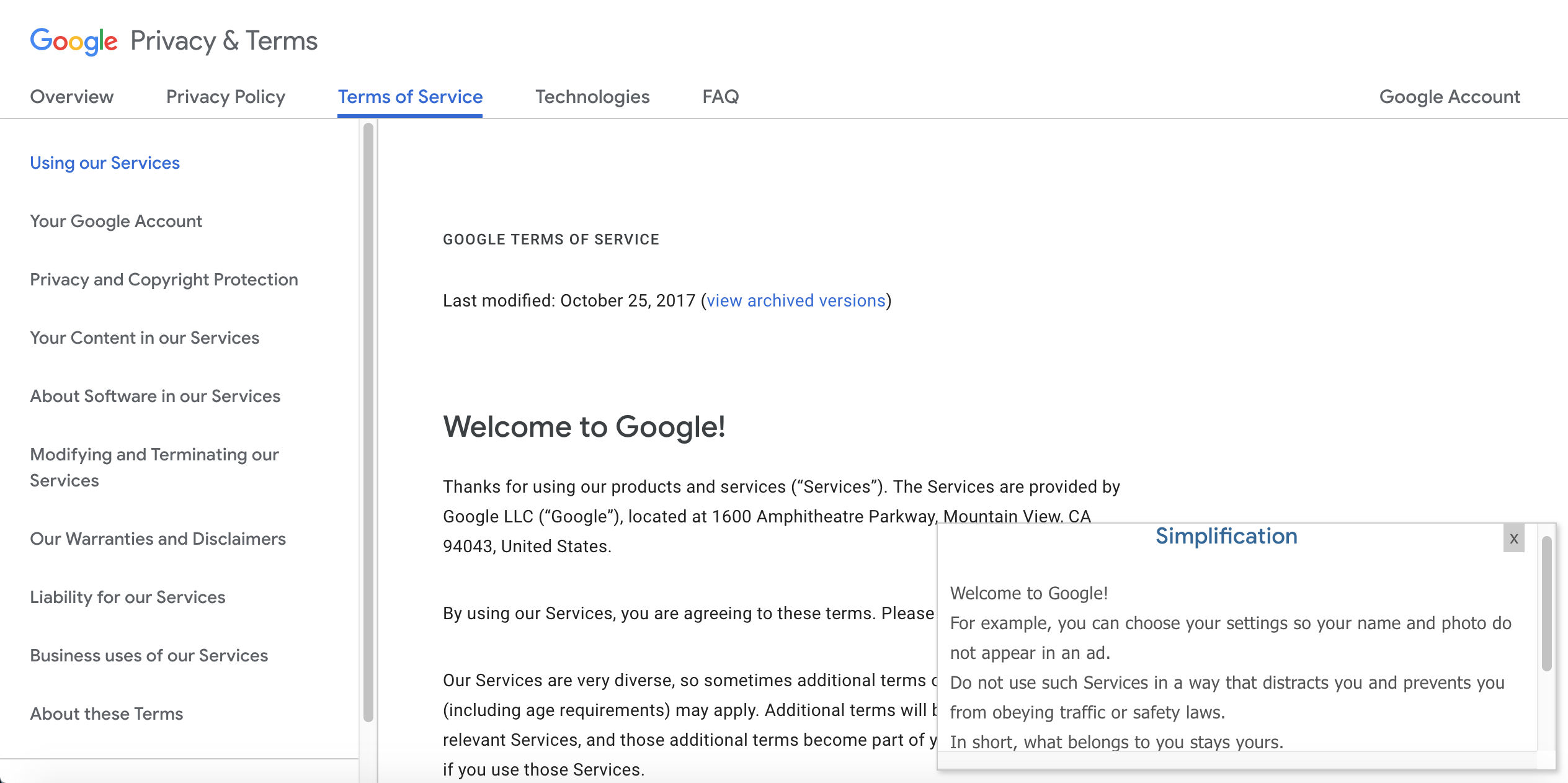
Google, simplified
-
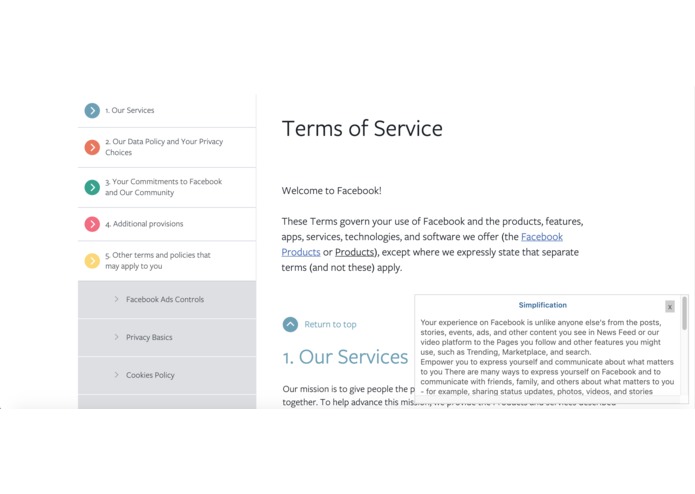
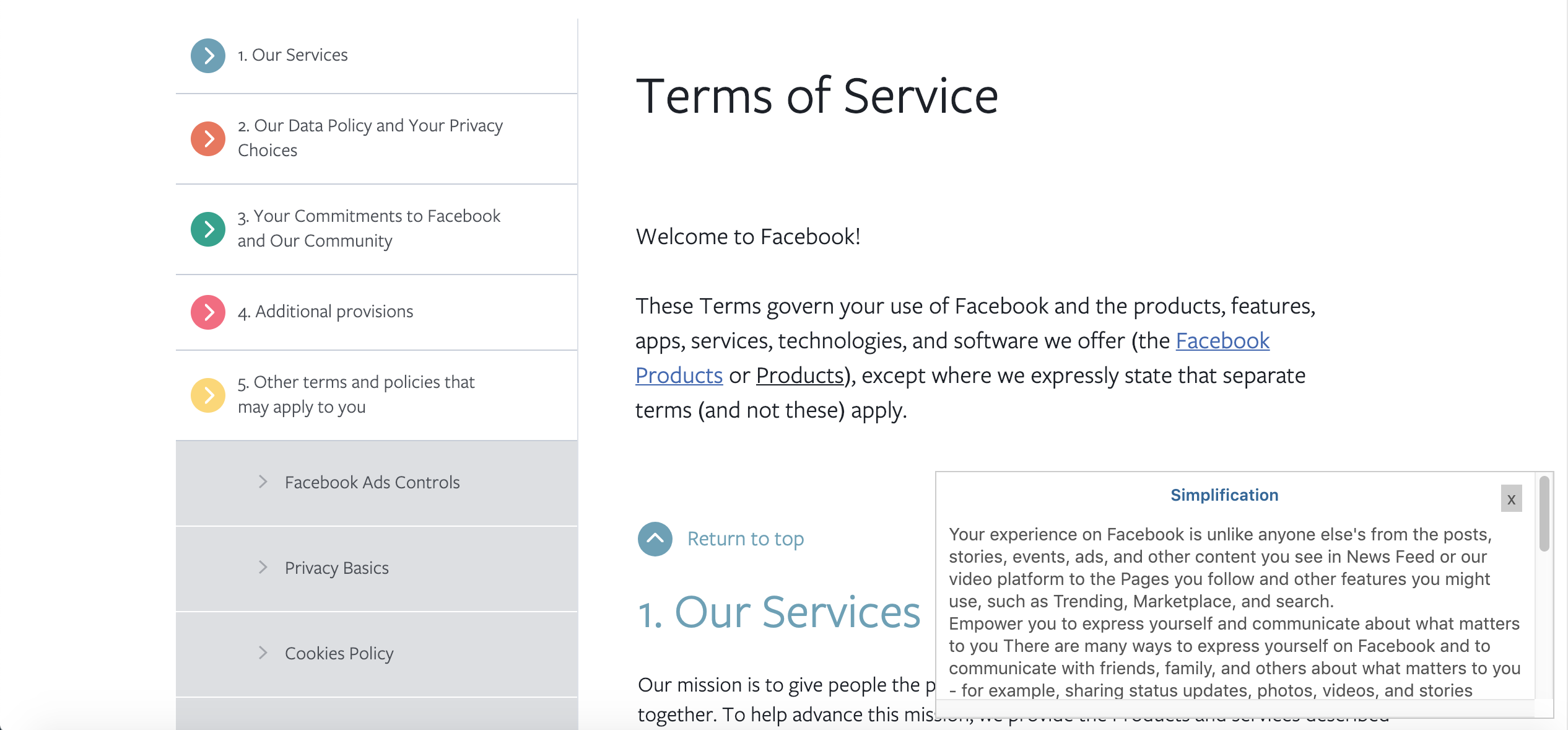
Facebook, simplified

Inspiration
We've all seen it: huge blocks of dense text that pop up before you install a new piece of software or sign up for a new service. These days, End User License Agreements are everywhere but most of the time are too long and full of jargon for consumers to feasibly read. We wanted to create something that would help consumers stay informed on what they are agreeing to and how their data is being used by companies.
What it Does
Our application, Lega-lies, finds the most notable sections of such a legal document — namely, sections which seem unusual and do not align with typical EULAs — and compiles them into a brief summary. It is a Chrome Extension that users can use directly from their browser when they encounter one of these legal documents. A user would highlight the text they wish to be summarized and would subsequently see a brief summary that lists the most noteworthy parts of the document.
How We Built It
We created an algorithm to process the text. It transforms the text into separate sentences and then transforms words to vectors based on a corpus of text of the English language taken from the NLTK module on Python. From there, we compare our sentences with sentences present in some standard EULAs. We use cosine similarity between vectors to find the sentences in our text that were most unusual given the ground truth and rank them.
Challenges We Ran Into
We ran into issues regarding parsing the text and figuring out where sentences ended. Many modern EULAs contain bullet points for readability which we lost when sending the information to the server and thus had to figure out when to cut off sentences. There are many edge cases that come up when trying to return text that is meaningful and readable and we attempted to address as many of these as possible.
Accomplishments that we’re proud of
We’re proud of the impact that this could have on millions of people being informed. Users cannot reasonably be expected to read dozens of pages of text for every product they use, but we hope to help prevent people from inadvertently agreeing to dubious privacy violations and signing away their rights.
What we learned
We learned about different natural-language processing algorithms including extraction and abstraction based algorithms through trying multiple approaches to designing our summarizing application. Our first attempt was a simple summarization algorithm which we soon figured out would not be the best with the eloquent speech of EULAs. From there, we learned about vectorized sentence similarity and based our application on this algorithm. We also learned about certain subtleties with processing language.
What’s next
Because some sentences in legalese tend to be extremely long, we would want to improve our algorithm further so that it could take the key takeaways from the sentence.
Built With
Python, Flask, NLTK, JavaScript, HTML, CSS

Log in or sign up for Devpost to join the conversation.