-

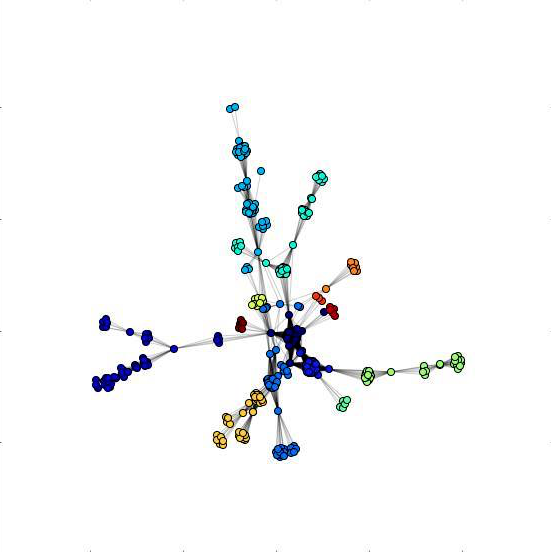
Overview of a co-authorship network
-

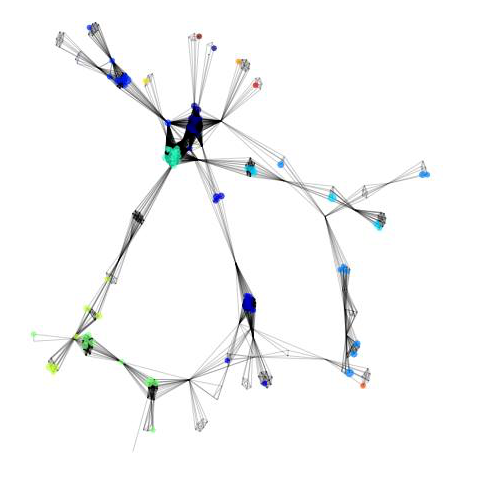
Community finding algorithm was used to detect researcher clusters
-

Assessing the importance of a collaborator.
-

Predicted future links
-

Granular community detection on a smaller-scale co-authorship network



Inspiration
As a consequence of the recent rapid growth of scientific articles in areas such as biomedicine, scientists are no longer able to manually inspect all relevant literature or to track their potential collaborators. Such problems are not new: the immense body of contents on social networks, news websites, online stores is managed by proprietary algorithms, which often tend to have their own additional goals. We believe that, when it comes to research, it is especially important to keep such recommendations transparent, while remaining useful. Over the course of the last 24 hours, we've made an early prototype of such product.
What it does
We are using the Mendeley Catalogue API to retrieve papers devoted to biomedical disciplines (e.g. genomics, drug discovery and development, chemical similarity). We are gathering some additional information (precise keywords) from the PubMed database. We utilise this information to create co-authorship networks – graphs where every node represents an author, and edges show co-authorship between two individuals. Through analysing the network topology, we are able to predict individuals who are important in their field, are able to bridge fields, as well as get a glimpse of how tight-knit is the field in general. Based on link prediction, we are trying to predict potential collaborations, hoping to benefit the research community.
How we built it
We've prototyped most of the code inside Jupyter Notebooks.
Challenges we ran into
Sanitising and combining data from two external databases. Difficulties with handling large-scale networks.
Accomplishments that we're proud of
Visualisation and analytics of scientific cooperation networks. We've applied a number of methods from network science to solve the problem:
- Louvain method for community detection and network clustering
- Adamic-Adar index for predicting how the network will evolve and to suggest potential collaborators
- HITS algorithm for calculating the "importance" of each collaborator
What's next for leev
We are hoping to turn the prototype into a project, publishing it online, and further improving the database.
Built With
- ipython
- jupyter
- mendeley
- networkx
- pubmed









Log in or sign up for Devpost to join the conversation.