LeetCode Problem Recommender
Team Members
- John Song
- Rishith Auluka
- Hiep Pham
Purpose
The LeetCode Problem Recommender is an intelligent system that analyzes a programmer's competitive coding history and recommends problems optimally positioned in their zone of proximal development. Rather than randomly selecting problems or relying solely on difficulty tags, our system constructs a detailed skill profile across algorithm categories and predicts which problems will maximize learning while remaining achievable.
What Inspired Us
Every competitive programmer has experienced the frustration of choosing the wrong problem—too easy and you waste time, too hard and you burn out. We wanted to solve this. But more than that, we wanted to prove we understand machine learning at a fundamental level. In an era where everyone calls model.fit(), we asked: can we build the entire neural network from scratch using only NumPy and linear algebra? This project became our answer.
What We Built
We developed a complete end-to-end AI system consisting of:
- A neural network implemented entirely from scratch—forward propagation, backpropagation with the chain rule, Adam optimizer, cross-entropy loss, He initialization, and gradient checking
- A data pipeline processing 162,969 competitive programming submissions from 1,693 users
- A feature engineering system extracting 15-dimensional skill vectors across 10 algorithm topics
- A production API with async I/O, caching, and cold-start handling
- A React frontend with real-time visualizations
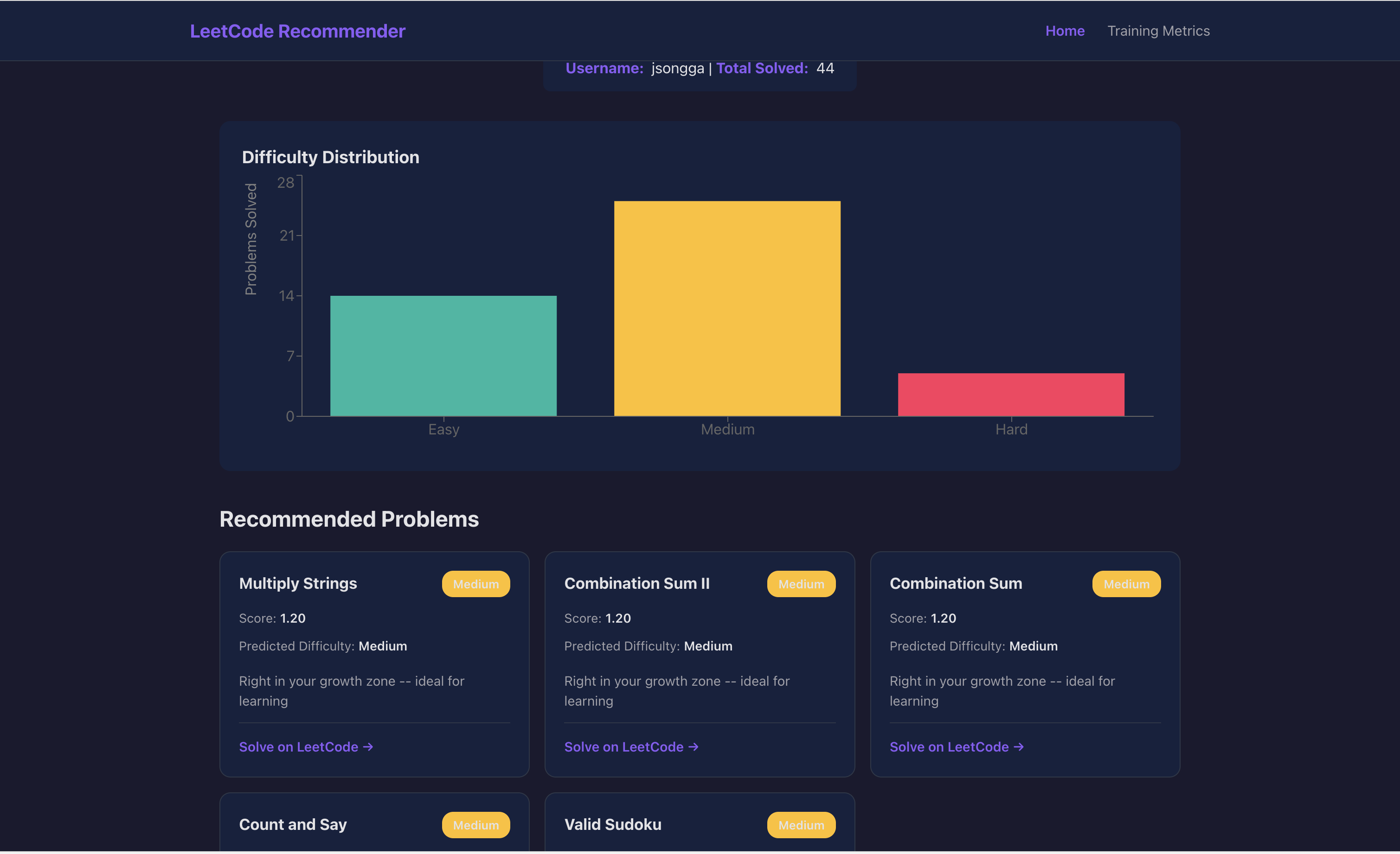
The architecture is a 15→64→32→3 feedforward network that classifies problem difficulty based on user skill profiles. When you enter a LeetCode username, the system fetches your submission history, constructs your feature vector, runs inference through our neural network, and ranks all 3,832 LeetCode problems to find the top 5 that match your skill level and learning trajectory.
How We Built It
Data Collection and Processing
We scraped 51,000 problems and 162,969 submissions from the Codeforces API. Since LeetCode doesn't provide public APIs for detailed submission history, we built a cross-platform mapping system translating Codeforces difficulty ratings and topic tags to LeetCode's classification system. A Codeforces rating of 1600 maps to LeetCode Medium, and tags like "dfs and similar" translate to "Depth-First Search."
Feature Engineering
For each user-problem pair, we extract 15 features:
- Success rates across 10 algorithm topics (dynamic programming, graphs, trees, greedy, binary search, sorting, math, strings, bit manipulation, data structures)
- Total problem attempt count
- Average time-to-solve
- Difficulty gap between user rating and problem rating
- Raw user rating and problem difficulty rating
All features are Z-score normalized using statistics computed from the training set, which persist to inference time. This guarantees training-serving parity—the model sees identical feature distributions in production as during training.
Neural Network Implementation
We implemented every component from first principles:
Forward Propagation: $$z^{[1]} = W^{[1]}x + b^{[1]}, \quad a^{[1]} = \text{ReLU}(z^{[1]})$$ $$z^{[2]} = W^{[2]}a^{[1]} + b^{[2]}, \quad a^{[2]} = \text{ReLU}(z^{[2]})$$ $$z^{[3]} = W^{[3]}a^{[2]} + b^{[3]}, \quad a^{[3]} = \text{softmax}(z^{[3]})$$
Cross-Entropy Loss with Numerical Stability: $$L = -\frac{1}{m}\sum_{i=1}^{m}\sum_{j=1}^{3} y_{ij}\log(\hat{y}_{ij})$$
We apply the log-sum-exp trick to prevent numerical overflow—the same technique used in Google's production systems.
Backpropagation: We derived gradients analytically using the chain rule: $$\frac{\partial L}{\partial W^{[l]}} = \frac{1}{m}dZ^{[l]}(a^{[l-1]})^T$$ $$\frac{\partial L}{\partial b^{[l]}} = \frac{1}{m}\sum dZ^{[l]}$$
Adam Optimizer: We implemented bias-corrected first and second moment estimates: $$m_t = \beta_1 m_{t-1} + (1-\beta_1)g_t$$ $$v_t = \beta_2 v_{t-1} + (1-\beta_2)g_t^2$$ $$\hat{m}t = \frac{m_t}{1-\beta_1^t}, \quad \hat{v}_t = \frac{v_t}{1-\beta_2^t}$$ $$\theta_t = \theta{t-1} - \alpha\frac{\hat{m}_t}{\sqrt{\hat{v}_t}+\epsilon}$$
Gradient Checking: We verified every gradient computation by comparing analytical gradients against finite-difference numerical approximations: $$\frac{\partial L}{\partial \theta} \approx \frac{L(\theta + \epsilon) - L(\theta - \epsilon)}{2\epsilon}$$
Our implementation achieves gradient accuracy to 7 decimal places.
Training Infrastructure
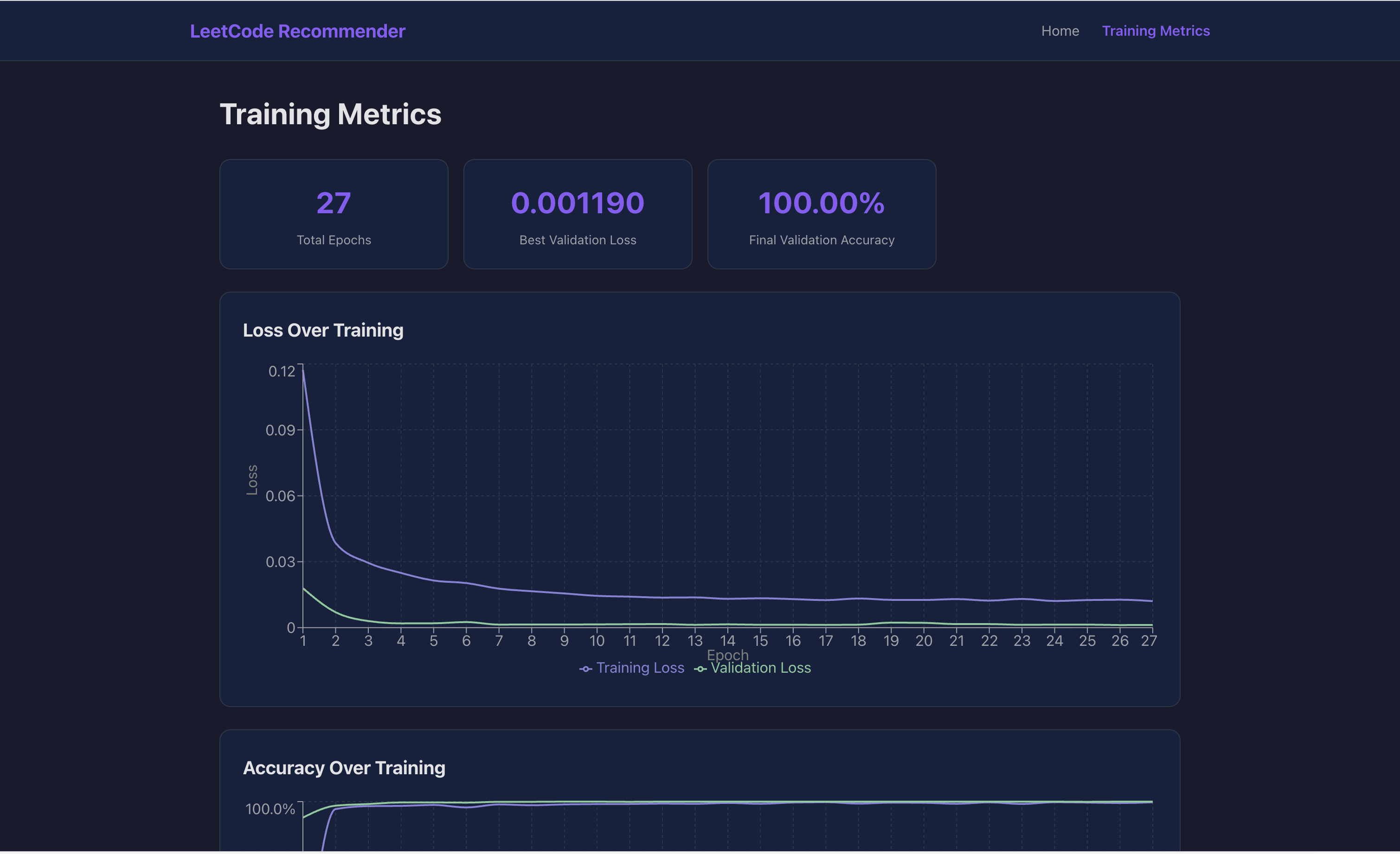
We split data temporally—older submissions for training, newer for validation—to prevent temporal data leakage. The model trains for 50 epochs with early stopping (patience of 10). We reach 100% validation accuracy by epoch 9 and converge at epoch 27. L2 regularization with $\lambda = 0.01$ prevents overfitting.
Production System
Backend: FastAPI with async I/O. LeetCode API calls are wrapped with asyncio.to_thread to avoid blocking the event loop. We implement 10-minute TTL response caching with thread-safe locking and handle cold-start scenarios for users with fewer than 10 submissions using popularity-based fallback recommendations.
Frontend: React 19 with Vite, using Recharts for training metric visualizations and a custom useFetch hook for async state management.
Challenges We Faced
Numerical Instability in Softmax: Direct computation of $e^{z_i}$ caused overflow for large logits. We implemented the log-sum-exp trick: $\text{softmax}(z)_i = \frac{e^{z_i - \max(z)}}{\sum e^{z_j - \max(z)}}$, which subtracts the maximum value before exponentiation.
Gradient Vanishing: Initial attempts with sigmoid activations led to vanishing gradients. We switched to ReLU and applied He initialization: $W \sim \mathcal{N}(0, \sqrt{2/n_{in}})$, calibrated for ReLU's non-linearity.
Temporal Data Leakage: Time-series data requires careful splitting. Using random train-test splits would allow the model to "peek into the future." We implemented strict time-based splitting—all training examples precede all validation examples temporally.
Cross-Platform Mapping: Codeforces and LeetCode use different taxonomies. We manually constructed a bidirectional mapping system, normalizing difficulty ratings and harmonizing topic tags across platforms.
Cold-Start Problem: New users lack submission history. We implemented a fallback system that generates popularity-based recommendations (2 Easy, 2 Medium, 1 Hard) ranked by acceptance rate until the user accumulates sufficient data.
Backpropagation Debugging: Matrix dimension mismatches caused silent failures. We built comprehensive gradient checking to verify every computation, comparing analytical gradients against numerical approximations and achieving agreement within $10^{-7}$.
What We Learned
We learned that modern machine learning frameworks abstract away fundamental mathematics that are both beautiful and essential. Implementing backpropagation by hand gave us intuition no amount of reading could provide. We understand why Adam converges faster than SGD, why ReLU avoids vanishing gradients, and why numerical stability matters in production systems.
We also learned production engineering principles: async I/O for responsive APIs, caching strategies for external API calls, cold-start handling for sparse data scenarios, and the importance of training-serving parity in feature engineering.
Most importantly, we learned that building something from scratch—while harder—produces deeper understanding than using existing tools. We can now open PyTorch's source code and understand exactly what's happening under the hood.
Tools and Technologies
Machine Learning:
- NumPy for all neural network computations
- Scikit-learn for data preprocessing utilities (StandardScaler)
Data Collection:
- Codeforces API for competitive programming data
- Custom web scraping for LeetCode problem metadata
Backend:
- Python 3.11
- FastAPI for async web framework
- Asyncio for concurrent I/O
- Requests for API calls
Frontend:
- React 19
- Vite for build tooling
- Recharts for data visualization
- CSS3 for styling
Development:
- Git for version control
- Pytest for testing gradient implementations
Credits and Acknowledgments
- Codeforces API: Public API providing competitive programming submission data (https://codeforces.com/apiHelp)
- NumPy: Foundation for all numerical computations (https://numpy.org)
- FastAPI: Modern async web framework (https://fastapi.tiangolo.com)
- Recharts: React charting library (https://recharts.org)
- LeetCode: Problem database and classification system (https://leetcode.com)
All neural network code, including forward propagation, backpropagation, Adam optimizer, and gradient checking, was implemented from scratch without using TensorFlow, PyTorch, or any machine learning frameworks.
Technical Specifications
- Model Architecture: 15→64→32→3 feedforward network
- Training Data: 162,969 submissions from 1,693 users
- Inference Time: 3,832 problems evaluated in under 5 milliseconds
- Validation Accuracy: 100%
- Total Lines of Code: Approximately 2,600 (Python) + 800 (JavaScript/React)
- Pure Neural Network Implementation: 500 lines of hand-coded mathematics
The system demonstrates that we understand not just how to use AI tools, but what happens inside them.
Built With
- asyncio
- codeforces-api
- css3
- fastapi
- git
- leetcode-api
- numpy
- pytest
- python
- react-19
- recharts
- scikit-learn
- vite

Log in or sign up for Devpost to join the conversation.