Inspiration
“You can outsource your thinking, but you cannot outsource your understanding.” — Andrej Karpathy
Coding agents make it possible to ship software faster than ever. But speed can hide a new kind of technical debt: code that works, but that its developer never built the mental model to maintain.
We felt this firsthand. Under pressure to ship, it is easy to let Claude Code make one more decision, resolve one more failure, or explain one more unfamiliar subsystem. Each interaction is productive. Over time, though, even a capable developer can become a fragile expert: able to build with an agent, but unable to safely operate the resulting system without it.
Anthropic's study, “How AI assistance impacts the formation of coding skills”, made the risk concrete. In its randomized trial, the AI-assisted group scored about 17 percentage points lower on a comprehension assessment than the group that coded by hand. The largest gap was in debugging—the exact skill developers need when AI-generated code fails.
That led us to Ledger: a tool that does not ask developers to stop using coding agents, but makes sure they still own what they ship.
What it does
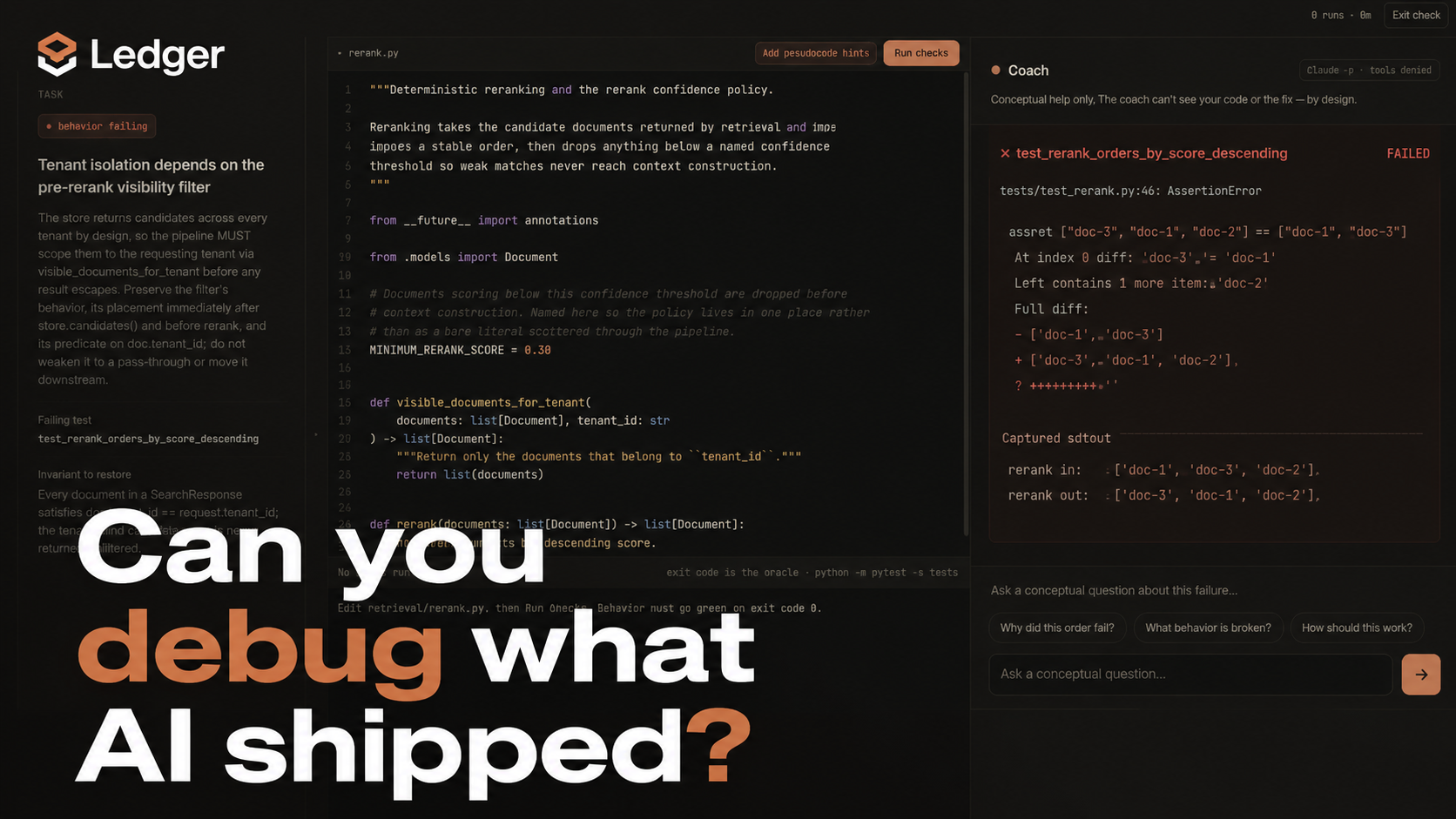
Ledger is a local Claude Code companion that maintains an ownership ledger for AI-assisted code.
It indexes a repository's code, tests, Git history, documentation, and local Claude Code sessions. A read-only Claude Topic Analyst investigates that evidence and proposes an ordered worklist of decisions a maintainer may need to own: a tenant-isolation boundary, a confidence cutoff, a context-window rule, or another choice whose failure would matter. Deterministic code then resolves every cited file, line, and trace segment before the proposal can become part of the ledger.
The dashboard keeps the result deliberately modest. Each row shows the Topic, its observable ownership status, a verified evidence summary, and a categorical impact level. Ledger never claims, “You do not understand this.” It says, “Ownership check recommended,” then lets the developer test the question directly.
A Topic page explains the maintenance obligation and its consequences, then progressively reveals the evidence behind it:
- Code anchors: the exact repository locations that encode the decision.
- Agent trace: the relevant prompt and tool-call sequence read from the developer's real local Claude Code session—not a fabricated chain of thought or a committed transcript fixture.
- Ownership history: prior checks, attempts, elapsed time, conceptual help used, and whether the code changed afterward.
When a developer starts a check, they choose a level:
- Easy is recognition-focused.
- Medium combines conceptual questions with guided debugging.
- Hard goes directly to the sandbox with less scaffolding.
For the working prototype, Claude generated the topic-specific question plans, which are cached for demo reliability. Debugging checks create a temporary copy of the Python demo repository and inject a curated semantic defect targeted at the selected Topic. The developer must inspect the failure, edit the code in an embedded code workspace, and make the real pytest suite pass.
A built-in Claude coach can explain concepts, ask diagnostic questions, and suggest observations. It cannot provide the patch. Ledger launches the coach through the user's existing Claude Code CLI, gives it the Topic and test failure but not the original implementation or mutation diff, and denies all file, shell, search, and web tools. The developer can select Claude Haiku, Sonnet, or Opus without weakening that boundary.
When the behavior is restored, Ledger records an ownership event. Green tests are necessary, but Ledger does not turn them into a claim of mastery or an opaque score. It preserves the observable cost of getting there.
Ledger also stays close to the development loop. Its Claude Code SessionStart hook quietly lists ready checks for the current repository with deep links into the relevant Topic. Hooks never block Claude Code or Git; if Ledger is unavailable, events spool locally.
In short: Ledger finds load-bearing code decisions with thin evidence of ownership, then asks you to prove you can still operate them—by breaking one and making you fix it.
How we built it
Ledger is a local-first web application with a Python-first architecture:
- FastAPI provides the backend and REST API.
- React and Vite power the worklist, Topic page, and ownership-check workspace.
- A custom React editor provides the embedded code-editing experience.
- SQLite stores projects, evidence, Topics, revisions, checks, and attempts locally.
- Claude Code and Git adapters normalize development activity into provider-labeled evidence.
- Claude Code and Git hooks capture activity and surface relevant checks without interrupting normal work.
For the demo, we used one real Git repository: a small Python documentation-search service with retrieval, reranking, tenant isolation, and context-packing decisions. The seeded worklist was captured from a live Claude Opus analysis of that repository. The committed seed contains code anchors and cached exercise plans, while the Agent trace is loaded live from the real Claude Code sessions on the machine. Each of the three demo Topics has a curated, topic-specific mutation caught by the repository's real tests.
Challenges we ran into
Our first idea was to infer cognitive offloading from Claude Code conversations. We built an engagement classifier to distinguish thoughtful use from passive delegation. It failed. Even with full transcripts, the signal was too ambiguous to support a trustworthy judgment.
That failure changed the project. We stopped trying to infer a developer's internal state from chat behavior and moved toward observable repository evidence plus performance in a real task.
Topic selection created a second problem. An early deterministic approach used syntax and code fan-in as proxies for importance. It surfaced generic helpers such as get, set, and render: frequently used code, but not necessarily meaningful decisions. The current architecture lets Claude investigate the bounded repository context and identify defendable maintenance obligations, while deterministic verification prevents uncited model claims from becoming facts. That division proved much stronger than asking either heuristics or an LLM to do both jobs.
Provenance was also harder than it looked. A session that touched a file does not prove that every decision in that file came from Claude. Ledger therefore treats the Agent trace as supporting evidence, attaches explicit link confidence, and never uses AI authorship to validate a Topic or grade a check.
Verification presented a different trap. An LLM-graded explanation felt subjective and easy to bluff, so we built Debug-to-Own around real code and tests. A spike then showed that fixing a mutation still does not prove ownership: elapsed time can be dominated by how widely the mutant breaks the suite, and a subtle operator swap may test visual search rather than understanding. Ledger therefore records struggle as evidence, avoids a universal score, and keeps the demo mutations narrow and decision-specific.
Finally, we had to build an AI coach that helps without taking over. Prompt instructions alone were not a meaningful safety boundary. Withholding the solution context and denying Claude's tools made the restriction architectural.
Accomplishments that we're proud of
We are proud of building the complete end-to-end workflow. Ledger connects a non-blocking Claude Code hook, an evidence-backed worklist, exact code anchors, a live prompt-and-tool-call Agent trace, difficulty-aware checks, a real mutated sandbox, an embedded editor, a restricted conceptual coach, and persistent ownership history in one experience.
Claude Code is native on both sides: it supplies the development receipts and performs the semantic repository investigation, then becomes a coach whose permissions prevent it from completing the exercise for the developer.
Most importantly, Ledger is pro-AI without being uncritical. Claude Code makes developers faster. Ledger is designed to make sure they can still maintain what they ship.
What we learned
The hardest part of building a tool for understanding is that understanding is not directly observable. Conversation patterns, confidence, and successful task completion are all imperfect proxies. A responsible product should not turn those proxies into a confident verdict.
We also learned that the verifier is not the whole product. A developer can already ask Claude to explain a file. The harder and more valuable problem is allocating limited attention: selecting which decisions across an entire repository deserve a check, remembering what has already been practiced, and resurfacing a Topic when its code changes.
Productive friction is part of the design. Coding agents optimize for removing friction, but some struggle—forming a hypothesis, running an experiment, and debugging a failure—is how a developer builds the model needed to maintain a system later. The goal is not to maximize friction. It is to spend it selectively on decisions important enough to justify it.
Finally, scope and disclosure mattered. Live agent analysis is variable, so the demo worklist and Claude-generated questions are cached from real runs. General mutation generation and arbitrary-repository sandboxing were not realistic in one hackathon, so the demo uses curated mutations against one real, testable Python repository. Keeping that boundary explicit made the working system more credible.
What's next for Ledger
The next step is to turn the working point-in-time prototype into a continuously reconciled ownership ledger.
Ledger should preserve stable Topic identities across renames and revisions, retain immutable worklist snapshots, and resurface a practiced decision when its implementation changes. Discovery can remain an expensive, evidence-gathering pass while a cheaper context-aware ranking pass decides what matters for the current branch and path.
We also want to replace curated mutations with automatic generation guarded by baseline-green, mutant-red, narrow-failure, and non-equivalence checks, then add sandbox adapters for other popular languages and runtimes such as TypeScript and C/C++.
Longer term, Ledger can support additional coding agents and help developers ramp into unfamiliar codebases by turning important architectural decisions into targeted, evidence-backed practice. Teams could share learning milestones, but ownership history should never become an employee performance score. Developers need to trust that Ledger exists to help them learn, not to surveil them.
The broader problem is not limited to coding. As agents move into research, operations, finance, medicine, design, and engineering, verification often gets harder, not easier. Many domains do not have a pytest suite waiting at the end. Ledger starts with code because it gives us commits, tests, and source anchors, but the larger goal is to keep humans informed enough to challenge, debug, and operate the systems agents help create.
Considerations
Ledger was motivated by an ethical concern with AI-assisted development: cognitive outsourcing can increase productivity while weakening critical thinking, debugging ability, and long-term skill development. Ledger preserves human agency by making AI-generated decisions inspectable and asking developers to actively diagnose and repair behavior instead of delegating the solution back to AI.
Privacy is addressed through a local-first architecture. Repository evidence, Claude Code traces, user activity, and ownership history remain on the developer’s machine in SQLite. Ledger adds no cloud database, telemetry service, or AI provider beyond the developer’s existing Claude Code relationship with Anthropic. Its Claude calls still cross that existing provider boundary, so model access is tightly scoped: the analyst is read-only and limited to the enrolled repository, while the coach cannot read files, run commands, search the web, or access the original solution.
Ledger also avoids turning imperfect signals into judgments about people. It does not claim that a developer lacks understanding, calculate an opaque “ownership score,” or treat passing a check as proof of mastery. It recommends checks and records observable evidence such as attempts, test results, assistance used, and code freshness. Ownership history is intended for personal learning—not employee surveillance or performance evaluation.
Built With
- claude-code
- fastapi
- monaco
- python
- react
- sqlite
- typescript
- vite

Log in or sign up for Devpost to join the conversation.