Inspiration If you look at a blockchain ledger, what do you see? Cold, sterile rows of hex codes, timestamps, and floating-point numbers. But behind every transaction is a human story—a high-stakes trade, a desperate gamble, or the quiet accumulation of a whale.
We realized that current AI text generators don't do justice to this data, and most "multimodal" apps just slap an image at the end of a blog post. We wanted to build a True Multimodal Creative Director Agent—an AI that doesn't just read data, but feels it, seamlessly weaving together text, generated imagery, and stylized voiceovers into a single, cohesive cinematic storyboard. We wanted to make the ledger speak.
What it does Ledger Bard is an interactive, multimodal AI Co-Director that transforms raw blockchain wallets into fully voiced, visually stunning cinematic storyboards.
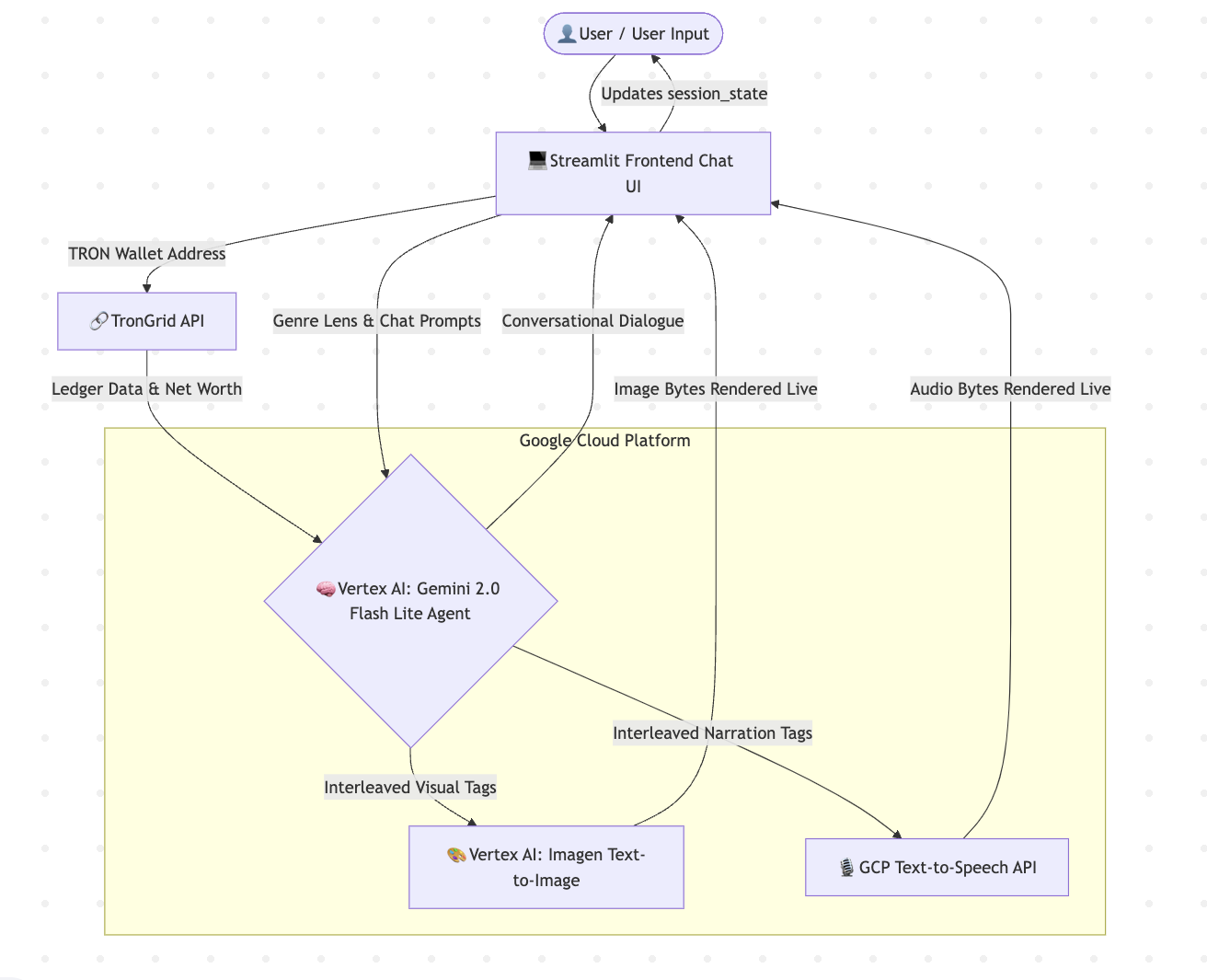
Uplink & Analyze: You input a TRON wallet address. The app pulls real-time ledger data, calculates the net worth, and assigns a psychological "vibe" to the wallet (e.g., "The Whale," "The Scavenger," "The Bot"). Future Prediction Matrix: It extrapolates a 5-year financial trajectory based on their genuine transaction history. Interleaved Multimodal Orchestration: As you chat with the agent to guide the narrative, it leverages Gemini to generate an interleaved media stream. For every scene, it outputs dialogue, triggers specific text-to-image prompts, and formats voiceover scripts simultaneously. Cinematic UI: The app parses these interleaved tags live, instantly rendering 8k cinematic visuals (via Imagen) and neural voiceovers (via Google TTS) perfectly matched to the aesthetic genre chosen by the user (e.g., Cyberpunk Noir, 80s Anime). How we built it We built the platform entirely on Google Cloud to ensure enterprise-grade multimodal capabilities:
The Brain: We used Vertex AI (Gemini 2.0 Flash Lite) as the core orchestrator. We used advanced system prompting to force the agent to format its output with strict interlocking media tags (🎙️ NARRATION and 🎨 VISUAL) tied strictly to actual NUMERIC DATA. The Visuals: We routed the agent's textual visual prompts into Vertex AI's Imagen 4.0 model to generate aspect-ratio-locked, cinematic 16:9 shots. The Audio: We integrated Google Cloud Text-to-Speech API, dynamically changing the neural voice model (US/GB accents, pitch, rate) based on the "Genre Lens" the user selects. The Frontend: Built with Python and Streamlit. We utilized deep st.session_state management to maintain a live chat interface that successfully caches heavy image bytes and audio binary data so the user can scroll back through their generated storybook without re-triggering API calls. Challenges we ran into Enforcing Interleaved Output: Initially, the LLM wanted to write the whole story first, and then list image ideas at the bottom. We had to heavily iterate on the System Prompt to force the agent to act as a "Director" that intertwines the narrative and visual cues sequence-by-sequence. Streamlit Cloud Deployment: Managing Google Cloud Service Account JSON credentials locally is easy, but securely passing them into Streamlit Cloud via st.secrets while maintaining dynamic fallbacks required us to rewrite our authentication flow entirely. The "Blank Screen" Data Trap: Transitioning from a one-shot script generator to a true Conversational Agent meant our parsing loop kept dropping the heavy media assets on page refreshes. We had to engineer a custom dictionary structure inside Streamlit's chat history state to hold the binary audio/image data securely alongside the text. Accomplishments that we're proud of We are incredibly proud of making this a Co-Creative Agent. It's not just a "click button, get story" tool. Users can interact with the Bard, telling it to "make the second transaction a bribe instead," and the agent will dynamically rewrite the context, generate new images, and synthesize new audio perfectly aligned with the real blockchain data. It genuinely feels like sitting next to a movie director.
What we learned We learned that prompting a multimodal model is fundamentally different from a text LLM. You aren't just telling it what to say; you have to teach it how to "direct" downstream systems (like Imagen and TTS). We improved our skills in State Management, API Orchestration on GCP, and integrating live, noisy Web3 data safely into AI contexts.
What's next for Ledger Bard Video Integration (Veo): The natural next step for our interwoven output is passing the VISUAL prompts into Google's Veo to generate 5-second localized video clips instead of static images. Multi-Chain Intel: Scaling our API logic to pull from Ethereum, Solana, and Bitcoin so users can cross-examine multiple wallets in the same narrative. Minting the Future: Adding a feature where users can package the generated multimodal storyboard and mint it as an NFT directly onto the chain from which the data was sourced.

Log in or sign up for Devpost to join the conversation.