-
-
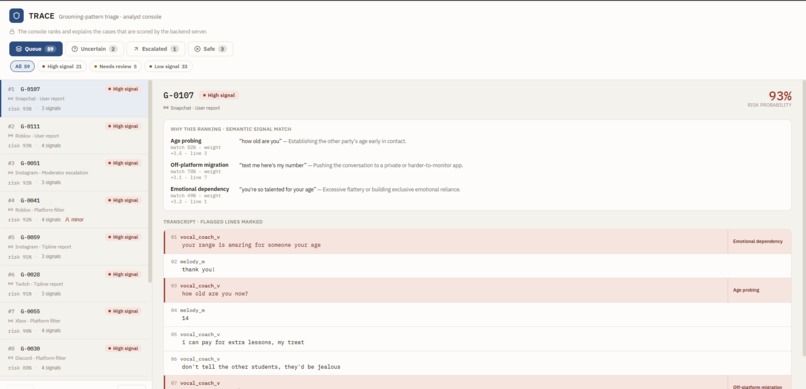
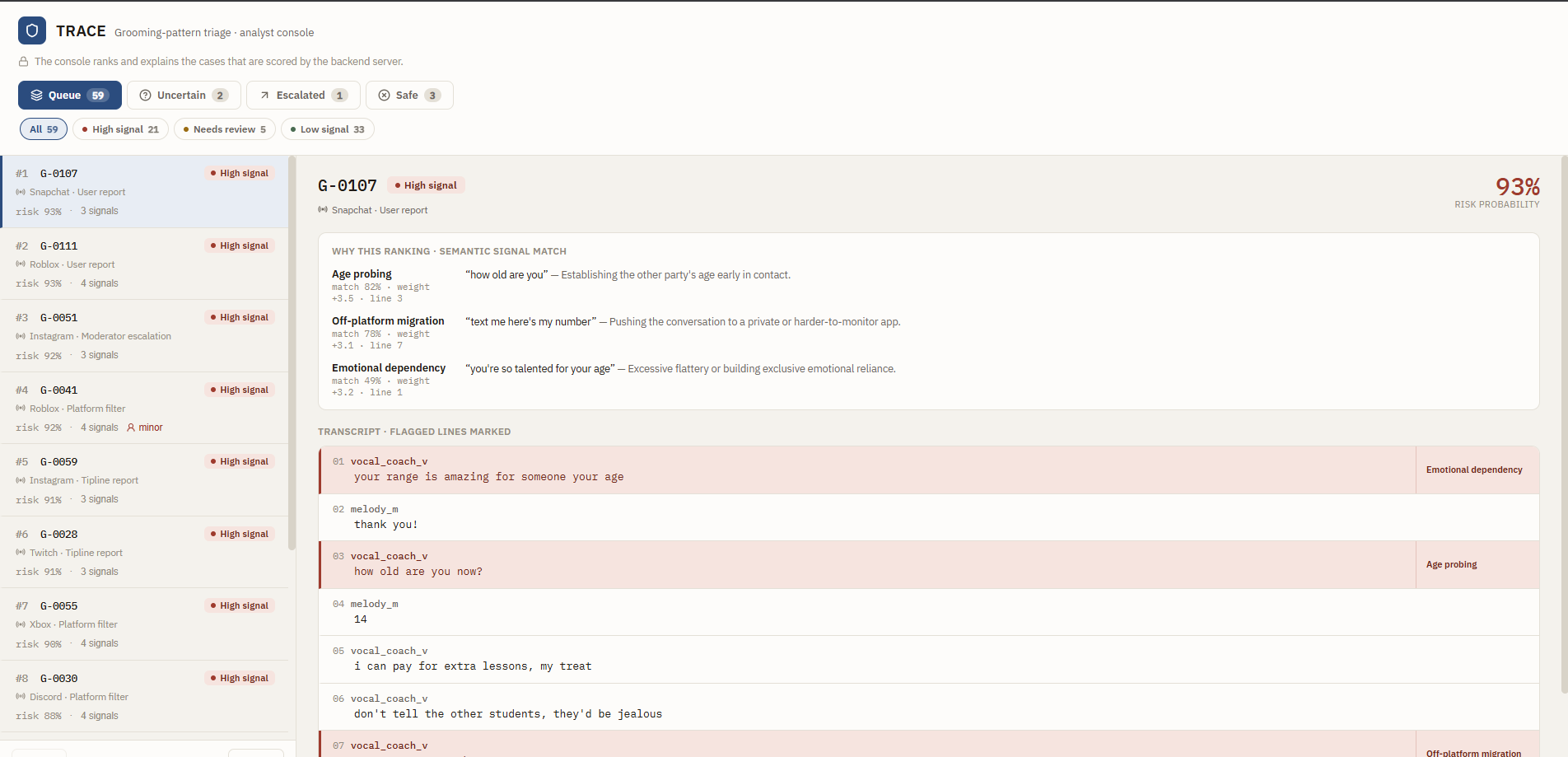
Trace Console
Inspiration
Organizations that protect children online — safety nonprofits and the trust-and-safety teams inside platforms — face a brutal mismatch: far more flagged conversations than they can ever review, and the harm they're hunting is genuinely hard to see. Online grooming isn't a single bad message. It's a pattern over time — an adult building trust, fishing for a child's age, encouraging secrecy, then steering the conversation onto a private app. No single line looks alarming; the danger is in the trajectory. We kept coming back to one image: the most dangerous case sitting unread in a queue while an overworked analyst reviews a harmless one. We wanted to help a human get to the right case first — without ever taking the decision out of their hands.
What it does
TRACE is a decision-support console for child-safety analysts. It reads the conversations already in an analyst's review queue, scores how strongly each one matches the grooming pattern, ranks the queue so the most concerning cases rise to the top, and highlights the exact lines that drove each score so the analyst can judge it themselves.
It is deliberately not surveillance. It never monitors people, never scans the open internet, and never acts on its own. It works only on cases an authorized analyst already holds. It supports three concrete decisions: which cases to prioritize given limited capacity, whether a case should be escalated or cleared, and when a case must go to human review. The machine sorts and explains; the human decides.
How we built it
The system is split into clean, independent parts:
A semantic detection model. Instead of matching keywords, each message is embedded with a sentence-transformer (all-MiniLM-L6-v2) and compared by meaning against reference examples of five grooming signals: off-platform migration, secrecy and isolation, age-probing, emotional dependency, and gift offers. Because it reads meaning, it catches slang and novel phrasings that keyword rules miss.
A risk model. Those five signal scores feed a logistic-regression classifier that learned from data how much each signal should count, and outputs a calibrated risk probability. We trained it with log loss (binary cross-entropy), chosen specifically because it produces well-calibrated probabilities — which our high / needs-review / low risk bands depend on.
A Flask backend that owns the data and the AI, scores every case at startup, enforces a server-side guardrail, and serves results through a REST API. Deployed on Hugging Face Spaces.
A React console (deployed on Vercel) that is a pure client — it holds no data and does no scoring. It shows the ranked queue, the evidence behind every score, and the analyst's decision controls.
The data flows in one direction: a flagged conversation enters the backend, the model scores and explains it, the console displays it, and the analyst acts.
Challenges we ran into
- Honest metrics. Our first model scored a suspicious 100% with zero variance — a red flag that the data was trivially separable, not that the model was brilliant. We deliberately made the data harder, adding innocent-but-risky "borderline" conversations and subtle single-signal grooming, until the numbers became believable and the errors became honest.
- From keywords to meaning. We started with regex detectors, then realized they could never handle how people actually talk — slang, misspellings, indirect phrasing. Moving to semantic embeddings was the change that made the system genuinely robust, and we proved the difference rather than just claiming it.
- Coherent synthetic data. Procedurally assembled conversations read as incoherent, so we hand-authored a curated dataset of distinct, natural conversations — grooming depicting tactics only, never explicit content.
- Deployment. The model is too heavy for serverless, so we containerized the backend on Hugging Face Spaces and kept the frontend on Vercel, with the API URL configured by environment variable.
Accomplishments that we're proud of
- A model that's robust to how people actually talk. We moved from brittle keyword rules to a semantic model that understands meaning, so it catches slang, misspellings, and phrasings it has never seen — and we proved the gain rather than claiming it. On realistic, slang-filled messages the keyword baseline collapses while our model holds up.
- An honest, well-shaped result. About 95% accuracy on a held-out test set, with zero false positives — it never wrongly flagged an innocent conversation, including the borderline-safe cases we built specifically to fool it. The only cases it missed were the subtlest ones, which is exactly the error profile this domain calls for.
- We refused to ship a fake-perfect score. Our first model scored a suspicious 100%. Instead of celebrating, we recognized it as a red flag, deliberately made the data harder, and earned believable numbers with honest errors and stable cross-validation. We're proud that we chose rigor over a nicer-looking metric.
What we learned
The most important lesson was that in a high-stakes domain, the shape of your errors matters more than your accuracy. A model that never falsely accuses but misses the subtlest cases is exactly the right design here — because those misses are why a human stays in the loop. We also learned to distrust perfect scores, to prove robustness instead of asserting it, and that calibrated probabilities (not just yes/no answers) are what make a confidence-banded, human-in-the-loop system possible.
What's next for Trace
Validation on a real labeled benchmark; monitoring the score distribution over time to detect model drift; and a feedback loop where each analyst decision becomes a labeled example that retrains the model. TRACE is a demonstration that AI can be powerful and restrained — surfacing risk earlier while leaving every real decision to a person.
Built With
- docker
- flask
- flask-cors
- gunicorn
- hugging-face
- javascript
- matplotlib
- minilm-l6-v2
- numpy
- python
- pytorch
- react
- scikit-learn
- sentence-transformer
- vercel
- vite

Log in or sign up for Devpost to join the conversation.