-
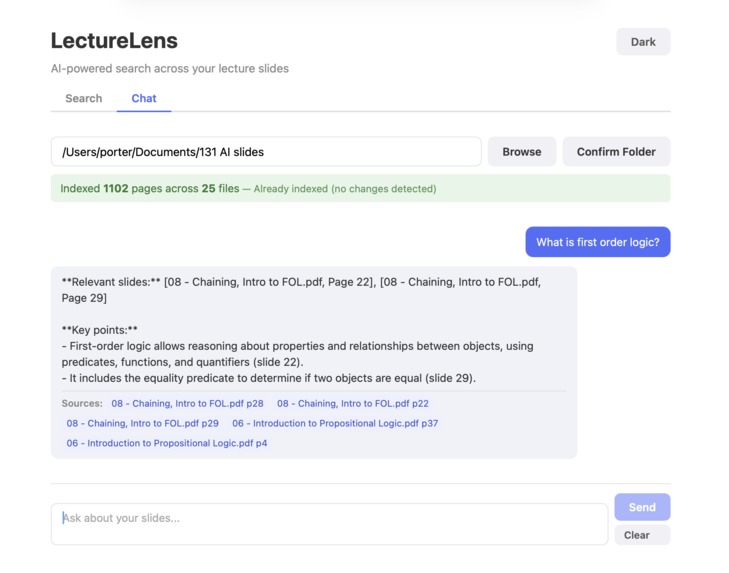
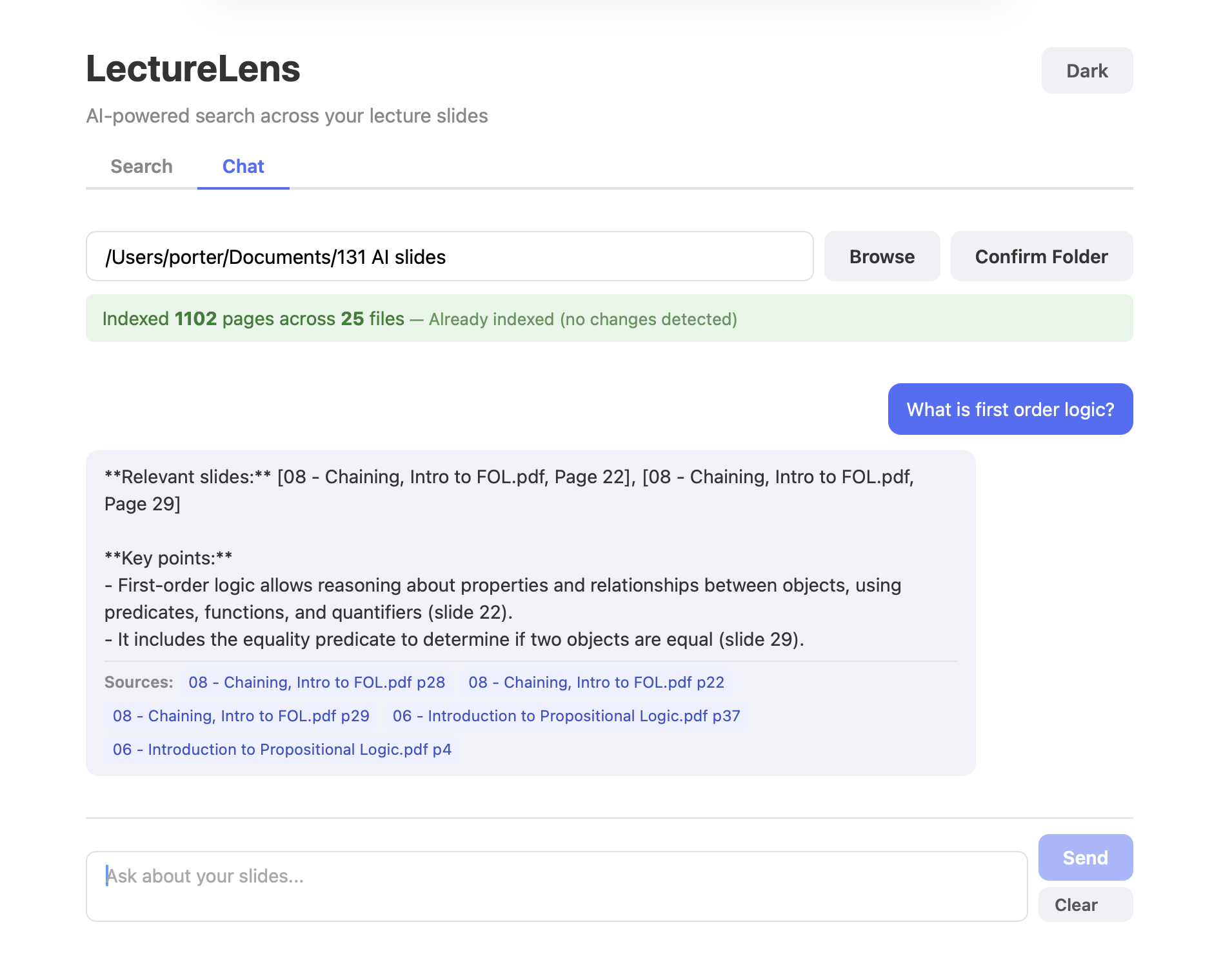
Ask your question in LectureLense and get page number of referenced slides
Inspiration
During midterms and finals season, students face the frustrating task of locating a specific concept buried in a semester's worth of lecture slides — slides they saw weeks ago, now scattered across dozens of files.
The obvious solution? Upload everything to ChatGPT. But your professor isn't happy about that. AI companies may use uploaded materials to train their models, and unauthorized uploads can constitute intellectual property infringement, violation of course policy, and a breach of academic integrity.
The alternative — opening PDFs one by one and hitting Ctrl+F — is slow, keyword-dependent, and exhausting.
LectureLens solves this by running a semantic search engine entirely on your machine. No uploads, no cloud, no compromise. Your slides stay yours.
How We Built It
We built a local-first RAG (Retrieval-Augmented Generation) pipeline that indexes lecture materials at the page level.
Backend (Python):
- FastAPI serves the API; Uvicorn runs the server
- PyMuPDF extracts text from PDFs; python-pptx and python-docx handle PPTX and DOCX; plain TXT is read natively
- Each page is embedded into a vector using Ollama with the
nomic-embed-textmodel - Embeddings and metadata are stored in ChromaDB, a persistent local vector database
- Search uses cosine similarity to find the most relevant pages
- A local LLM (
qwen3:1.7bvia Ollama) provides AI-powered re-ranking and conversational Q&A with citations
Frontend (TypeScript):
- React 19 + Vite for a fast, responsive UI
- Users select a folder, search naturally, and navigate directly to the exact slide page
Everything runs locally — no API keys, no internet required after setup.
Challenges We Ran Into
Pure semantic search returned noisy results — embedding similarity alone wasn't enough. We introduced a small local LLM to re-rank results and generate human-readable answers with cited file names and page numbers, which dramatically improved usability.
Getting a 1.7B parameter model to follow structured citation formats was another challenge — small LLMs don't reliably follow prompt instructions, so we built a post-processing layer that regex-matches and corrects citations in the LLM output.
Accomplishments That We're Proud Of
- A fully functional local RAG pipeline — from raw slides to cited answers — with zero cloud dependencies
- Multi-format support: PDF, PPTX, DOCX, and TXT
- The LLM correctly cites real file names and page numbers, letting students jump straight to the source material
- Built and iterated in under 24 hours using agentic coding workflows
What We Learned
- Small LLMs are powerful but need guardrails — prompt engineering alone isn't enough; sometimes you need code-level post-processing
- Agentic coding tools (like Claude Code) dramatically accelerate prototyping, letting us spend more time on ideas and less on boilerplate
- Running AI locally is not only feasible — it's the right call when academic integrity matters
What's Next for LectureLens
- Package as a standalone app (Electron or Tauri) so students don't need to run terminals
- Image-aware search using
nomic-embed-vision(same embedding space as our text model) to search diagrams and figures - Better onboarding with guided installation and setup instructions


Log in or sign up for Devpost to join the conversation.