-
-
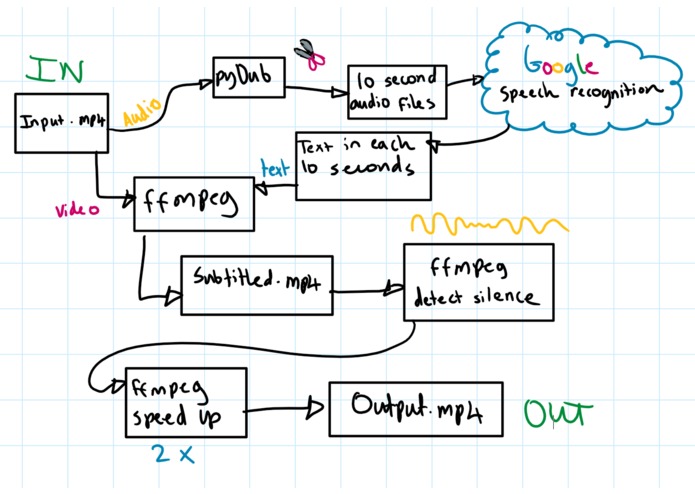
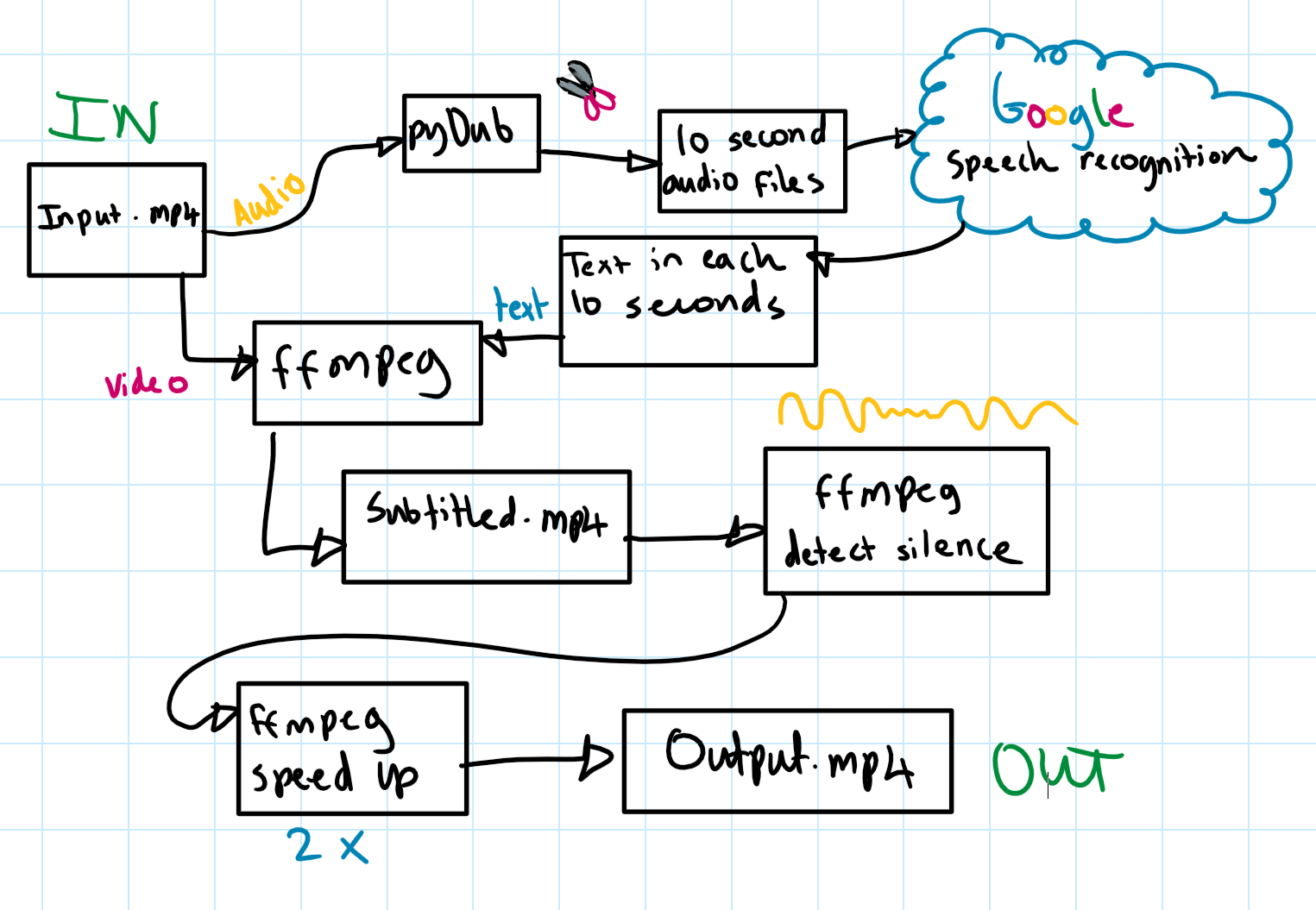
Flow chart
Inspiration
We wanted lectures to be in a more consumable form for review. Our science lectures usually comprise of equal parts speaking and writing on the white board. If both parts are sped up, then the speech can be a little hard to follow. However, speeding up just the whiteboard writing would save a lot of time without affecting comprehension.
The addition of subtitles would mean that the lectures could be reviewed in quiet places without the need for headphones.
What it does
It takes an mp4 file as an input (the lecture). It then exacts each sentence that the lecturer says and uses that to create subtitles for the video. It then works out the times that the lecturer is not speaking (e.g. when they're writing on the board) and speeds up those sections.
This means that you can review the lectures without needing sound and in a much shorter amount of time. (Usually a 33% reduction in time)
How we built it
We used pydub to get the audio from the lecture video. We then split the audio into small segments and made google speech recognition api requests in order to determine which words were being spoken.
A script was then written to add the subtitles to the lecture video.
Finally, the silence in the video was identified. The clip was split into silent and non-silent parts. The silent parts were sped up and the whole thing concatenated back together.
Challenges we ran into
There were quite a lot of challenges…
Originally the project was quite different.
The first half of the hackathon we aimed to create a program what would isolate individual words from a video file. This would then be able to be used to string together a video of the person saying a phrase automatically based on words from the video. (This would be similar to some of the parody videos that you might see on the internet where a politician sings a song).
This provided too problematic to carry out. This is because speech recognition libraries rely on contextual information to identify words, and so are poor at identifying single words. This meant that we couldn't get the dataset that we needed.
However, along the way, we gained quite a bit of experience in using ffmpeg, pydub, and the google speech api. These new skills allowed us to pivot our project to a slightly different idea. Which is what we ended up creating.
Within the final project there were still quite a few difficulties:
Splicing together the video files that were sped up with the regular speed files in a smooth way. The differing frame rate made this a challenge to do nicely.
The execution speed of the project was a huge challenge. Currently the project takes around 1-2 minutes per minute of video (not ideal when the project is meant to save time). This could be improved in the future, however. One of the main sources of delay was waiting on the api responses. This could be avoided if we ran the speech recognition locally on the machine.
Splicing together video was also a little slow. This could be improved by better leveraging some of ffmpegs more powerful features.
The slow execution speed also slowed debugging.
Accomplishments that we're proud of
Our progress with isolating individual words for analysis even though it didn't work out entirely in the end. We also wrote quite a robust utility for managing a database of videos of words being said and string them together into one large video. We also implemented the genius lyrics api in order to automatically get the lyrics of a song to further automate the video creation process.
We’re also proud of the extensive set of functions we wrote for manipulating audio files into various formats. These functions extended the pydub library with quite useful features, and allowed us to get familiar with the libraries.
What we learned
How to use the pydub, ffmpeg, and google speech apis. How to manipulate audio and video files.
What's next for Lectureiser
There are a few ways that Lectureiser could be improved.
The main area of improvement would be accuracy. Our current recognition is maybe around 90% accurate for 'good' audio files. If there is a large amount of background noise, or the lecturer is hard to differentiate the program struggles. It also struggles when the lecturer says mathematical expressions since they're not really words.
Another big improvement would be to dramatically increase the speed at which the program runs. This would make the program much more usable and more accessible.


Log in or sign up for Devpost to join the conversation.