Project Story
Inspiration
As students in Southeast Asia, we attend lectures delivered in mixed languages — English sprinkled with Vietnamese, Thai, Singlish, or Bahasa. Taking notes manually is exhausting and incomplete. Existing transcription tools (Whisper, Google STT) struggle badly with SEA accents and code-switching.
We asked: What if you could just record a lecture and instantly get a complete bilingual study pack — summary, quiz, and flashcards — in both English and your native language?
When we discovered Valsea — a speech AI platform purpose-built for Southeast Asian languages — the idea clicked.
What We Built
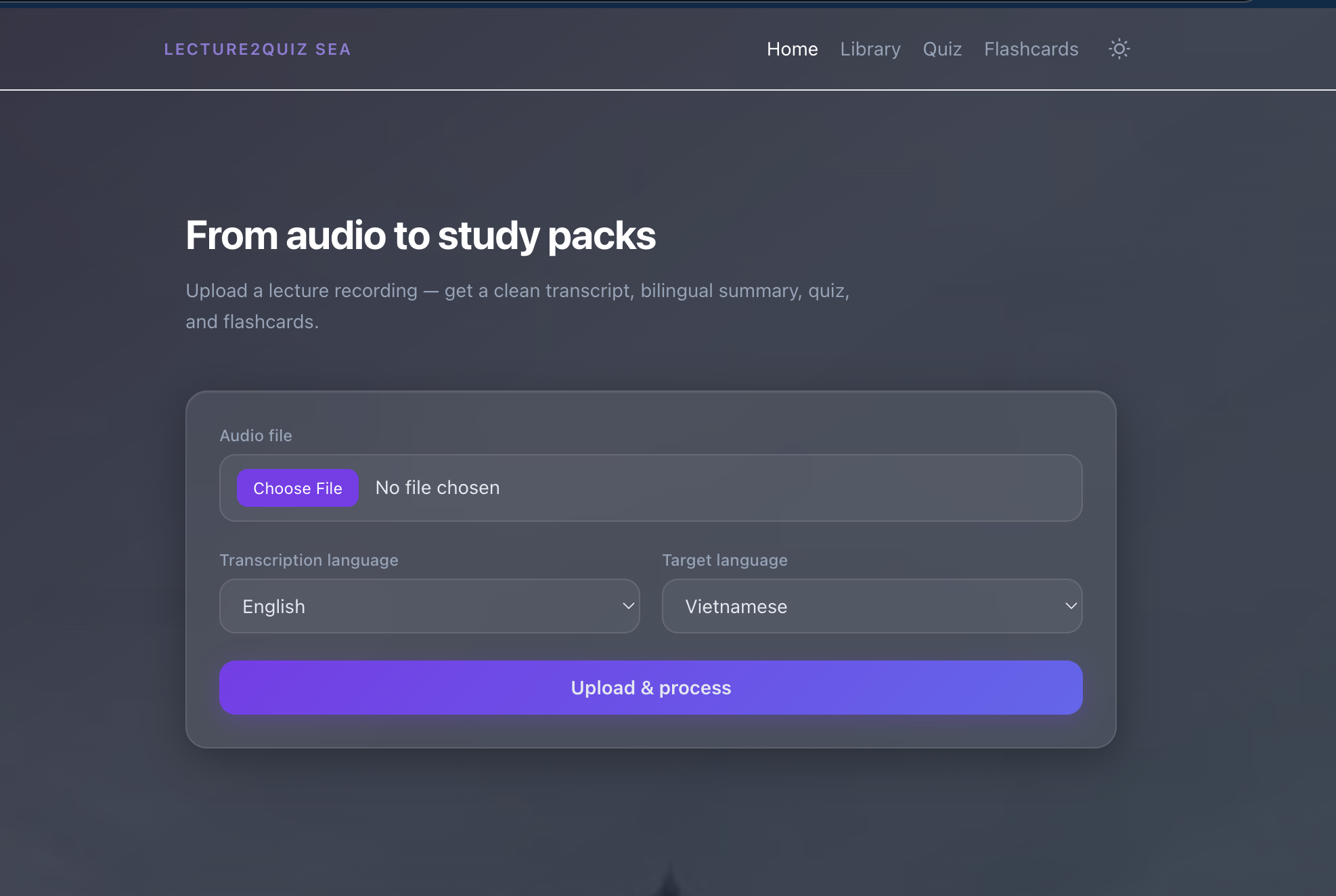
Lecture2Quiz SEA is a full-stack pipeline that transforms classroom audio into a ready-to-use study pack:
- Transcribe — Valsea STT with accent-aware models (supports 70+ languages including Singlish, Vietnamese, Thai, Filipino)
- Clarify — Valsea cleans noisy/colloquial speech into grammatically correct text
- Summarize — Valsea formats the transcript into key quotes, overview, and takeaways
- Generate Quiz — AWS Bedrock (Claude) creates 10 MCQ questions from the content
- Generate Flashcards — Leveled cards (easy/medium/hard) for spaced repetition
- Translate — Everything output in both English and the student's chosen language
How We Built It
- Backend: Python FastAPI orchestrating the Valsea API pipeline (transcribe → clarify → format → translate) and AWS Bedrock for quiz/flashcard generation. All steps run in parallel where possible using
asyncio.gather. - Frontend: React + Tailwind CSS with real-time progress via Server-Sent Events (SSE). Includes an interactive quiz room and a flip-card spaced-repetition deck.
- Smart audio handling: Files over 8 MB are automatically split into ~4.5-min chunks via
ffmpeg, transcribed in parallel, then recombined — no manual preprocessing needed.
Challenges We Faced
Large file uploads — Valsea has a 10 MB limit per request. We solved this by building an auto-splitter that chunks audio and transcribes in parallel ($n = 3$ concurrent requests by default), then recombines in order.
Network reliability — Uploading large audio over unstable connections (VPN, campus Wi-Fi) caused
ReadErrormid-upload. We implemented retries with exponential backoff and better error messaging.Bedrock throttling — AWS rate-limits Claude API calls. We added configurable retry logic with
BEDROCK_QUIZ_MAX_RETRIESand context truncation to stay under token limits: $$\text{context_chars} \in [4000, 120000], \quad \text{default} = 24000$$Quiz quality — Getting Claude to produce exactly 10 well-formed MCQ items with consistent JSON schema required careful prompt engineering and validation.
Adaptive learning loop — Making quiz misses automatically become flashcards required a client-side state machine tracking
localStoragesessions across quiz and flashcard pages.
What We Learned
- Valsea's
clarifyendpoint is a game-changer — it turns messy spoken language into clean text that LLMs can actually reason about - Running transcription, formatting, and generation in parallel cuts total latency by ~60%
- SSE provides a much better UX than polling for long-running pipelines
- Building for SEA languages requires purpose-built tools — generic models consistently fail on accents and code-switching
What's Next
- Real-time live transcription via Valsea WebSocket (
valsea-rtt) - Persistent lecture library with analytics (weak topics, study streaks)
- Export to Anki deck format
- Mobile PWA for on-the-go review

Log in or sign up for Devpost to join the conversation.