Inspiration
Pacman, Space Invaders, Asteroids. Any kid that grew up with this golden age of video games knew how fun it was- but what about how vital it was to humanity’s progress? Today, society tackles complex problems, like how robots can “think” for themselves, or how to create recommendation systems. We want to understand- how can machines fundamentally get better at what they do, and learn from their mistakes? It comes down to developing a high-level understanding of Reinforcement Learning (RL). We decided to do that by looking into Atari Games. Our goal for this project was to find out which reinforcement model (PPO and DQN) works better on Atari games and Mujoco simulators.
What it does
Ran algorithms to train both Atari games and Mujoco simulations to be more efficient through trial and error.
How we built it
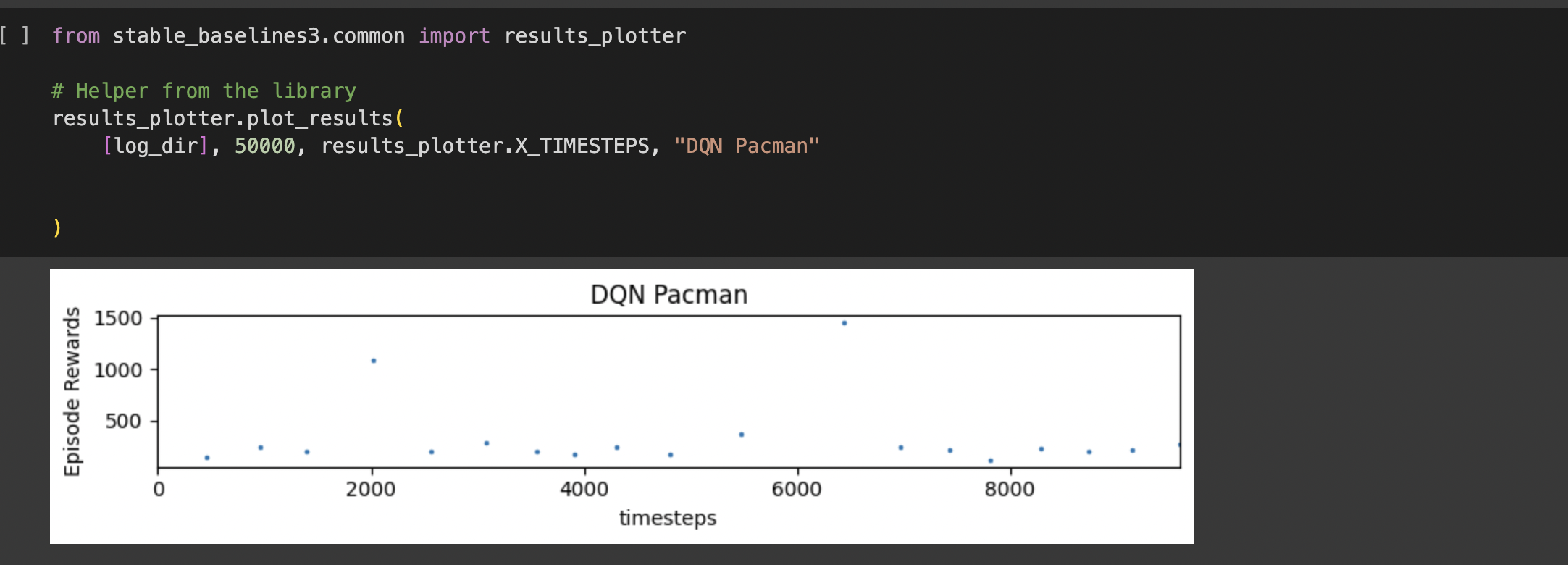
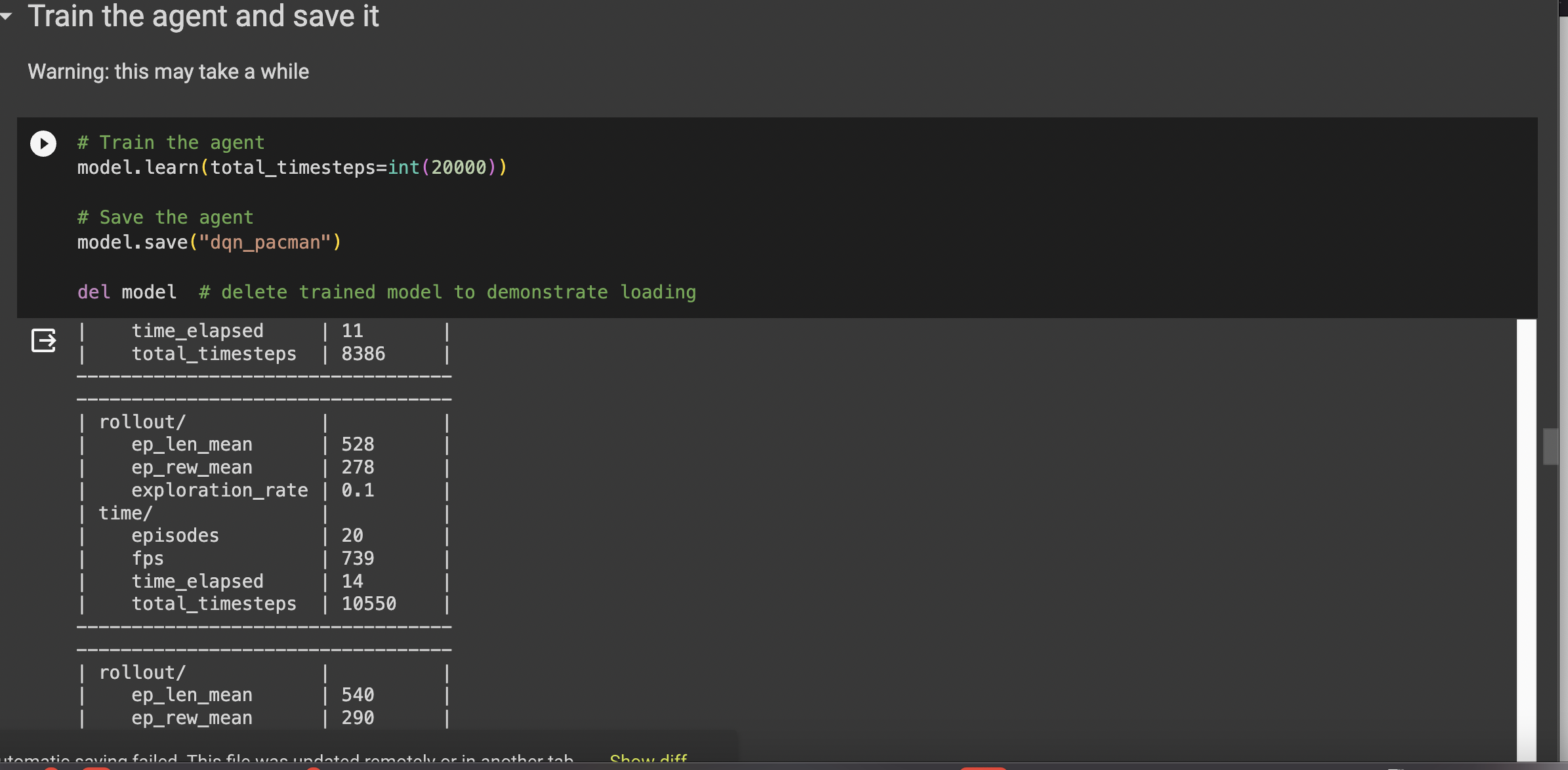
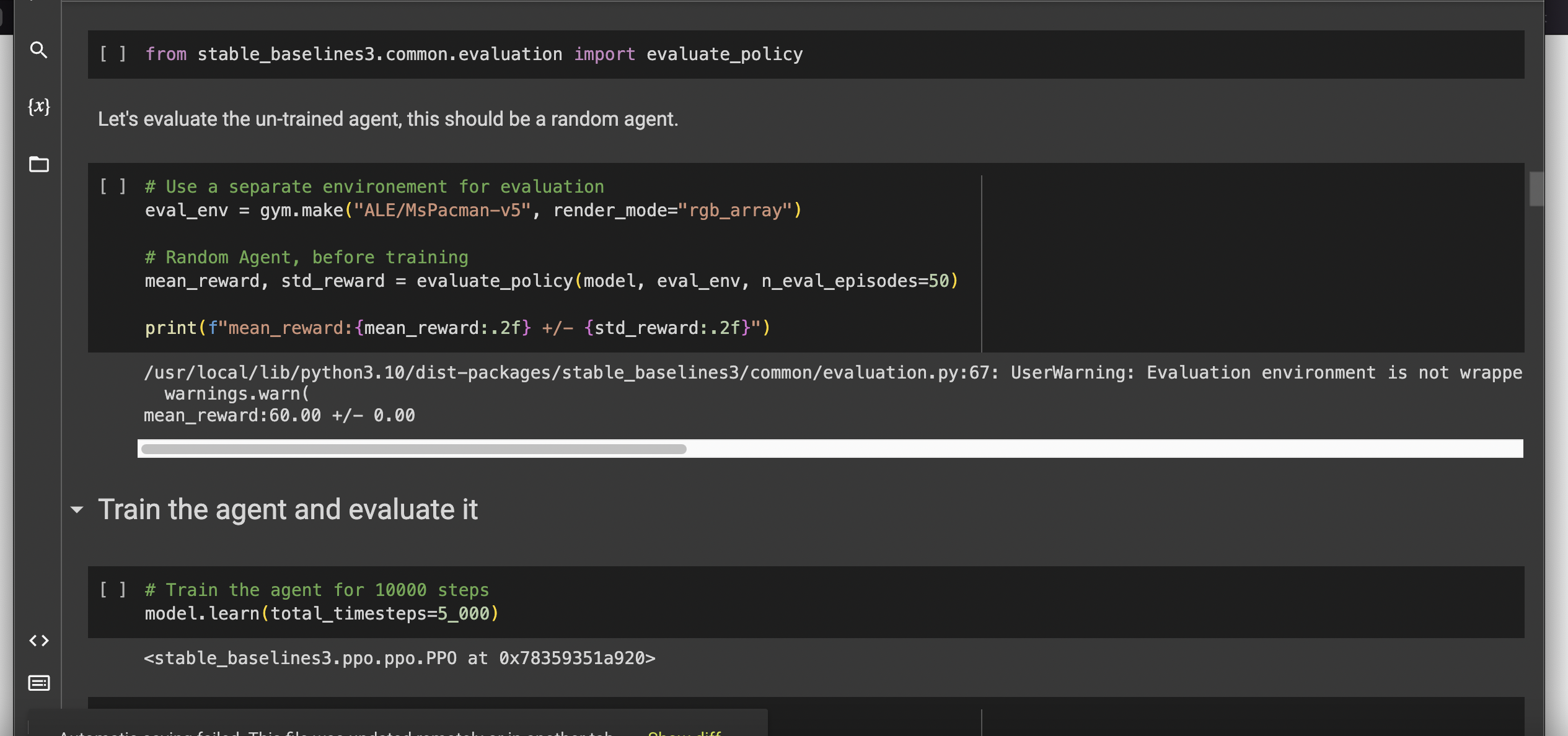
We used stable baselines 3 from Jupyter Notebook and Github Repo, and experimented with the models and changed some parameters to create graphs as well as videos of the different Atari Game/Mujoco Simulator environments.
Challenges we ran into
No DQN for Mujoco environments because DQN cannot handle continuous actions, plotting the graphs for PPO was not physically possible with the DQN so we were only able to get DQN graphs for the Atari Games/Mujoco simulators Trying to find the right environments to work with our models was difficult. Some would not produce any data, some would produce incorrect data (learning curves going downwards instead of increasing), etc. The time limit: trying to experiment and also debug with our plots. It takes a long time to properly train models through RL, and we didn't have that much time.
Accomplishments that we're proud of
We were able to make a deliverable and create videos for the environments
What we learned
We learned about environments and understood the concept of reinforcement learning, as well as how it can be applied from single games to industry. We also compared and contrasted PPO and DQN models from each other, as well as a high-level understanding of reinforcement learning with policy-behavior, agents, and models to create mean rewards
What's next for Learning how to learn play Atari Games w/ RL
We could find ways to train environments for longer and for more train steps and figure out how to increase RAM space and also train with A2C or DDPG models which are more complex.





Log in or sign up for Devpost to join the conversation.