-
-
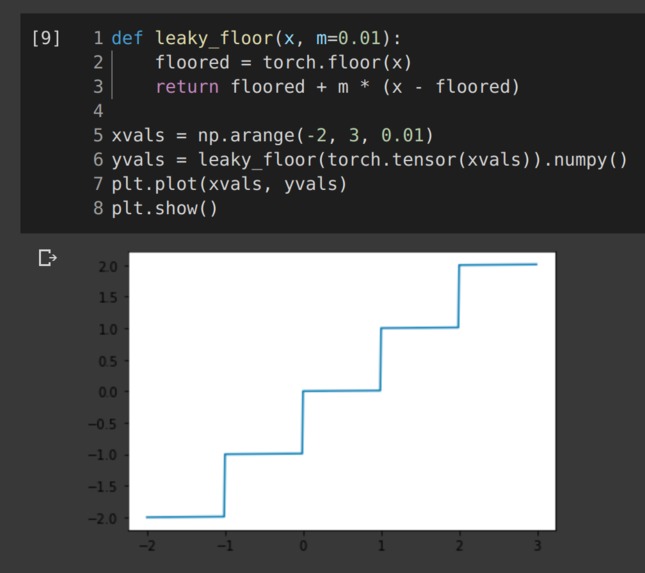
Visualization of the leaky floor function
-
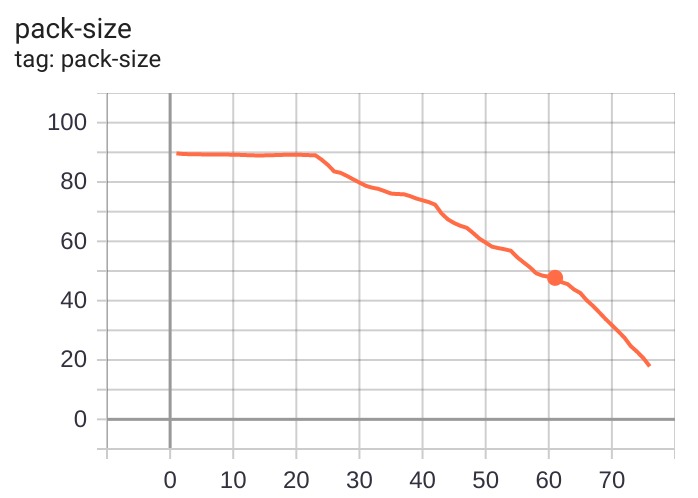
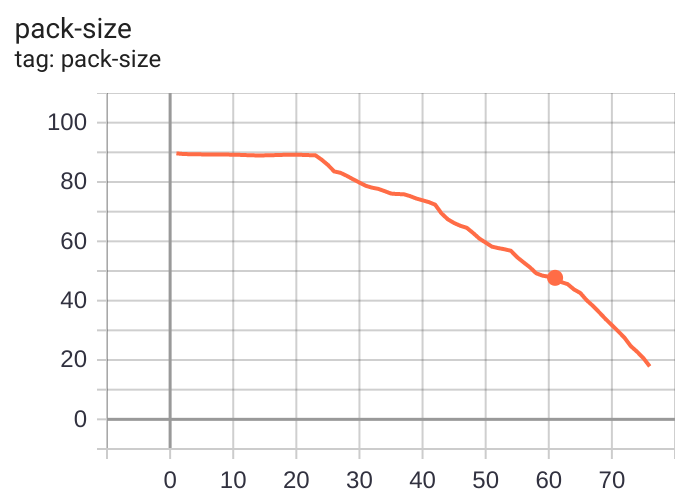
Size of compressed parameters in MB -- note that the initial quantization was 10 bits instead of 32, so the model is already 3x smaller
-
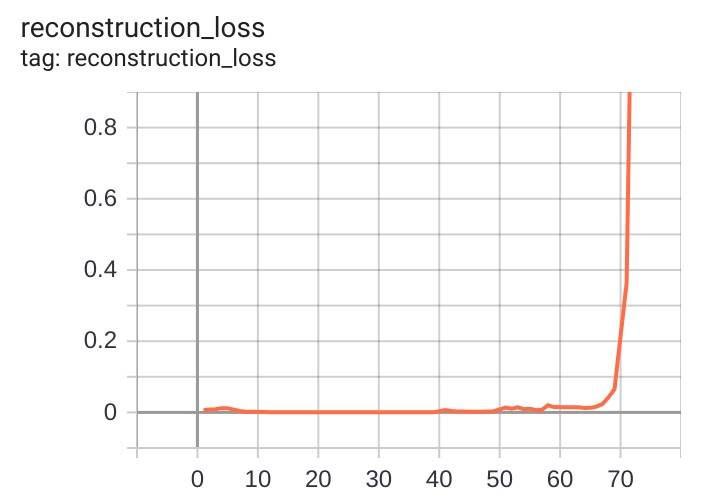
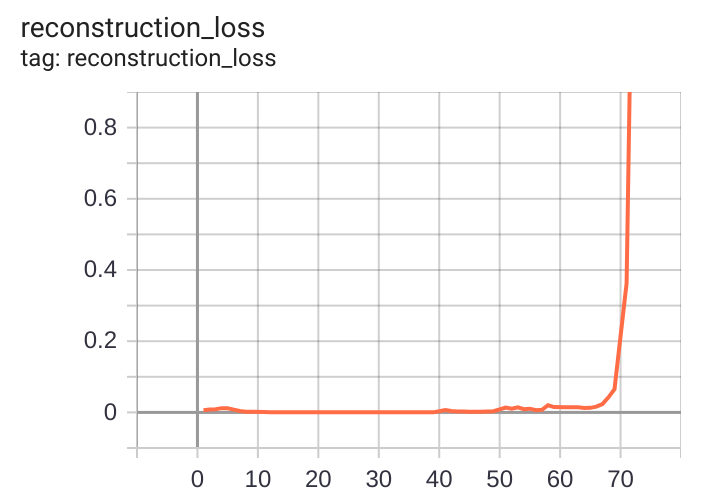
Reconstruction loss for that case. There's essentially no change until iteration 50.
Inspiration
The resources required to train a state-of-the-art machine learning model has doubled every four months (on average). This trend translates to an unsustainable increase in carbon emissions, and model training is only the tip of the iceberg. Nvidia estimates that model inference accounts for at least 80% of the computation spent on deep learning worldwide.
Training and inference costs are increasing because models are becoming larger as well. The GPT-2 XL configuration has around 1.5 billion parameters. Released only a year and a half later, the largest configuration of GPT-3 has 175 billion parameters. The required computational resources increased (roughly) linearly.
Beyond the environmental impact of training these enormous models, they also introduce the inconvenience of being too large to effectively perform inferences on commodity hardware, let alone fine-tune. As a result, control over computation shifts from the end-user to powerful servers in the cloud. While the idea of "migrating to the cloud" is nothing new, there are a number of privacy risks involved in doing so.
It's obvious that we need to make smaller networks. But how?
What it does
Learned Spectral Compression (lsc) is a library that compresses machine learning models during training using a somewhat-novel approach that is heavily inspired by image compression. lsc does this in three steps. First, it converts the model weights of a pre-trained model into a spectral representation, which is still of the same dimensionality as the weights themselves. Then, the user of the library merely needs to continue training the converted model on the original dataset, balancing the optimization criteria of the model (i.e model accuracy) with a quantization loss function which tries to compress the model. Finally, lsc performs a entropy coding pass when the user saves the model to disk, further compressing the model.
For the most part, the user of this library does not have to consider the details of how the technique works -- they just need to use the spectral model as they normally would.
To convert a model to the spectral representation, just run
from lsc import spectral, quantization_loss
q_net = spectral(my_model)
spectral will convert my_model in-place. q_net is the quantization network. This network learns how to compress the model during the optimization process. The user does not need to do anything with it other than pass q_net.parameters() into their optimizer during the fine-tuning or training step. Admittedly the quantization network does add to the memory/space footprint of the model overall, but only by ~10 KB.
optim = torch.optim.Adam(
list(my_model.parameters()) + list(q_net.parameters()),
lr=1e-3
)
Next, during the optimization loop, the user needs to incorporate the quantization loss into their training process. The quantization loss represents the average number of bits per spectral weight in the model. By default, this value starts at 10 bits of precision for all weights (which is already a ~70% improvement over most float32 models). Depending on the use-case, the user might want to modify the output of this loss function (perhaps to limit compression beyond a certain point).
my_usual_model_loss = ...
q_loss = quantization_loss(my_model)
loss = my_usual_model_loss + q_loss
loss.backward()
optim.step()
After training, the user can run the final entropy coding stage and extract a state_dict using the compress_weights function. Ideally we wouldn't need a custom compress_weights function (and the compression would just happen during state_dict()) but I haven't figured that part out yet.
my_state_dict = compress_weights(my_model)
When using lsc, I have observed >95% savings in model size with no noticeable changes in accuracy (see Resnet-152 notebook). lsc hypothetically should be able to compress the parameters of nearly any machine learning model, although in practice most of the savings would be noticed in linear and convolutional layers.
lsc does not reduce the memory consumption during model training. Reducing peak training memory consumption might be possible using this approach, but it is definitely fairly difficult to do without heavy gradient checkpointing. The current implementation of lsc does not actually reduce memory during inference either, but that can be easily added (especially once I figure out an easier way to override state_dict).
How I built it
lsc is (roughly) differentiable n-dimensional JPEG. JPEG might conjure up memories of terrible block artifacts and blurry text, but trust me, lossy tensor compression and gradient descent go together like fine wine and cheese. In a sense, this approach is similar to model pruning -- we want to learn which frequency bands of the model weights are actually important.
Prior to training, we project the initial model weights into a frequency representation. We do so by first computing the mean and variance across each of the weight tensors and then redistributing the weights accordingly (similar to batch norm). As a result, most of the weights are distributed in the range expected by the DCT. Next, we split the data into chunks on each dimension, and then perform an n-dimensional DCT on the chunk dimensions. This is analogous to the block coding steps and DCT steps in JPEG, but so far, everything is differentiable.
Internally, the spectral function modifies all of the relevant layers of the initial model into HyperNetwork modules. HyperNetwork modules instantiate and run another module type to generate the parameters of the original network (at the moment just weight and bias), and then runs the initial module with the computed weights. SpectralCompressionWrapper is the "weight generator" used for this library, each weight of each module is paired with a SpectralCompressionWrapper. All SpectralCompressionWrappers share the same underlying quantization network.
The forward pass of the wrapped model involves the following steps --
- Compute a quantization tensor by using the quantization network. The quantization network accepts a tensor of positions (i.e locations in the weights matrix), computes a sin-cos positional embedding (like Transformers or NeRF), and then runs a small MLP to estimate the quantization tensor.
- Multiply the spectral weights by 2^{quantization tensor}, run the leaky floor function, and then divide the spectral weights by 2^{quantization tensor}.
- Run the inverse DCT to re-generate an amplitude representation.
- Reshape the weights into their original shape
- Undo the gaussian re-distribution.
Leaky floor is pretty simple, it basically lets us differentiate through the floor function by leaking gradients through.
def leaky_floor(x, m=0.01):
floored = torch.floor(x)
return floored + m * (x - floored)
There is a lot more documentation on each of these individual components in the source code :)
Challenges I ran into
I struggled quite a bit to extend PyTorch with the intended behavior. lsc is ideally supposed to be a magical opaque box that can wrap anything that extends nn.Module.
To do so, it replaces every submodule of the network with hyper-networks that generate the model weights. So I had to find a way to automatically reparameterize arbitrary models without affecting the internal state that creates
state_dict.The dimensionality of the output of this hypernetwork is the dimensionality of the model weights, which is quite large. That means that a lot of care has to be taken to ensure that gradients are not accumulated for intermediate steps. This is part of the reason why
lsccomputes the DCT in blocks -- it means that the maximum dimensionality of an activation or gradient of the quantization network scales with the maximum block size (which is usually < 256). I also experimented with gradient checkpointing, but the increase in compute time was not worth it.I mostly have been working on this project over the last week (when I discovered the summer hackathon). Mostly this weekend.
While I do feel that PyTorch was certainly the right tool for the task, this entire project (perhaps fittingly) did feel like a giant hack.
Accomplishments that I'm proud of
I think the entropy coding stage is pretty unique. Implementing a somewhat-efficient n-dimensional Morton encoder that uses a variable dimension size was fun, especially given that it replaces the "zig-zag" ordering in JPEG. I couldn't get it to run remotely efficiently in pure Python PyTorch, so I just rewrote that part in numba.
Also the compression ratio is pretty good. I think lsc can be compared to SOTA pruning (which admittedly are very hard to compare because of a lack of a consistent benchmark).
What I learned
I learned about Morton ordering, positional encoding, PyTorch checkpointing, PyTorch's nn.Module internals, and tensor decomposition.
What's next for Learned Spectral Compression
In no particular order, here are some critical TODOs:
Figure out a cleaner interface to do compressed model save/load. I spent a while trying to override
state_dict's behavior (to store the compressed representation rather than the ), but I couldn't figure it out in time for the hackathon deadline.At the moment,
lscdoes not actually save any memory in inference mode. You could totally run the de-compression in real-time on a layer-by-layer basis, saving plenty of GPU memory. I already spent a decent amount of time optimizing most of the entropy coding to do so as well, I just didn't have enough time to implement it.More experiments! I mostly tested on ResNet and some small models. I am curious how it would do on GPT-2 but I definitely do not have the resources to fine-tune anything larger than
gpt2-smallor possiblygpt2-medium.I'm using an external library's differentiable DCT implementation, and it's pretty slow (~30% of the runtime). I think I could speed it up by switching between the non-fast Fourier transform and the fast variant on a dimension-by-dimension basis, and fusing the various operations together. Maybe this step could even be implemented in tensor comprehensions, or possibly a separate CUDA extension.
Figure out a way to compress non-parameter tensors, like the running mean/variance batch norm.
Use 128-bit integers (instead of 64-bit integers) in the Morton encoding so that we can have > 8D tensors with a max chunk size of 256.
It could be interesting to try using low-rank tensor decomposition in tandem with this lossy spectral compression approach. Maybe Tucker decomposition?
Switch from the discrete Fourier/cosine transform to the discrete wavelet transform (like JPEG 2000)
See the github repo or this colab notebook for more details


{kind=link}
Log in or sign up for Devpost to join the conversation.