-
-

LeadMe Cane
-

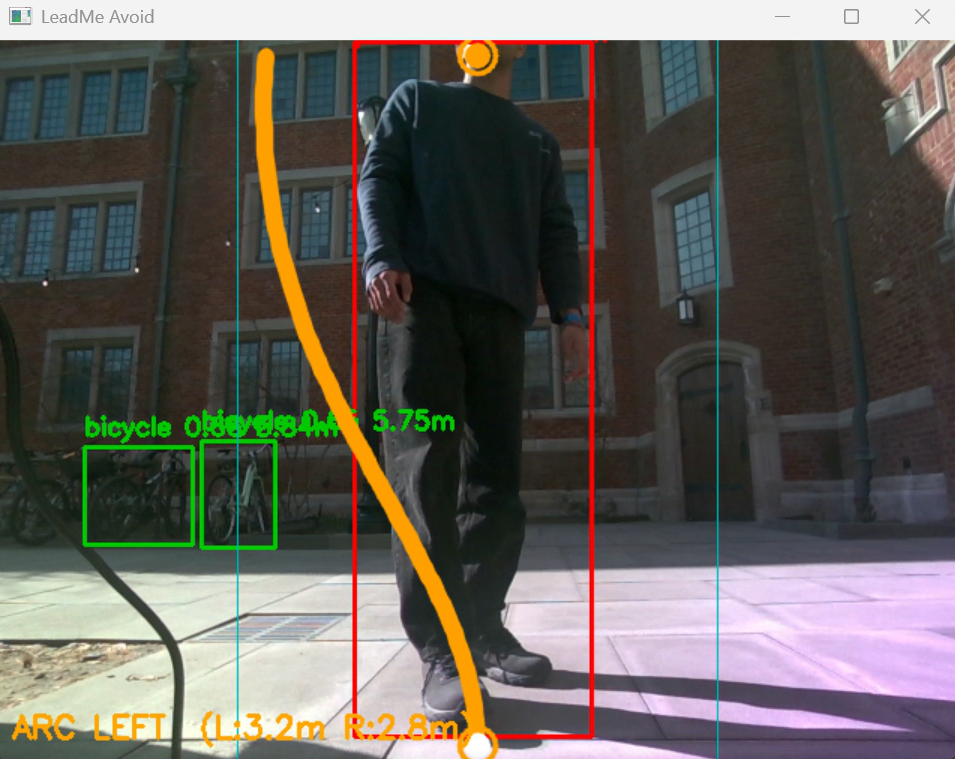
LeadMe Cane with person
-

-
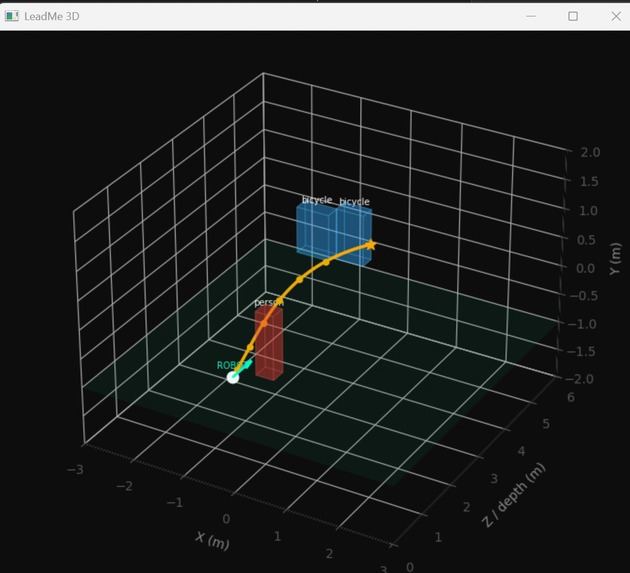
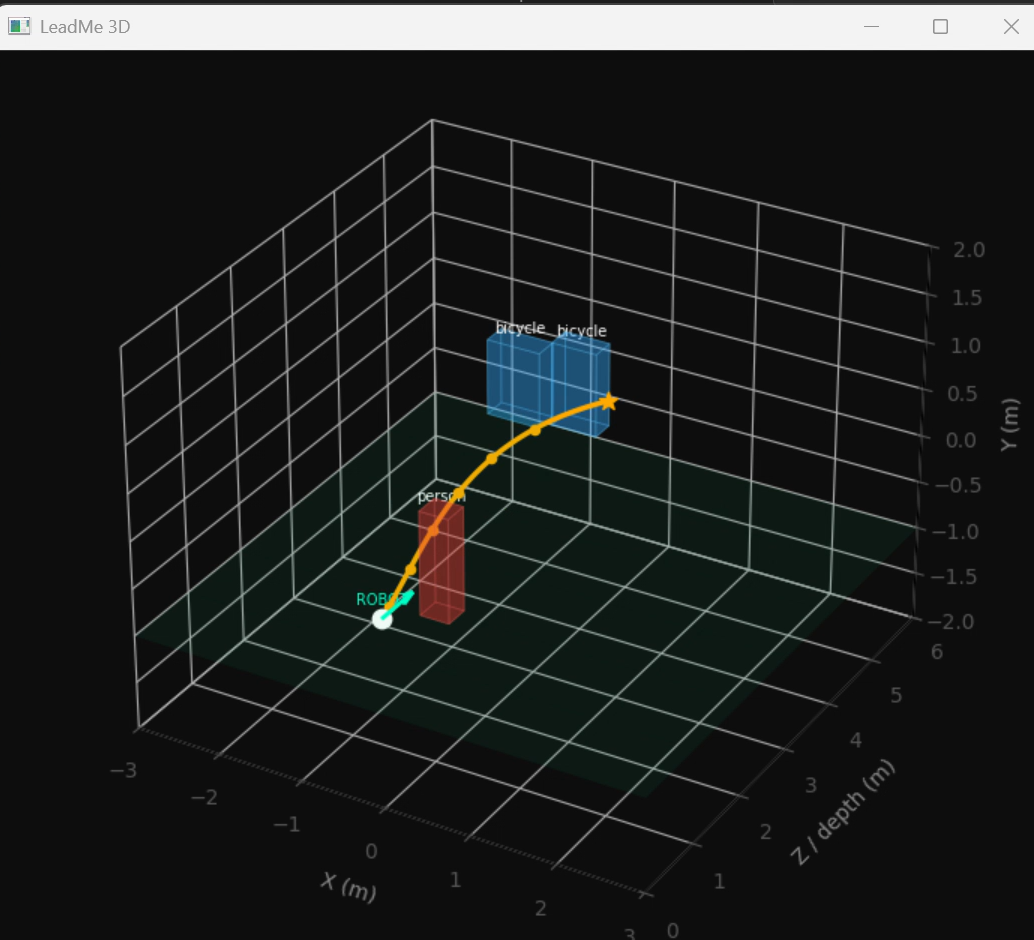
3d visualization of cane path
-
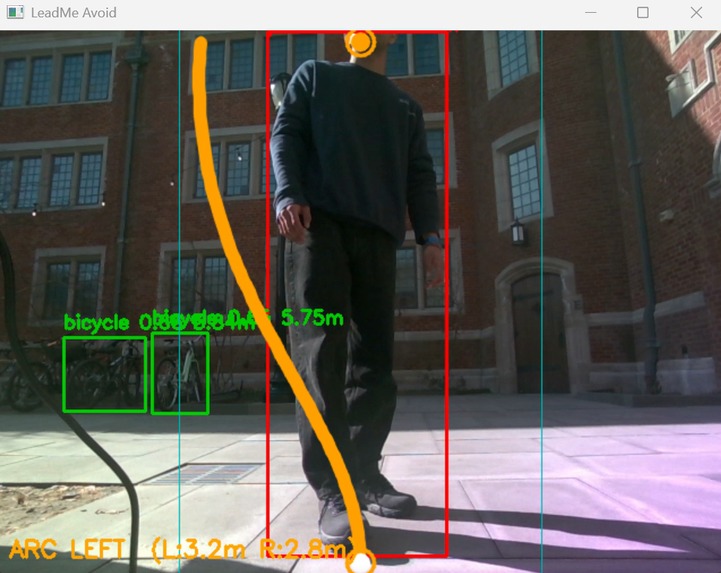
-
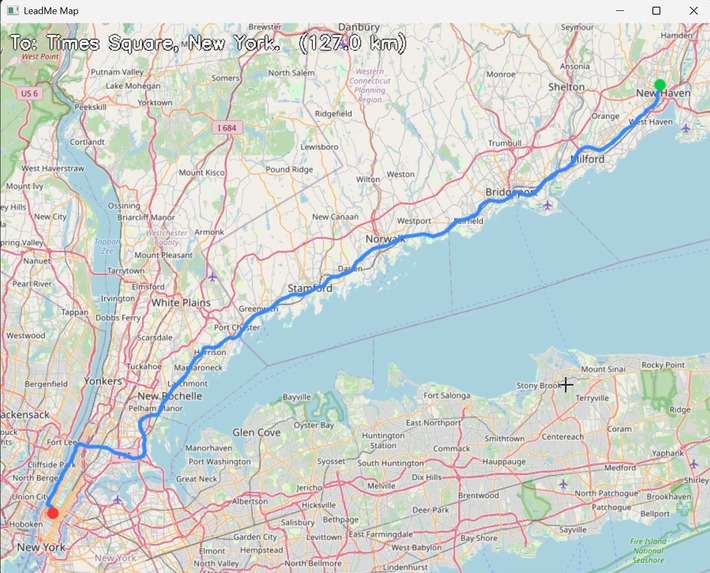
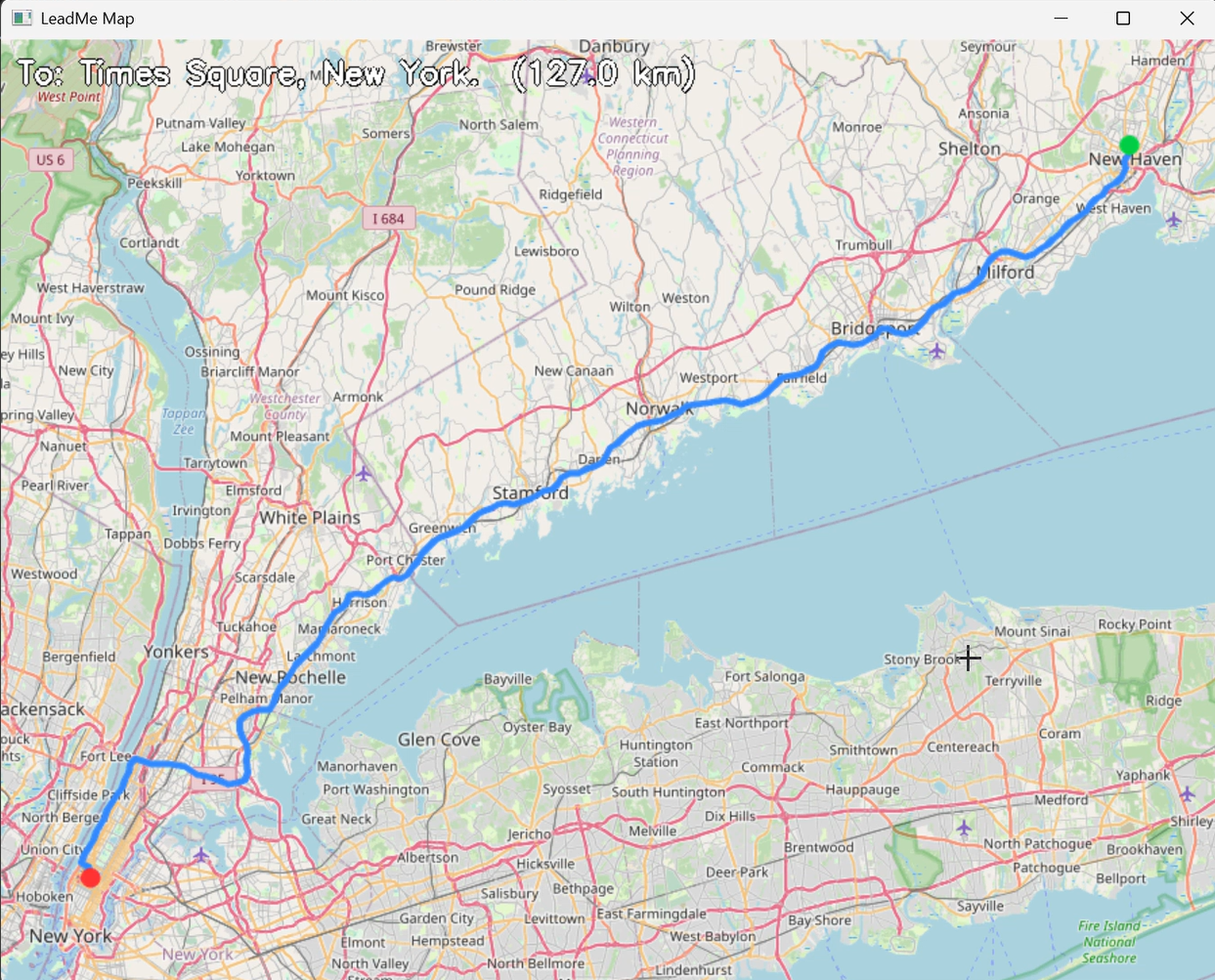
map path to the destination
-
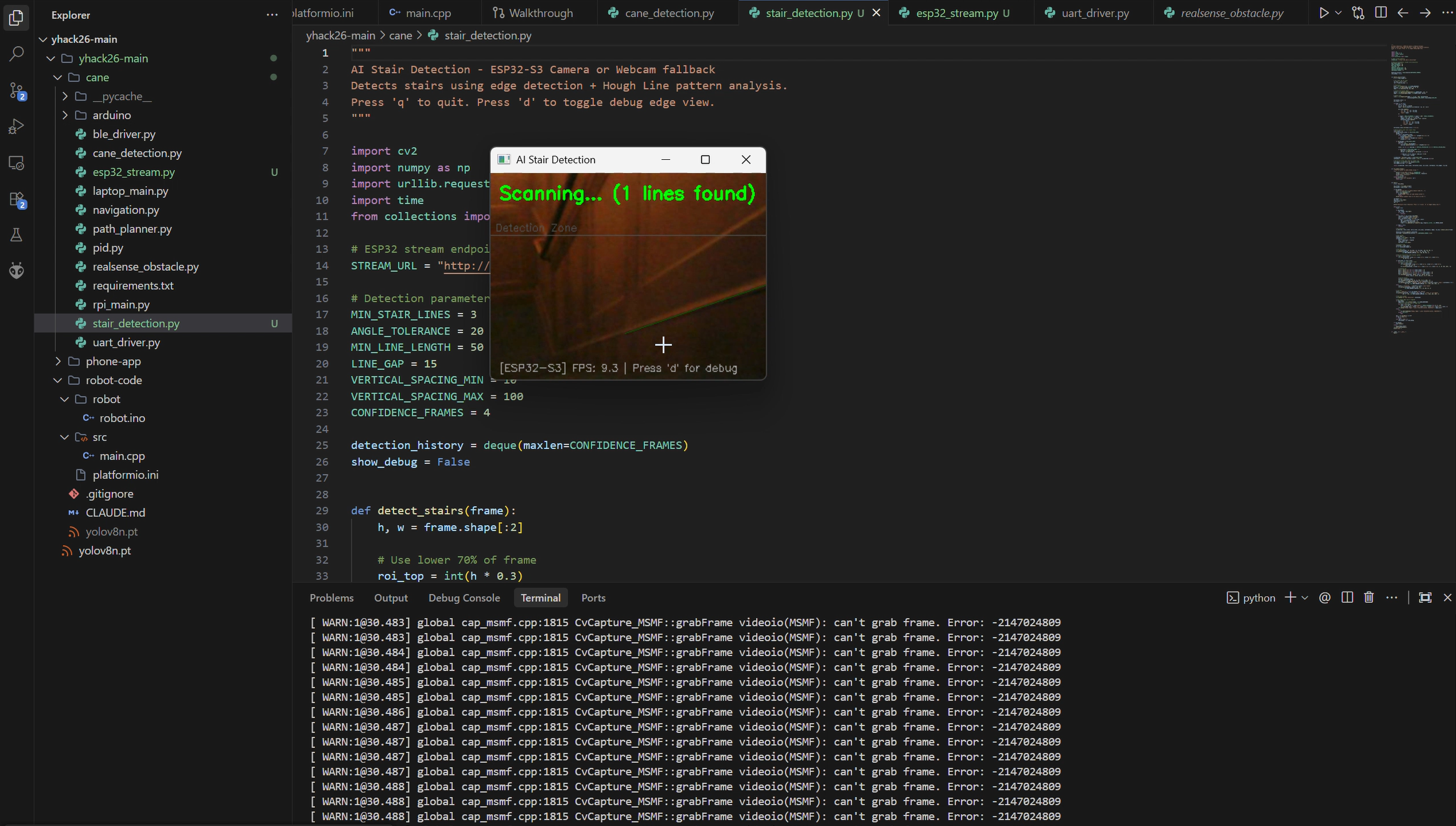
secondary camera detecting stairs



Inspiration
Every year, over 250 million people worldwide live with visual impairment. The current gold standard, a guide dog, costs $50,000–$60,000, requires two years of training, demands constant grooming and care, has a career span of only 7–10 years, and is frequently denied access illegally by businesses. The white cane, while affordable, is entirely passive: it tells you what's already in your path, not what's coming.
We asked ourselves: what if the cane could think? What if it could warn you, guide you, and navigate for you, like a guide dog, but in a device that fits in your hand and costs a fraction of the price? That question became LeadMe.
What it does
- LeadMe transforms a standard white cane into an active, AI-powered navigation partner. At its core is a motorized omnidirectional drive mounted at the cane's tip, giving it the ability to physically tug and push the user in any direction.
- Obstacle Avoidance — An Intel RealSense D457 depth camera continuously scans the environment. A YOLO v8 object detection model identifies obstacles in real time. When something enters the danger zone, the motors apply a differential arc maneuver — steering around the obstacle while maintaining overall forward progress. The user physically feels the cane pulling them to safety.
- Voice Warnings — When an obstacle is detected, LeadMe speaks aloud using Lava AI as the inference provider, routing requests to ElevenLabs' ultra-low-latency TTS model (eleven_flash_v2) via the lava.so forward proxy, saying "Stop!" with natural human speech.
- Voice Navigation — The user speaks a destination naturally ("Take me to Central Park"). LeadMe uses Lava AI to route ElevenLabs' scribe_v1 speech-to-text model to transcribe the command, geocodes the destination via OpenStreetMap Nominatim, and fetches a walking route from the OSRM open routing engine. The route is rendered as a live map with real OSM tile imagery displayed in a dedicated window — and crucially, LeadMe doesn't just show the map. The motorized cane tip physically guides the user along the route in real time, applying directional force through the handle to pull them along the correct heading at each step, turning navigation from something you read on a screen into something you feel in your hand.
- Real-Time 3D Visualization — A second window renders a live 3D matplotlib scene showing detected obstacles as positioned boxes in space, with a projected Bezier path curve showing the robot's planned trajectory.
- Intelligent Path Overlay — The primary camera feed displays smooth cubic Bezier avoidance curves rendered in real time over the live video, showing the planned arc path around each detected obstacle.
How we built it
The hardware stack centers on an Arduino-controlled differential drive platform with two front motors, an Intel RealSense D457 for simultaneous RGB and depth perception, and a host laptop running the full AI pipeline over USB. The Arduino firmware implements a simple ASCII serial protocol (angle|velocity|rot\n) with a 500ms hardware watchdog: if the host stops sending commands, the motors cut automatically. A HC-SR04 ultrasonic sensor provides additional ground-level distance data streamed back at 80ms intervals.
On the software side, we built everything in Python. The core loop runs YOLO v8n inference on each color frame from the RealSense, cross-references bounding box centers against aligned depth frames to get true 3D distances, and classifies objects into left, center, and right detection zones. When the center zone is blocked within 2 meters, the system samples the lateral zones and arcs toward whichever side has more clearance.
Voice I/O is powered by Lava AI, which acts as a unified inference gateway to ElevenLabs. The same Lava API key handles both speech synthesis for real-time obstacle warnings and speech-to-text for destination input, routing to ElevenLabs' eleven_flash_v2 model for TTS and scribe_v1 for transcription via the lava.so forward proxy. Audio is captured with sounddevice, saved as PCM WAV, and posted as multipart form data through Lava's forwarding endpoint.
Challenges we ran into
- Hardware setbacks derailed our original architecture. Our initial plan was to run the full AI perception pipeline locally on a Jetson Orin Nano mounted on the cane — giving us an untethered, self-contained device. We ordered the wrong power cable, and with no time to source a replacement at the hackathon, the Jetson was dead weight. We pivoted to running the pipeline on a laptop over USB, which meant rethinking the entire compute and communication architecture on the fly.
- We then attempted to use a Raspberry Pi as an intermediate bridge, but hit an immediate wall: we had no micro-HDMI cable, making it impossible to configure or even verify the Pi was booting correctly. We couldn't debug it blind. Two hardware failures in the first few hours forced us to strip the system down to what we could actually make work — and build something impressive anyway.
- Depth camera minimum range. The RealSense D457 has a hardware minimum of ~0.6m, which meant obstacles were detected far too late at first. We solved this by expanding the detection zone, widening the center threshold, and using the 10th percentile of sampled depth points rather than the minimum — filtering noise while catching real obstacles earlier.
- Arc direction math. The Velocity_Controller on the Arduino treats positive rotation as counter-clockwise. Getting the arc left/right signs correct took more iteration than expected: the robot was initially steering the wrong way entirely.
- ElevenLabs API routing through lava.so. The forward proxy URL format, correct auth header encoding (plain Bearer, not base64), and supported model IDs all required working through trial and error.
Accomplishments that we're proud of
- A fully working real-time obstacle avoidance loop that physically steers around objects while maintaining forward direction: not just stopping, but navigating.
- End-to-end voice navigation: speak a destination, get a rendered map with a walking route, no API keys beyond lava.so.
- Natural speech warnings using human-quality voice synthesis rather than beeps or buzzes.
- A 3D live visualization of the robot's perceived environment and planned path — compelling enough to demo on its own.
What we learned
We learned that hardware minimum ranges are not soft limits: they fundamentally shape how detection algorithms must be tuned. On the product side, this project made viscerally clear how much of the world is designed assuming you can see it, and how little engineering effort it would actually take to change that.
What's next for LeadMe
Stair and curb detection using the depth point cloud, overhead hazard sensing for head-level obstacles, indoor positioning using BLE beacons for GPS-denied environments, and a companion mobile app that handles voice commands and destination history. The long-term vision is a device that does everything a guide dog does, at 1% of the cost, available to anyone, anywhere.






Log in or sign up for Devpost to join the conversation.