Inspiration
Working firsthand in marketing operations, I've seen how important it is to have a streamlined process for lead management and enrichment. Sales teams must be able to cut through the noise and prioritize the high-quality leads with the highest chances of buying. But how do you identify them properly when you have only a few pieces of their data? Legacy systems often fall short by providing incorrect or outdated enrichment information. Moreover, lead scoring is often just a basic if-else condition that doesn't capture the full depth of a lead's background, the pain points they may experience, and their current situation at their company. LeadIQ aims to bridge that gap, providing a modern AI-first solution for lead enrichment and scoring.
What it does
LeadIQ is a lead enrichment and qualification tool that helps sales teams identify and qualify leads instantly using AI-powered extensive web search and enrichment.
Powered by the Perplexity Sonar API, it performs real-time web research on leads and their companies, scoring them based on various predefined factors such as company size, industry, and buyer persona.
Using only basic information such as a person's full name and their company, LeadIQ can instantly enrich the lead with relevant data points including their job title, LinkedIn profile, buyer persona, company information, and more. To ensure easy verification of the provided data and build trust with the end user, the tool provides source URLs, allowing users to cross-check the information. The tool allows users to manage leads, view detailed information and an aggregate dashboard with key metrics, and track lead status through a user-friendly interface.
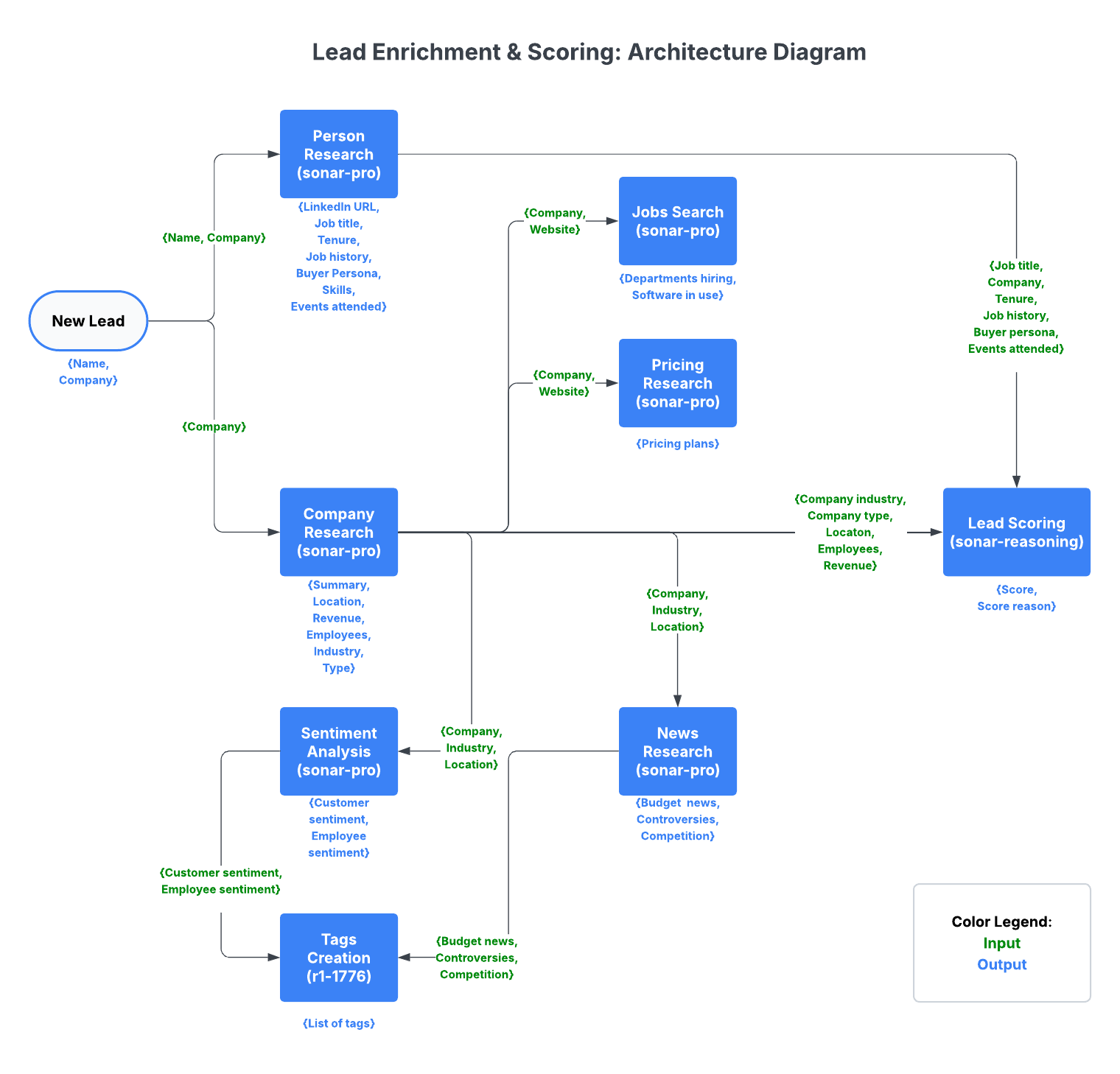
Data Enrichment Process
Data enrichment involves a multi-step process, including:
Person Research
Input: Full Name, Company Name
Output:
- Current Job Title
- LinkedIn URL
- Education: University name, degree, and graduation dates
- Tenure: Months at current company
- Job History: Previous companies, positions, and dates
- Skills: Inferred from job history
- Buyer Persona: Decision-maker, influencer, or end-user
- Events Attended: Participation in recent in-person or online conferences
Company Research
Input: Company Name
Output:
- Company Summary
- Website
- Industry
- Company Type: Public, Private, Non-profit, Startup (VC-backed), Solopreneurship
- HQ Location: City and country
- Revenue: Latest annual revenue (in USD)
- Employee Count: Latest figure or estimated range
Sentiment Analysis
Input: Company Name, Location, Industry
Output:
Customer Sentiment
- What are customers saying about the company and its offerings?
- Are there recurring complaints, praise, or notable feedback?
- Which features or services are most appreciated or criticized?
Employee Sentiment
- What do current and former employees say about working there?
- Are there common complaints or points of praise?
- What are the main reasons for employee turnover?
News Research
Input: Company Name, Location, Industry
Output: A comprehensive search of recent (last 30 days) news articles to identify:
Budget-Affecting Events
- Mergers, acquisitions, board changes, funding rounds, leadership shifts
Controversies or Challenges
- Legal issues, data breaches, PR incidents, regulatory scrutiny
Competitive Landscape
- Market shifts or competitor actions impacting the company's strategy
Job Openings Analysis
Input: Company Name, Website
Output:
- Departments Hiring: Which teams are actively hiring?
- Software In Use: What tools and software are mentioned in job descriptions?
Pricing Research
Input: Company Name, Website
Output: Analysis of the company's pricing page:
- What pricing tiers or plans are available?
Tag Summarization
Input: Customer sentiment, employee sentiment, budget-affecting events, controversies, competitive landscape
Output: Based on the research, the reasoning model returns up to 3 key tags that summarize major themes, tone, or business context, such as:
- Funding Round
- Layoffs
- Leadership Change
- Upcoming IPO
- Customer Backlash
Lead Scoring
Input: Job title, tenure, company, industry, job history, buyer persona, events attended, company type, location, number of employees, revenue
Output:
- Score: 0-100 points
- Score Reason: Reasoning behind why a lead received a specific score
The reasoning model scores each lead on a scale from 0 to 100 using the following criteria:
Scoring Guidelines (100 points total)
- Job Title (1–10 pts): C-level, VP, and Director roles score highest
- Tenure (1–10 pts): Longer tenure indicates stability
- Job History (1–10 pts): Preference for experience at reputable tech companies
- Buyer Persona (1–10 pts): Decision-makers and influencers get higher scores
- Events Attended (1–10 pts): Preference for AI, tech, or relevant industry events
- Industry (1–10 pts): Tech, finance, healthcare, and education are preferred
- Company Type (1–10 pts): VC-backed startups and public companies favored
- Recent Events (1–10 pts): Funding, acquisitions, or leadership changes add value
- Employee Count (1–10 pts): Ideal range of 50–500 employees
- Revenue (1–10 pts): Higher scores for revenue over $1M annually
Lead Disqualification Criteria
For demo purposes, the following lead disqualification criteria were applied:
A lead is scored 0 if:
- The individual is not a verified employee or is not a real person
- The company is based in or conducts active business in: Russia, Belarus, North Korea, Iran, Syria, or China
- The company operates in unethical industries, such as:
- Gambling
- Adult entertainment
- Weapons manufacturing
How we built it
LeadIQ is built using the Perplexity Sonar API for data enrichment, Streamlit for the frontend, and Supabase for the database.
AI Models and Architecture
The app utilizes 3 Perplexity models for different use cases:
Sonar-Pro
Used for enrichment with real-time web research, including:
- Person research
- Company research
- Sentiment analysis
- News research
- Job openings analysis
- Pricing research
Sonar-Reasoning
Handles lead scoring, which requires advanced reasoning capabilities to evaluate multiple data points and assign appropriate scores.
R1-1776
An offline DeepSeek R1 model for creating tags based on provided information. Since we don't need real-time data for this task (the research is provided as input from other steps performed previously by Sonar-Pro), we use the offline model with advanced reasoning capabilities.
Technical Implementation
To ensure high accuracy and easy parsing of the model's output, each API call uses response_format with a predefined JSON schema using Pydantic classes.
For news search, we focus on the last 30 days to ensure the information is relevant and up-to-date by using search_recency_filter = "month".
Database Backend
To simulate a real-world lead database, we used Supabase for storing incoming leads and enriched information. Users can add new leads, update them with enriched data, and delete leads as needed.
Frontend
The frontend is built with Streamlit and enhanced with custom CSS for styling and layout. The app is designed to be user-friendly, featuring:
- A dashboard displaying lead metrics
- A detailed view for each individual lead
- Intuitive navigation and data management capabilities
Deployment
For accessing the app during judging period, we used Streamlit Community Cloud for deployment.
Challenges We Ran Into
Overall, building with the Perplexity Sonar API was a great and seamless experience. A few challenges we faced were:
- API Response Parsing: Ensuring the API responses were parsed correctly and consistently across all models
- Schema Complexity: We tried using more complex response format schemas, but they were not always reliable. We ended up using simpler schemas for most cases to maintain consistency
- Responsive Design: Creating a fully responsive and usable application was a great challenge we enjoyed solving!
Accomplishments That We're Proud Of
- Successfully integrating multiple Sonar models to create a comprehensive lead enrichment and scoring solution
- Building a user-friendly interface that allows users to manage leads easily
- Implementing a robust backend with Supabase for data storage and management
- Ensuring high accuracy and reliability of the data enrichment process
- Creating a visually appealing dashboard with key metrics and insights
What We Learned
We gained valuable experience using the Perplexity Sonar API, as well as building a full-stack application with Streamlit and Supabase.
Being able to reference real-time web data through an LLM is a true game-changer for many real-world applications! We also learned about the importance of user experience in designing a lead management tool.
Additionally, we experimented extensively with different prompts and response formats to ensure the API returned the most accurate and usable data.
What's Next for LeadIQ - Data Enrichment and Scoring
The next steps for LeadIQ include:
- Custom Qualification Criteria: Adding the ability for users to select fields/enrichment categories and define their own lead qualification criteria
- Persistent Company Data: Storing company research separately so the same company is not enriched multiple times, improving efficiency and reducing API costs
- Form Integration: Integration with forms filled on websites or popular form tools
- CRM and Marketing Automation: Developing integrations with marketing automation tools and popular CRMs such as Marketo, HubSpot, Salesforce, and others
There's a lot to tackle and improve, and we are excited to continue building on this foundation!
Built With
- perplexity
- python
- sonar
- streamlit
- supabase

Log in or sign up for Devpost to join the conversation.