-
main page
-
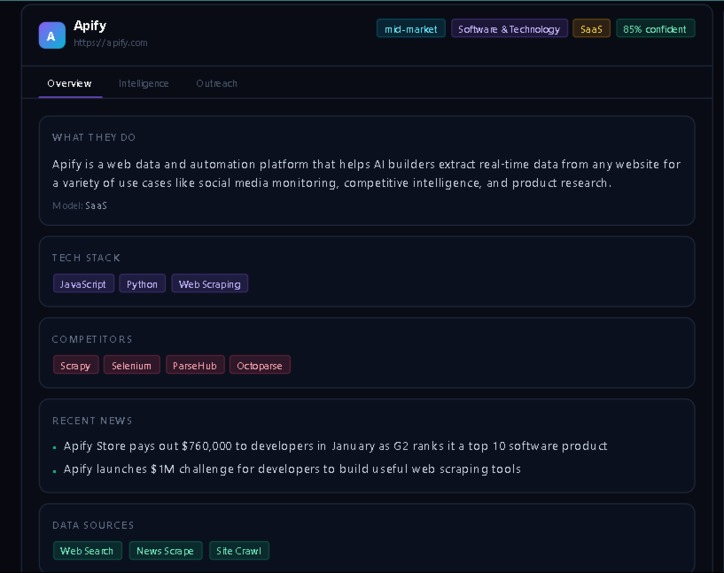
response
-
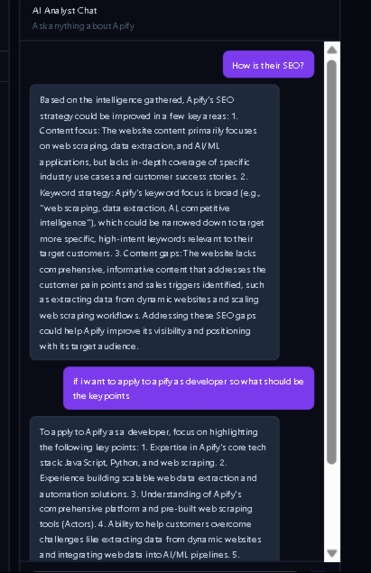
live chat
Inspiration
Every B2B sales rep knows the pain: you spend 3-5 hours manually researching a prospect before writing one cold email. You check their website, Google their news, dig through LinkedIn, look up their tech stack on BuiltWith, check G2 for complaints — then stitch it all together into something useful.
Tools like Apollo and ZoomInfo charge $300-500/month for static databases that go stale. Nobody gives you live intelligence scraped right now. And nobody lets you talk to the data.
That gap is what inspired LeadHunter AI.
What it does
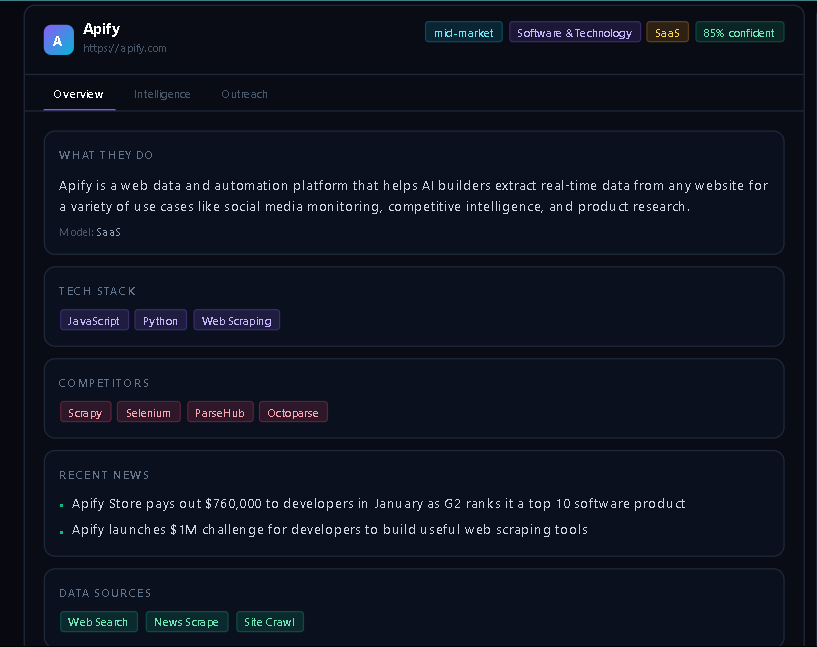
LeadHunter AI is a live B2B intelligence engine. You give it any company name and website URL. Within 60 seconds it returns:
- Company overview — what they do, business model, size
- Tech stack — technologies detected from their site
- Pricing intelligence — pricing model, tiers, signals
- SEO & content signals — keyword strategy, content gaps
- Competitor mapping — who they compete with
- Buying signals — trigger events indicating they need you now
- Messaging weaknesses — gaps in their positioning
- Customer complaints — what real users say on review sites
- Recent news — funding, launches, partnerships
- Cold email — personalized for any target role
- LinkedIn DM — short connection message
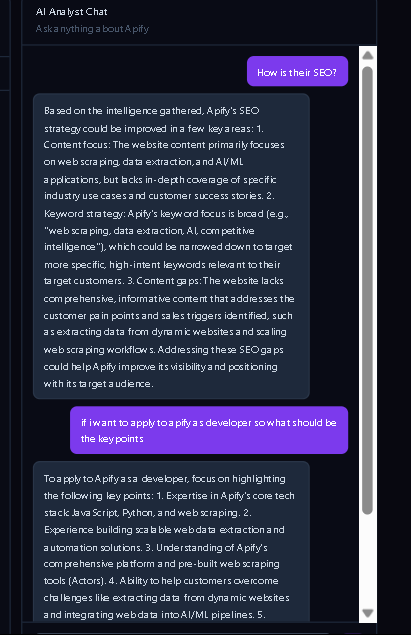
- AI chat panel — ask anything: "What's their pricing strategy?", "Write a LinkedIn message", "How's their SEO?", "What do customers complain about?"
The key differentiator: after the brief loads, a chat panel appears on the right side of the screen. The AI already has full context of everything scraped — you can interrogate it like a real analyst without any re-scraping.
How we built it
Three-layer architecture:
Apify Actor (
mashhoodrana/leadhunter-ai) — the published core engine. Written in Python using the Apify SDK. Runs three sub-Actors in parallel usingasyncio.gather():apify/rag-web-browserfor Google Search + web scrapingapify/rag-web-browseragain for news searchapify/website-content-crawlerfor deep site crawl All results are merged and fed to an LLM via OpenRouter.
FastAPI backend — orchestrates Actor calls via
apify-clientPython SDK. Two endpoints:/api/analyzetriggers the Actor and waits for results,/api/chattakes the scraped context and answers follow-up questions using the same LLM.React + Tailwind frontend — two-column layout. Left panel shows tabbed intelligence (Overview / Intelligence / Outreach). Right panel is a pinned chat interface with suggested questions.
LLM: Claude 3 Haiku via OpenRouter — chosen for speed and structured JSON output reliability.
Challenges we ran into
- Memory limits on free Apify tier — running three Actors in parallel hit the 8GB memory ceiling. Fixed by capping each sub-Actor to 1024MB.
- Tailwind v4 breaking changes —
@tailwindcss/vitedoesn't support Vite 8. Solved by switching to Tailwind CDN for the hackathon demo. - Python venv conflicts on Windows — uvicorn installed into system Python instead of venv. Fixed by invoking pip directly through the venv Python executable.
- LLM JSON reliability — early prompts returned markdown-
wrapped JSON that broke parsing. Fixed with strict prompt
engineering and a cleanup step before
json.loads().
Accomplishments that we're proud of
- Published a functional Actor on Apify Store that anyone can call via API right now
- Full end-to-end pipeline working in under 90 minutes of active build time
- The chat interface genuinely feels like talking to an analyst — suggested questions, context-aware answers, no re-scraping needed
- Scraped a real university website (IST) and got accurate tech stack, pain points, and a personalized outreach email on the first try
- Replaced what would cost $300-500/month with a free, open-source, live-data alternative
What we learned
- Apify's
rag-web-browserin Standby mode is incredibly powerful — it handles Google Search + scraping + Markdown conversion in one call - Parallel Actor execution with
asyncio.gather()is the key to keeping latency under 60 seconds despite three concurrent scraping jobs - Prompt engineering for structured JSON output is underrated — the difference between a working product and a broken parser
- The real value of live web data vs static databases is not just freshness — it's depth. You find pricing pages, review complaints, and SEO gaps that no database captures
What's next for Lead Generation AI
- Bulk mode — upload a CSV of 100 companies, get 100 briefs
- CRM integration — push briefs directly to HubSpot/Salesforce
- Review site scraping — dedicated G2/Capterra/Trustpilot Actor for deeper customer sentiment
- Monitoring mode — re-scan companies weekly, alert on changes (new funding, new job postings, pricing changes)
- Chrome extension — run LeadHunter on any LinkedIn profile or company page with one click
- Monetization — publish on Apify Store with pay-per-run
pricing using
Actor.charge()```

Log in or sign up for Devpost to join the conversation.