


Tribal
Inspiration
Elephant researchers collect thousands of field recordings, but much of it is unusable. Calls are buried under airplane rumble, vehicle traffic, and generator hum, often overlapping in the same frequency range of 10–1000 Hz.
The core challenge is that elephant calls and mechanical noise look nearly identical in frequency. Traditional denoising fails because it treats sound as static. The real signal is in how sound changes over time. Elephant calls are dynamic and burst-like, while engines are steady and continuous.
What it does
Tribal is a real-time AI system that runs entirely on a Raspberry Pi for localized field deployment, allowing researchers to process recordings directly at the source without relying on cloud infrastructure.
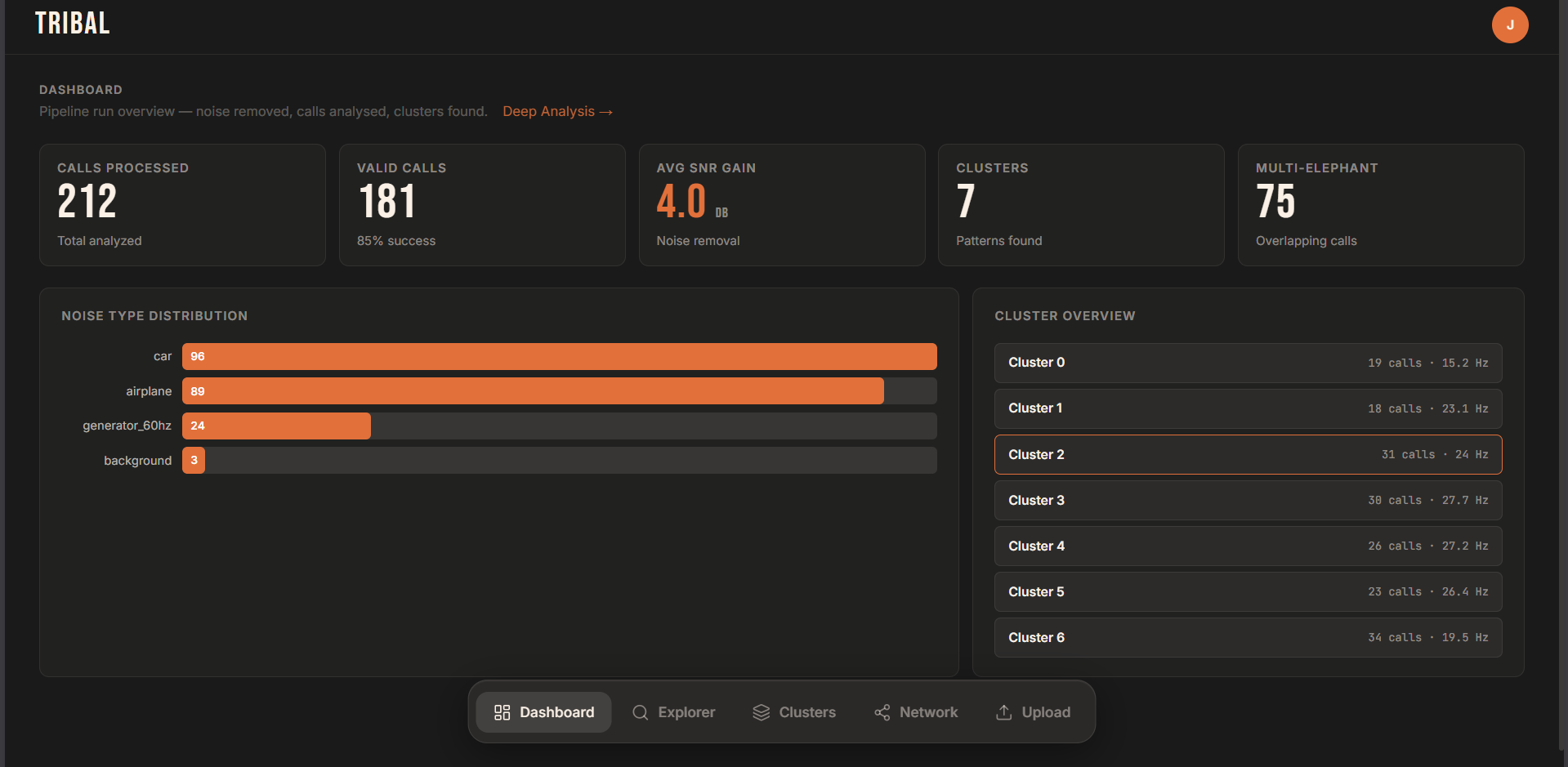
It removes 4–5 dB of background noise on average, reconstructs missing harmonics, detects and separates overlapping callers, and clusters calls into groups that reveal communication patterns.
It works fully offline, requires no training data, and processes a 10-second call in about 1.5–2 seconds using less than 200 MB of memory.
The result is clean, structured data that turns previously unusable recordings into meaningful insight about elephant communication and behavior.
How we built it
Tribal is built as a lightweight, multi-agent pipeline optimized for edge devices. Each stage runs as an independent process, passing messages through queues. This avoids shared memory, prevents system-wide failure, and keeps performance stable on low-power hardware.
The pipeline
Preprocessing
Audio is downsampled from 44.1 kHz to 4 kHz and bandpass filtered between 10–1000 Hz. This removes irrelevant frequencies and reduces compute load. Noise reference segments are also extracted.
Noise fingerprinting
We compute power spectral density to classify noise sources like generators, airplanes, and vehicles. This informs how aggressively different frequencies should be suppressed.
Core separation (NMF)
We convert audio into a spectrogram and apply Non-negative Matrix Factorization to decompose it into components.
Each component is scored using:
- Harmonic structure (fundamental frequency and integer multiples)
- Temporal variation (coefficient of variation)
Elephant calls show high temporal variation (around 1.5 or higher), while engines remain low (around 0.1–0.2). This becomes the key discriminator.
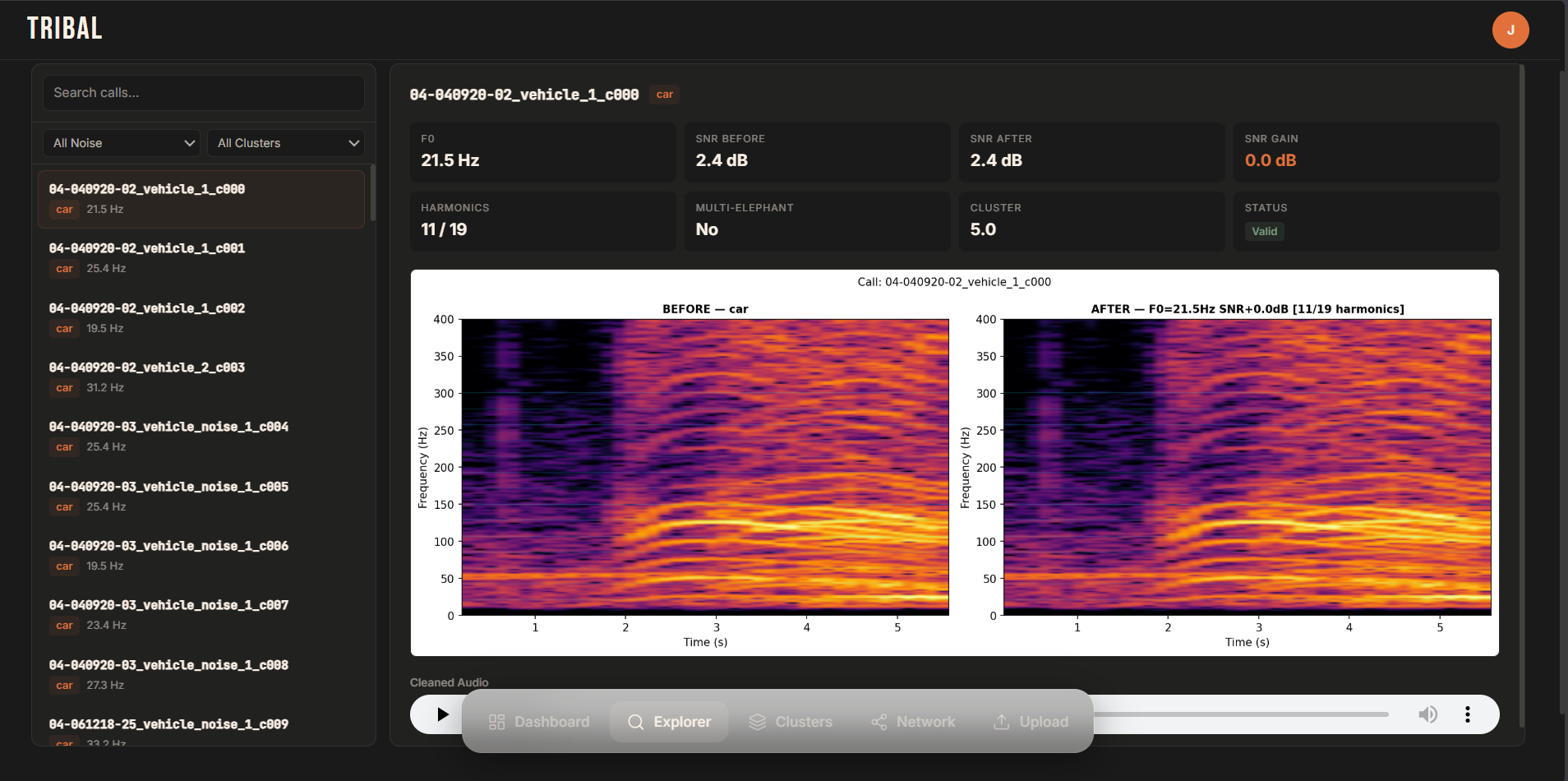
We select the top components and apply a soft Wiener mask to separate signal from noise without introducing artifacts.
Reconstruction
Lost harmonics are recovered using an exponential decay model, preserving the natural structure of the call.
Overlap detection
We detect multiple callers by identifying separate fundamental frequencies at least 5 Hz apart with sufficient harmonic support. If present, we split them into separate tracks using competitive masking.
Quality scoring
We compute tonal SNR, harmonic completeness, and a validity flag. If quality drops, we revert to the original audio to avoid degradation.
Clustering and analysis
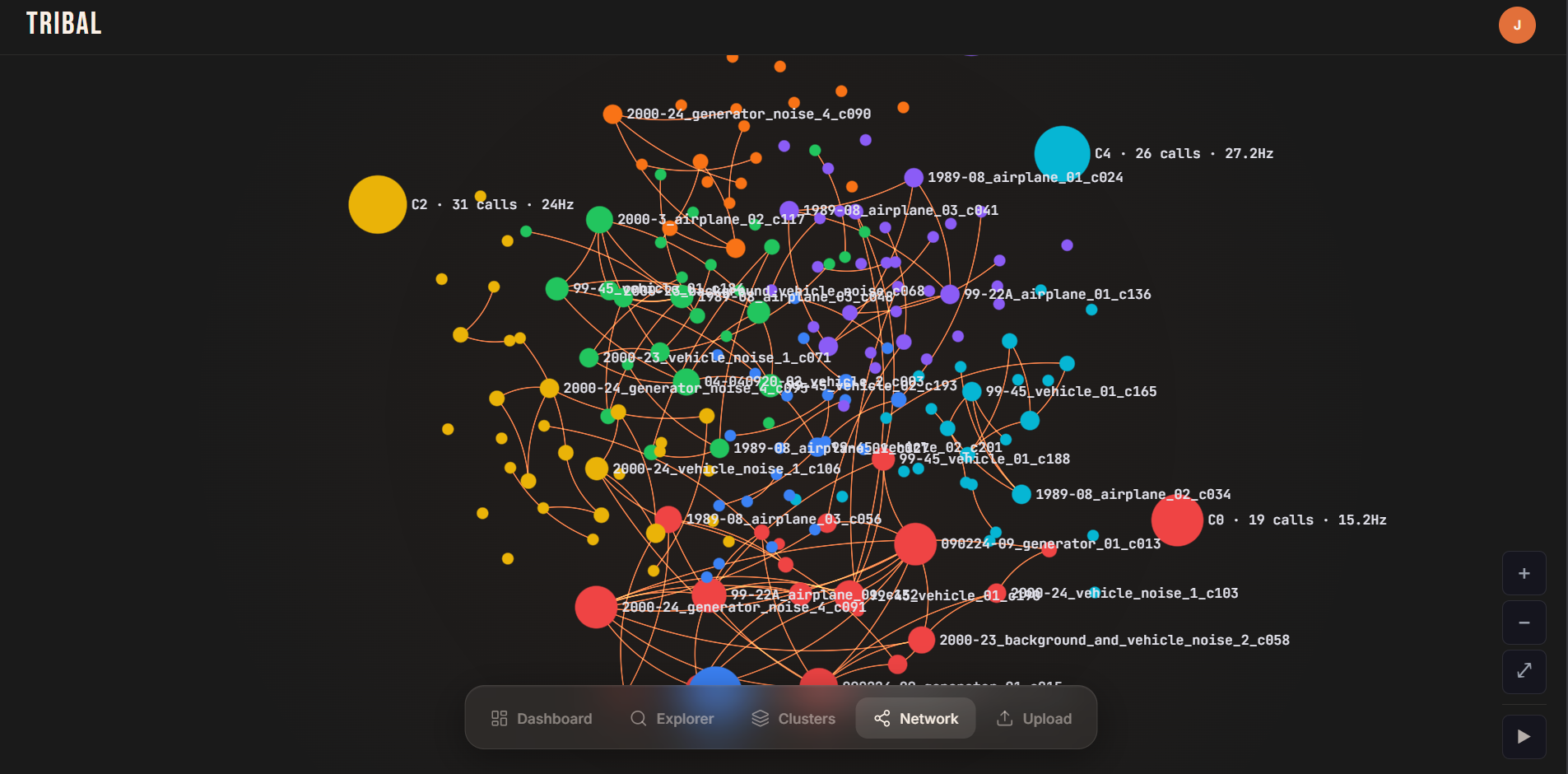
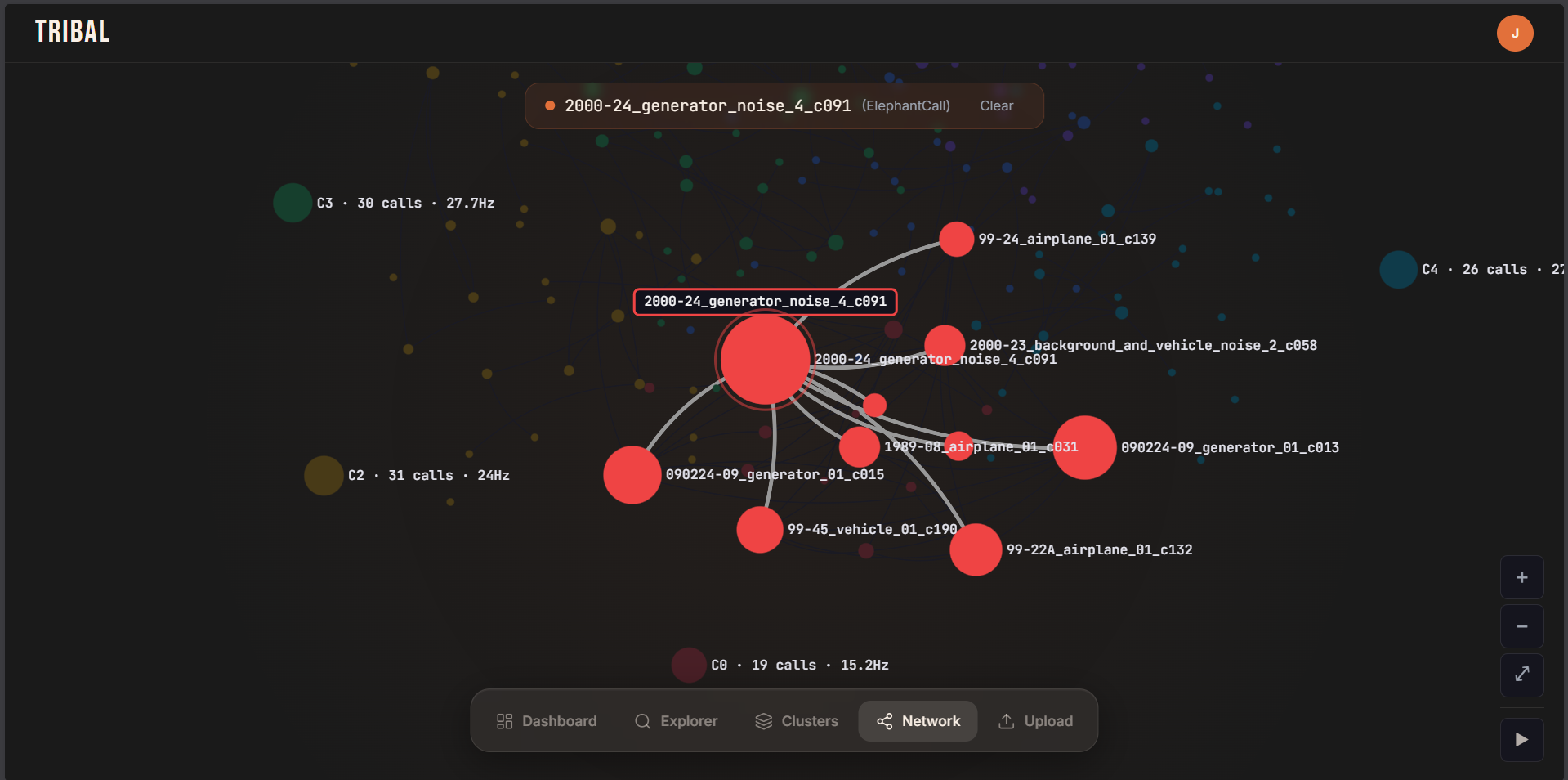
We embed cleaned calls into a low-dimensional space and cluster them into groups called tribes. These clusters are not just grouping similar sounds, they begin forming a relational structure between calls. The system builds a knowledge base that behaves like a connected network of acoustic relationships, where proximity in the graph reflects behavioral and contextual similarity, allowing us to move closer to inference through relationships rather than isolated signals.
This clustered structure becomes a reference layer for future reasoning and pattern discovery, not just storage.
Why it works
- Temporal variation separates elephant calls from mechanical noise even when frequencies overlap
- Harmonic structure ensures we preserve biologically meaningful signals
- Soft probabilistic masking avoids artifacts from hard filtering
- Physics-based reconstruction restores lost signal components
- Unsupervised learning adapts to any environment without training data
- Relational clustering turns isolated detections into structured behavioral context
Challenges we ran into
- Threshold-based selection collapsed and selected all components
- Spectral subtraction introduced musical noise artifacts
- Generator harmonics overlapped with elephant harmonics
- Masking removed real signal along with noise
- Dual-caller detection caused false positives
- Standard SNR metrics failed for tonal signals
- Memory and CPU limits on Raspberry Pi constrained model size
- Thermal throttling reduced performance over time
We solved these with top-K selection, soft masking, harmonic reconstruction, stricter dual-caller rules, tonal SNR metrics, and hardware cooling.
Accomplishments that we're proud of
- Fully unsupervised system with no training data required
- 4–5 dB average noise reduction without degrading signal quality
- Real-time performance on a Raspberry Pi deployed in-field
- 1.5–2 second processing time per 10-second audio segment
- <200 MB memory footprint on edge hardware
- Reliable separation of overlapping elephant calls
- Physics-based reconstruction of degraded harmonics
- Robust multi-process pipeline with graceful failure handling
- Emergent relational knowledge base from acoustic clustering
- Ability to recover usable data from previously unusable recordings
What we learned
- Time-based patterns are critical for separating natural signals from mechanical noise
- Domain knowledge can outperform generic machine learning approaches
- Soft probabilistic methods preserve quality better than hard thresholds
- System architecture is as important as model choice on constrained hardware
- Unsupervised quality evaluation requires domain-specific metrics
- Structured relationships between signals unlock deeper inference than isolated classification
What's next
- Deploy multiple Raspberry Pi units across field sites for wider coverage and passive long-term monitoring
- Add optional camera modules for multimodal correlation between audio and visual behavior
- Enable on-device parameter tuning for researchers in the field
- Extend the system to other species with similar acoustic patterns
- Improve clustering into richer behavioral and individual identity graphs
Tagline
Hear the herd
Repository
https://github.com/toosh-legacy/HACKSMU_26
Slide Deck: https://canva.link/0ezeouqd178z8zq
Built With
- nextjs
- python
- tailwind
- typescript











Log in or sign up for Devpost to join the conversation.