-
-
Landing Page
-
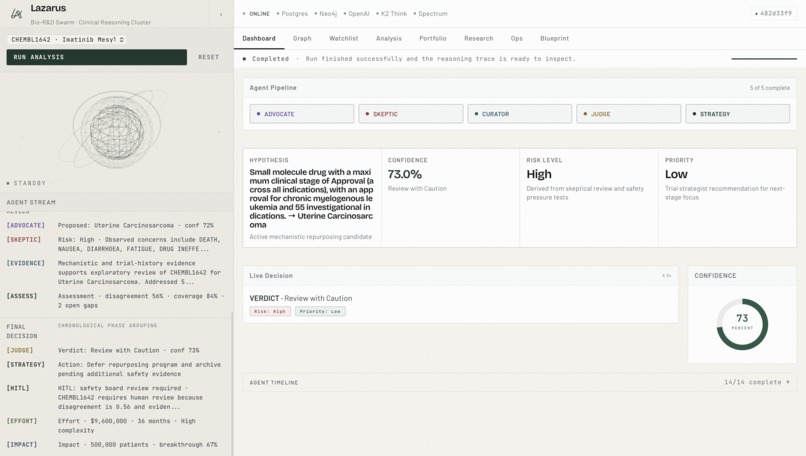
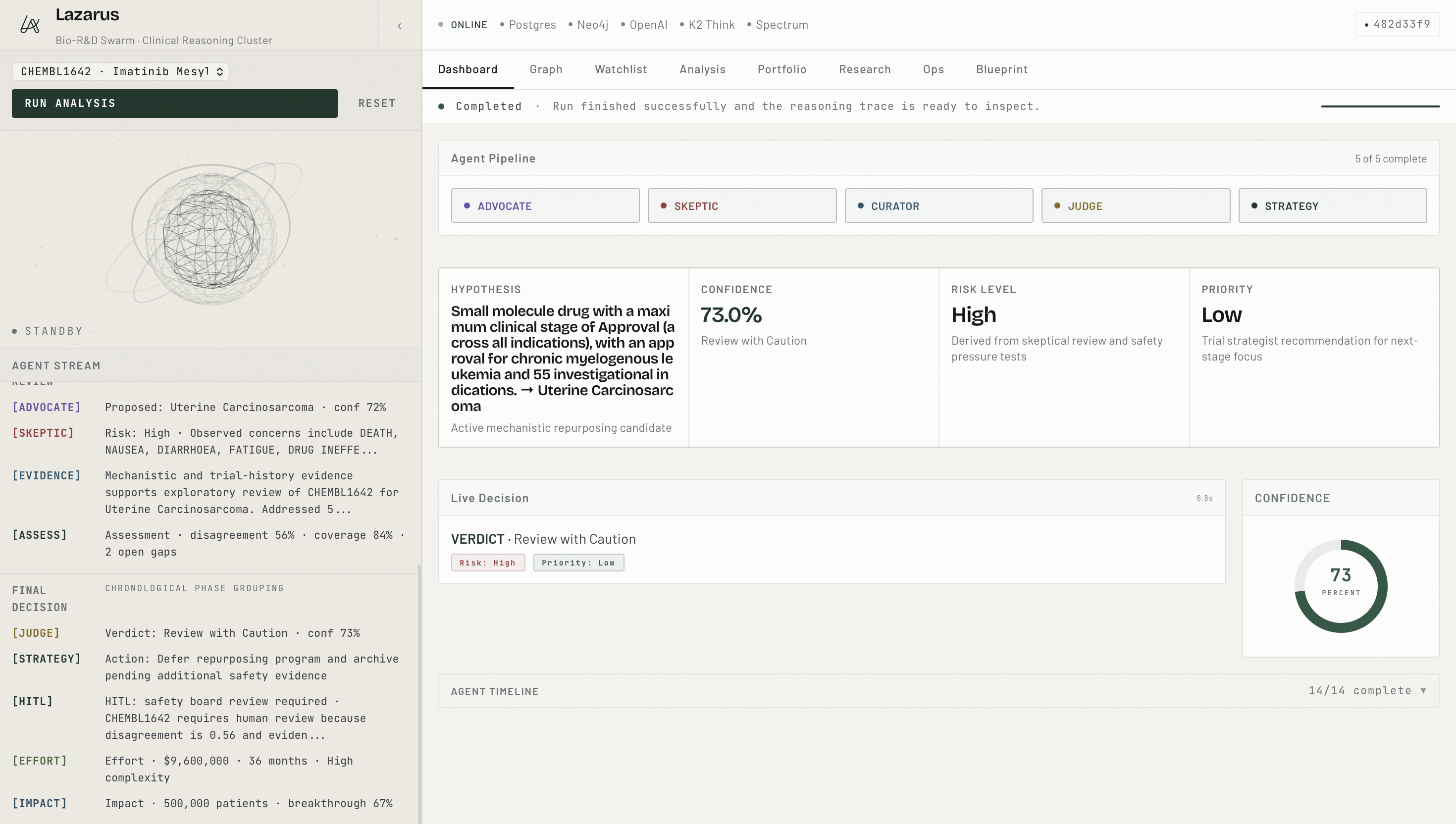
Dashboard
-
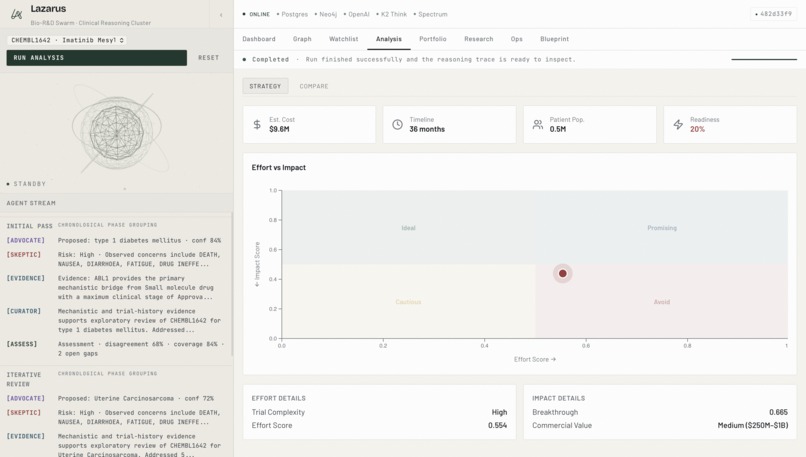
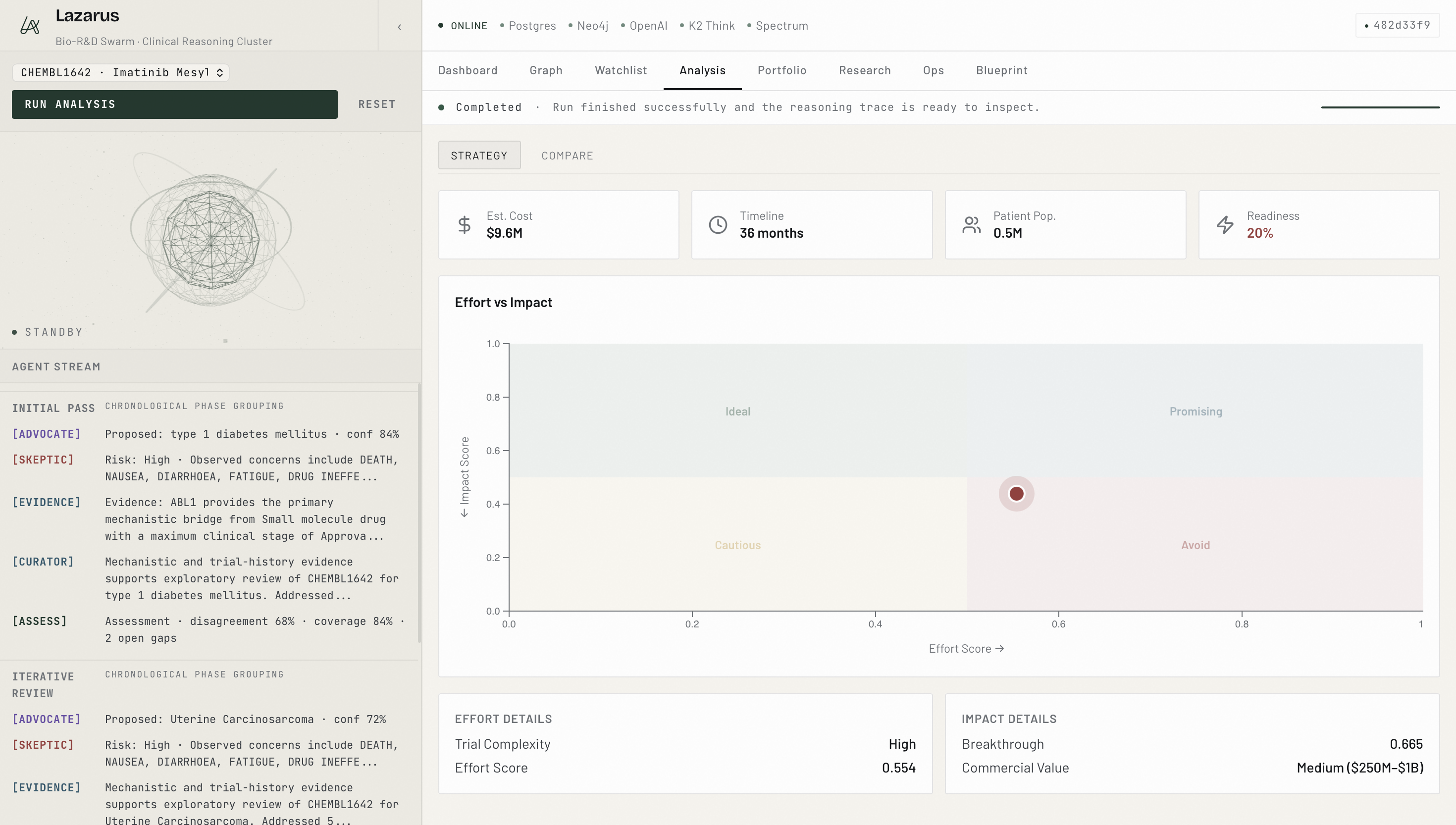
Analysis
-
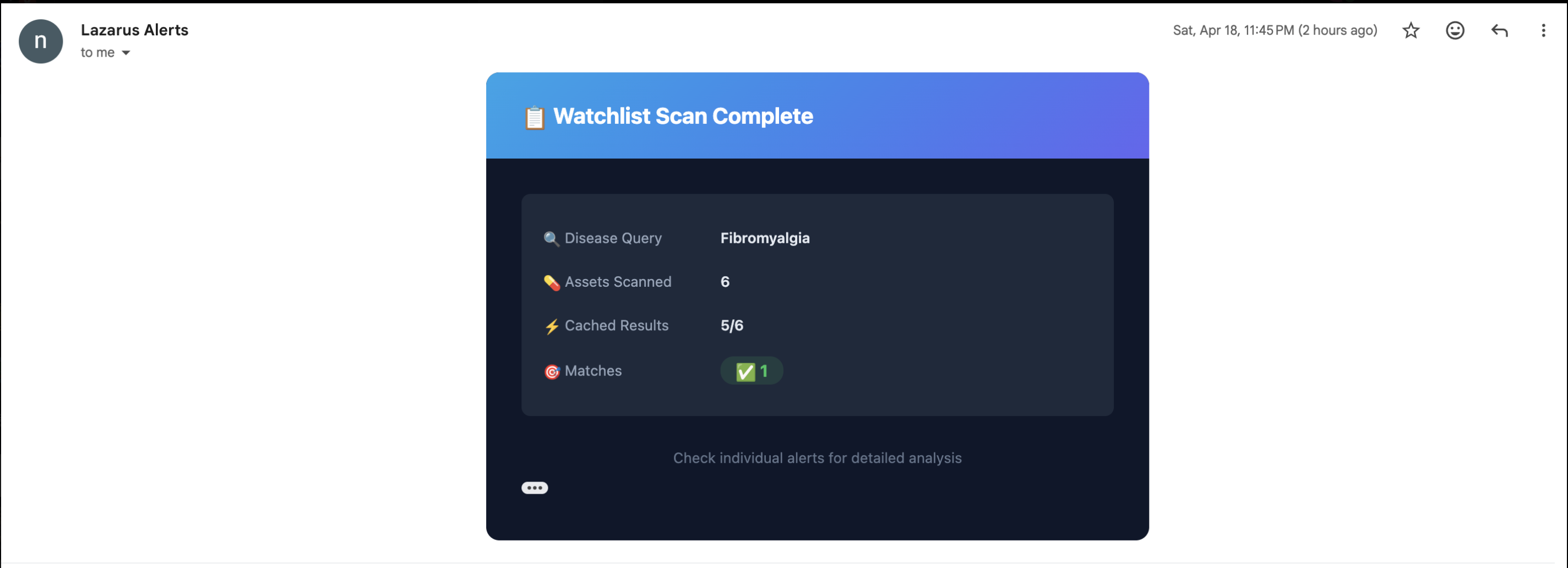
iMessage Alerts
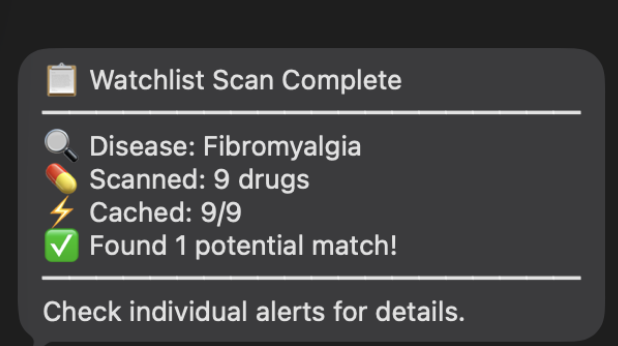
-
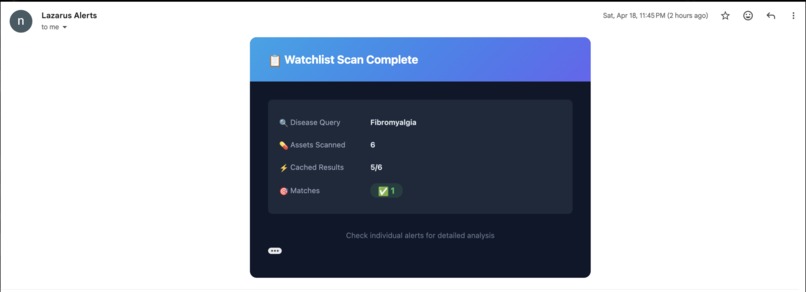
Email Alerts

Inspiration
Every large pharma company sits on a graveyard of shelved drug programs molecules that cleared Phase I safety, showed real biological activity, then got killed for reasons that had almost nothing to do with the chemistry. Portfolio pivots. A bad readout in the wrong indication. A merger. A patent cliff. A CFO.
We kept running into the same statistic: roughly 90% of drugs that enter clinical trials never reach patients, and the industry spends north of $200B/year developing new ones while the shelved assets, which already have human safety data, sit untouched. The scarce resource in drug repurposing isn't molecules or data; it's reasoning capacity. No human team can read every trial on ClinicalTrials.gov, cross-reference PubMed, weigh mechanistic plausibility, estimate trial cost, and do it across a whole portfolio.
That is an agent problem. So we built Lazarus an autonomous clinical R&D swarm that turns that graveyard into a live, rank-ordered opportunity surface.
What it does
Lazarus is a full-stack control plane for drug rescue. Given a shelved asset, it:
- Discovers candidate assets from ClinicalTrials.gov, PubMed, and openFDA.
- Reasons over each one with a DAG of nine specialized agents Advocate → Skeptic → Evidence Curator → Parallel Evidence Branches → Trial Strategist → Effort + Impact estimators → Judge → Follow-up Assistant streamed live to the UI over WebSocket.
- Ranks the portfolio across a composite score:
$$ \text{Score} \;=\; w_c \cdot C \;+\; w_i \cdot I \;-\; w_e \cdot E \;-\; w_h \cdot H $$
where C is final confidence, I is commercial impact, E is execution effort, H is human-review drag, and w* are tunable weights.
- Generates an executive-grade PDF blueprint (Jinja + WeasyPrint) for the winning hypothesis.
- Notifies stakeholders over an optional iMessage/Spectrum bridge, and can be driven end-to-end from a conversational OpenClaw desktop agent.
Operators get a dual UI an operator dashboard for portfolio-level triage, and a dedicated reasoning lab (/agent-trace) where every agent's input, output, score, and citations are visible in real time.
How we built it
Lazarus is architected as a live control plane, not a notebook.
Backend. FastAPI + SQLAlchemy 2 + Pydantic v2. Every run is persisted as agent_runs + agent_steps rows and simultaneously pushed to the client over /runs/{id}/stream the UI renders what actually happened, not what we guess happened.
Reasoning engine. An explicit orchestration service wires agents as a typed DAG with Pydantic contracts instead of a free-form ReAct loop. Each role runs on the model best suited to it:
| Role | Model |
|---|---|
| Advocate / Judge | OpenAI gpt-4o |
| Skeptic | OpenAI gpt-4o-mini |
| Evidence Curator / Parallel Branches | Google Gemini 2.5-flash |
| Trial Strategist | MBZUAI K2-Think v2 |
| Effort / Impact | Deterministic + LLM assist |
Dual store. Postgres holds operational truth (runs, hypotheses, blueprints, reviews). Neo4j holds the biological knowledge graph Drug ↔ Target ↔ Disease ↔ Evidence ↔ Hypothesis ↔ Strategy rendered in the UI via Cytoscape.
Frontend. React 18 + Vite 7 + Framer Motion + Three.js/R3F globe + Cytoscape + D3, with a dedicated reasoning lab so judges can literally watch agents think.
Agentic surfaces. An optional Photon/Spectrum iMessage bridge and an OpenClaw skill pack let operators kick off runs and pull blueprints from chat or a desktop agent.
Infra. Docker Compose for Postgres + Neo4j + Redis locally; Render (backend) + Vercel (frontend) in production.
Challenges we ran into
- Streaming reasoning over WebSocket while persisting to Postgres without blocking the orchestrator turned into a surprisingly subtle async problem. We ended up with a persist-then-broadcast pattern and a polling fallback (
/runs/{id}/trace) for flaky networks. - Cross-store consistency. Writing a hypothesis to Postgres and projecting it into Neo4j without creating orphan nodes during partial failures required idempotent upserts on the graph side and runtime migrations (
db.apply_runtime_migrations()) on the SQL side. - Hallucinated PubMed IDs were rampant in early Advocate outputs. We solved it by having the Skeptic fetch the cited PMIDs and fail the step if they didn't resolve.
- Live-demo reliability. Venue Wi-Fi is a threat model. We added
LAZARUS_DISCOVERY_DEMO_CACHE=trueto serve a canned ClinicalTrials.gov-shaped payload, so the demo never depends on a network we don't control. - PDF generation under load. WeasyPrint is gorgeous but slow; we moved blueprint rendering behind
/generate-blueprint/asyncwith a Postgres-backed job record so the UI stays snappy. - Human-in-the-loop gating. Low-confidence or high-disagreement hypotheses needed to be blocked from blueprinting, not just flagged. Modeling this as a first-class
HumanReviewtable with an escalation dashboard was the most boring and most important feature in the app. - Routing across three LLM providers (OpenAI, Gemini, K2-Think) meant three auth models, three rate-limit regimes, three failure modes. Deterministic fallbacks at the agent layer kept the pipeline coherent when any one of them flaked.
Accomplishments that we're proud of
- A reasoning trace you can actually watch. Every agent step is persisted and pushed over WebSocket the UI isn't a progress spinner pretending to be intelligence; it's a live, inspectable DAG.
- Nine-agent orchestration that doesn't degenerate. Advocate, Skeptic, Curator, Parallel Evidence Branches, Trial Strategist, Effort, Impact, Judge, and Follow-up all produce structured JSON under Pydantic contracts and every one has a deterministic fallback, so the pipeline never dead-ends.
- Real human-in-the-loop, not theater. Low-confidence hypotheses are gated behind a
HumanReviewqueue before they can be blueprinted. Reviewers have a first-class dashboard. - A Postgres + Neo4j split that earns its complexity. Operational truth stays ACID; the knowledge graph stays traversal-native. We resisted the temptation to collapse them.
- An executive-grade PDF blueprint rendered from Jinja + WeasyPrint with citations, mechanistic rationale, trial plan, and effort/impact economics the artifact a BD team would actually take into a meeting.
- Agentic surfaces beyond the browser. Lazarus can be driven from iMessage via the Photon/Spectrum bridge, or from a desktop OpenClaw agent, using the same token-gated API.
- Offline demo mode.
LAZARUS_DISCOVERY_DEMO_CACHE=truemeans the demo runs even if the venue Wi-Fi doesn't. - Shipped in 36 hours. A control plane, a graph, a reasoning lab, a PDF generator, an iMessage bridge, and an OpenClaw skill pack all integrated, all working.
What we learned
- Explicit orchestration beats ReAct for auditable science. A typed agent DAG cost us some flexibility but bought reliable, citable traces which is the product in a regulated domain.
- LLM pluralism is a real architecture decision. Routing by role GPT-4o for reasoning, Gemini Flash for cheap-and-fast evidence work, K2-Think for long-horizon trial planning produced dramatically better outputs than a monoculture.
- Hallucinated citations are the single biggest failure mode in scientific agents, and they have to be caught before the Judge, not after.
- Streaming is a first-class feature, not a UX flourish. Turning "trust me, the model is thinking" into a live, inspectable trace is what actually convinces a domain expert.
- Determinism is a demo survival skill. Fallbacks at the agent layer are the difference between a confident demo and a cold sweat.
- Human-in-the-loop is an architectural choice, not a disclaimer. If you want your agents taken seriously by scientists, you have to build the review workflow into the data model on day one.
What's next for Lazarus
- Redis-backed Celery / RQ workers for long-running async runs, replacing the current threaded executor so the pipeline can scale to portfolio-wide scans.
- Vector memory over
AssetMemoryandRunMemoryso agents can retrieve across prior runs, building institutional knowledge over time. - Graph-native ranking using Neo4j GDS portfolio-scale similarity search over the Drug / Target / Disease graph to surface non-obvious rescue candidates.
- Formal evals per agent hallucination rate, citation grounding, skeptic precision, judge calibration so we can tune each role independently rather than eyeballing outputs.
- First-class auth and multi-tenancy with row-level security, so multiple pharma teams can run isolated portfolios on the same deployment.
- Wet-lab integration. Pushing the top-ranked hypotheses into assay planning tools to close the loop between in silico reasoning and bench validation.
- Regulatory-aware blueprints. Extending the PDF generator to produce FDA 505(b)(2) and orphan-designation-ready packets directly from the hypothesis and evidence set.
- Productionizing the agent surface. Hardening the Photon/Spectrum and OpenClaw integrations with proper audit logging so a BD lead can legitimately run Lazarus from their phone.
Built With
- fastapi
- gemini
- javascript
- k2-think
- neo4j
- neon
- node.js
- openai
- openclaw
- photon
- postgresql
- python
- react
- render
- vercel
- vite






Log in or sign up for Devpost to join the conversation.