-
-
flujo
-
agente
-
agente
-
uso
Lázaro — Autonomía Proactiva en el Edge para la Discapacidad Visual
Inspiración
En México, moverse por la ciudad siendo ciego es una apuesta constante. Las soluciones actuales tienen una falla fundamental: la fricción. Obligar a un usuario a detenerse, sacar el teléfono, apuntar la cámara y esperar una respuesta de la nube no es autonomía — es una dependencia digital lenta.
Nos inspiró una figura cultural profundamente hispana: el lazarillo. La persona que camina al lado de quien no puede ver, que avisa antes de que haya peligro, que describe el entorno sin que se lo pidan. Quisimos resignificar ese rol con inteligencia artificial. No un asistente reactivo. Un compañero proactivo que ve en segundo plano, decide cuándo hablar y cuándo guardar silencio, y actúa solo cuando importa.
Pero también nos enfrentamos a una realidad: no todos tienen una el hardware necesario. Por eso Lázaro existe en dos configuraciones — porque la accesibilidad no admite fragmentación de hardware. Esa no fue una decisión de arquitectura. Fue una decisión de inclusión.
La tecnología no debe ser una herramienta que el usuario "opera". Debe ser invisible hasta que sea necesaria.
Qué hace
Lázaro es un asistente wearable de visión artificial que devuelve autonomía real a personas con discapacidad visual — sin pedirles que abran una app, toquen una pantalla ni pidan ayuda.
El sistema opera en dos configuraciones según el hardware disponible: una versión edge sobre Orange Pi 5 Max con Raspberry Pi Zero W como cámara inalámbrica, y una versión cloud/PC que funciona con cualquier webcam USB. Ambas resuelven el mismo problema desde realidades de hardware distintas.
Lázaro opera en cuatro modos:
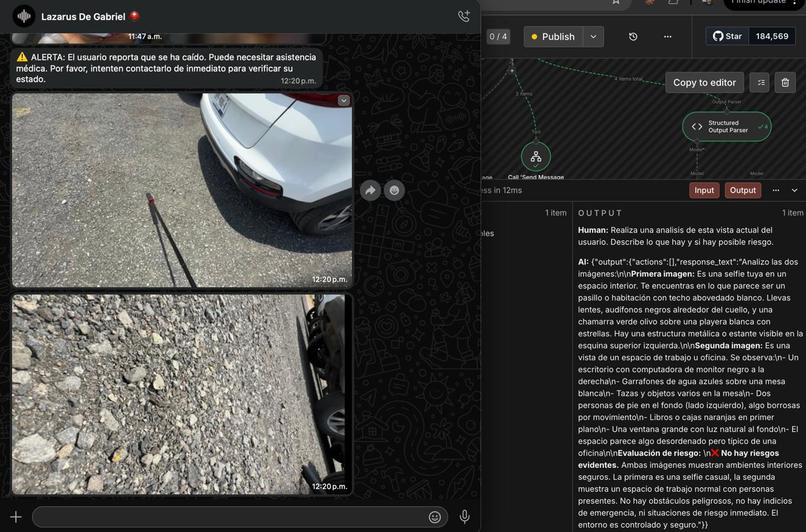
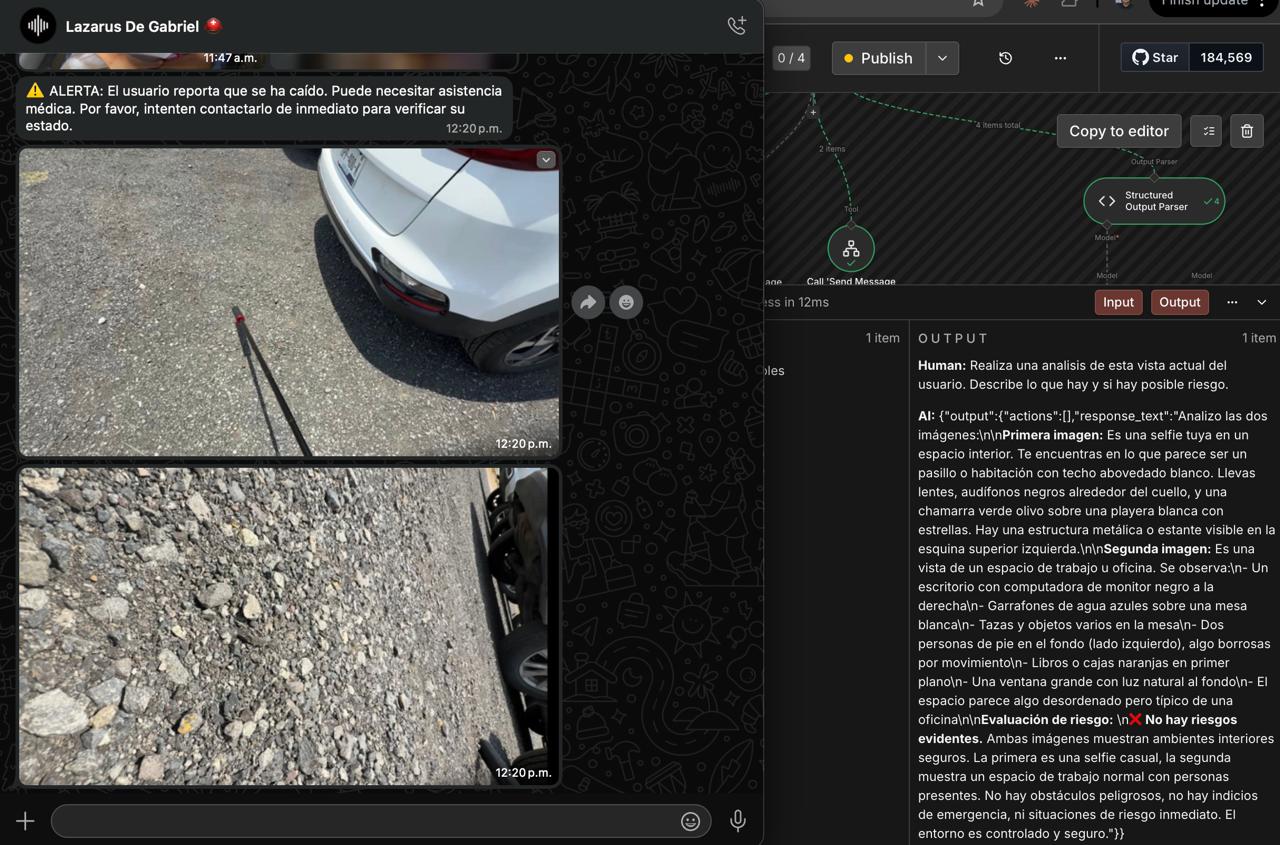
Proactivo — siempre activo en segundo plano. YOLOv8n-pose detecta objetos en la escena y un Alert Engine decide cuándo hablar y cuándo guardar silencio. El usuario no pregunta nada. Lázaro simplemente avisa: "semáforo en rojo", "perro suelto a tu izquierda", "escaleras adelante", "auto acercándose por la derecha." Sin interacción. Sin fricción.
Reactivo — el usuario hace una pregunta por voz. Whisper la transcribe localmente, el frame actual va a Gemini Vision con contexto temporal del ring buffer, y la respuesta llega en español natural en menos de dos segundos. "¿Qué dice ese letrero?", "¿Cuántas personas hay?", "¿Qué tengo enfrente?"
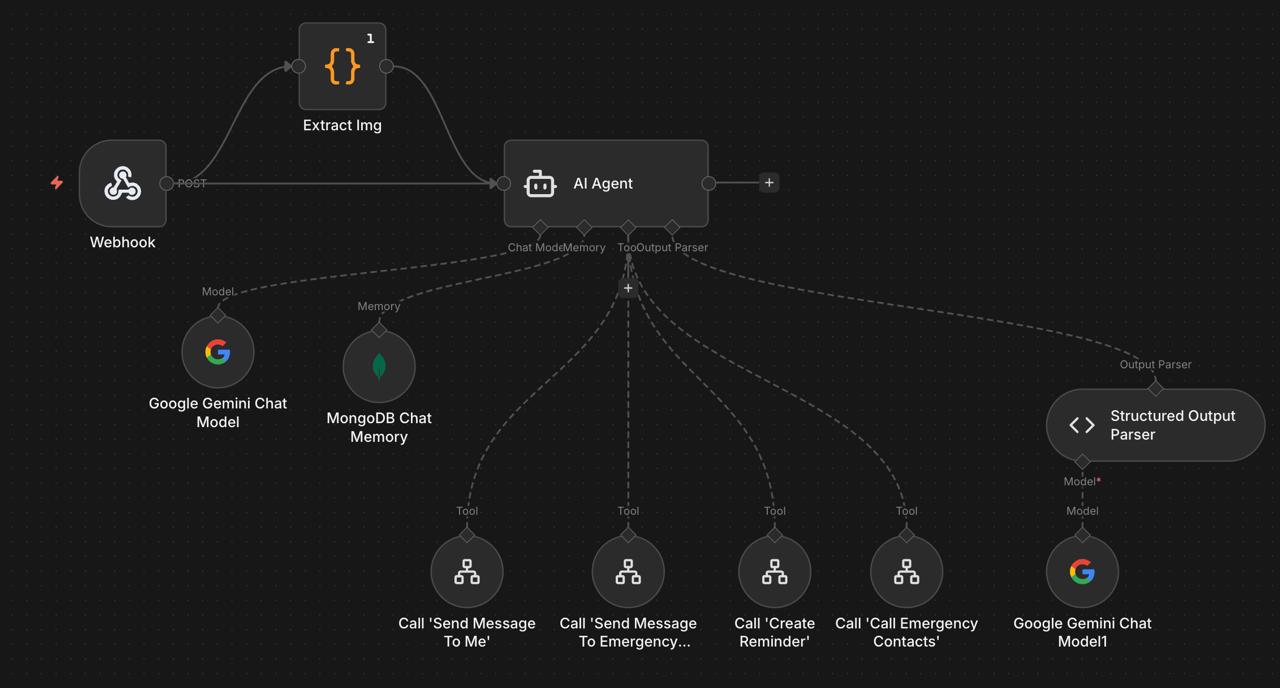
Memoria — el usuario graba un evento por comando de voz: una consulta médica, una clase, una reunión. Lázaro captura audio continuo y selecciona keyframes automáticamente. Al terminar, Whisper transcribe todo y Gemini 1.5 Pro genera un reporte estructurado — diagnóstico, medicamentos, dosis, instrucciones, tareas — guardado en MongoDB y consultable después por voz.
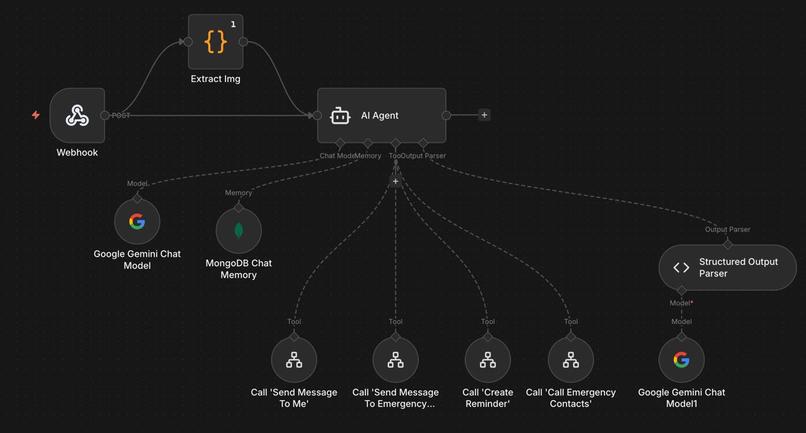
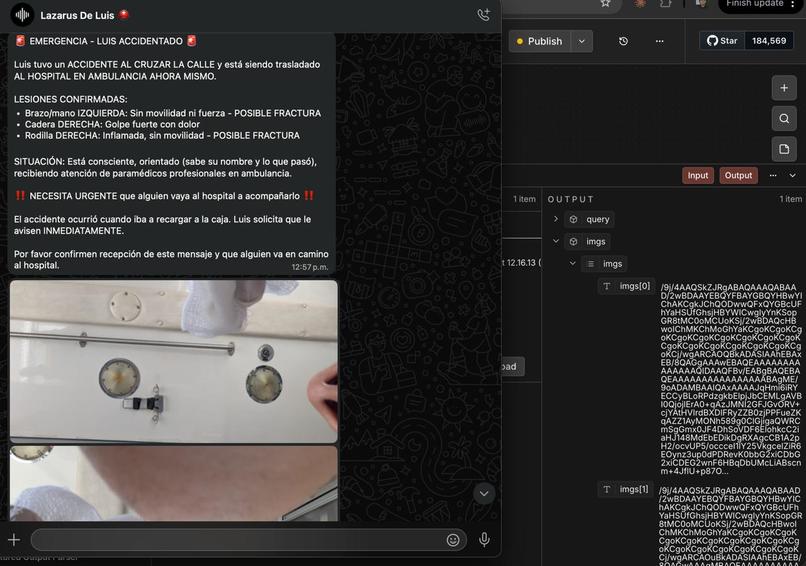
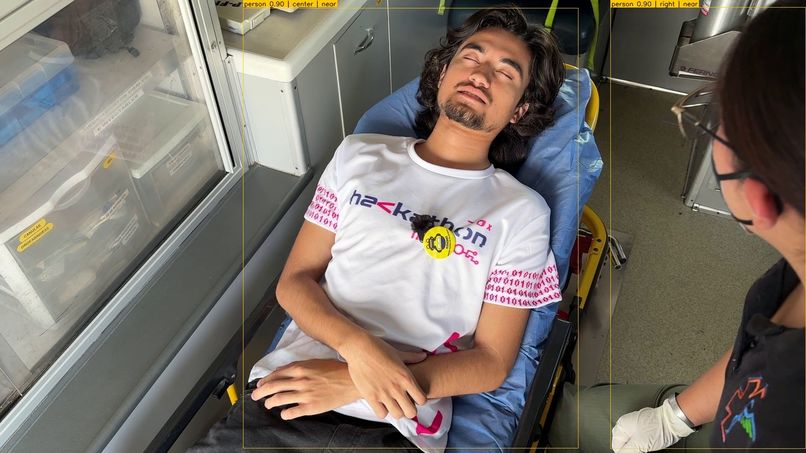
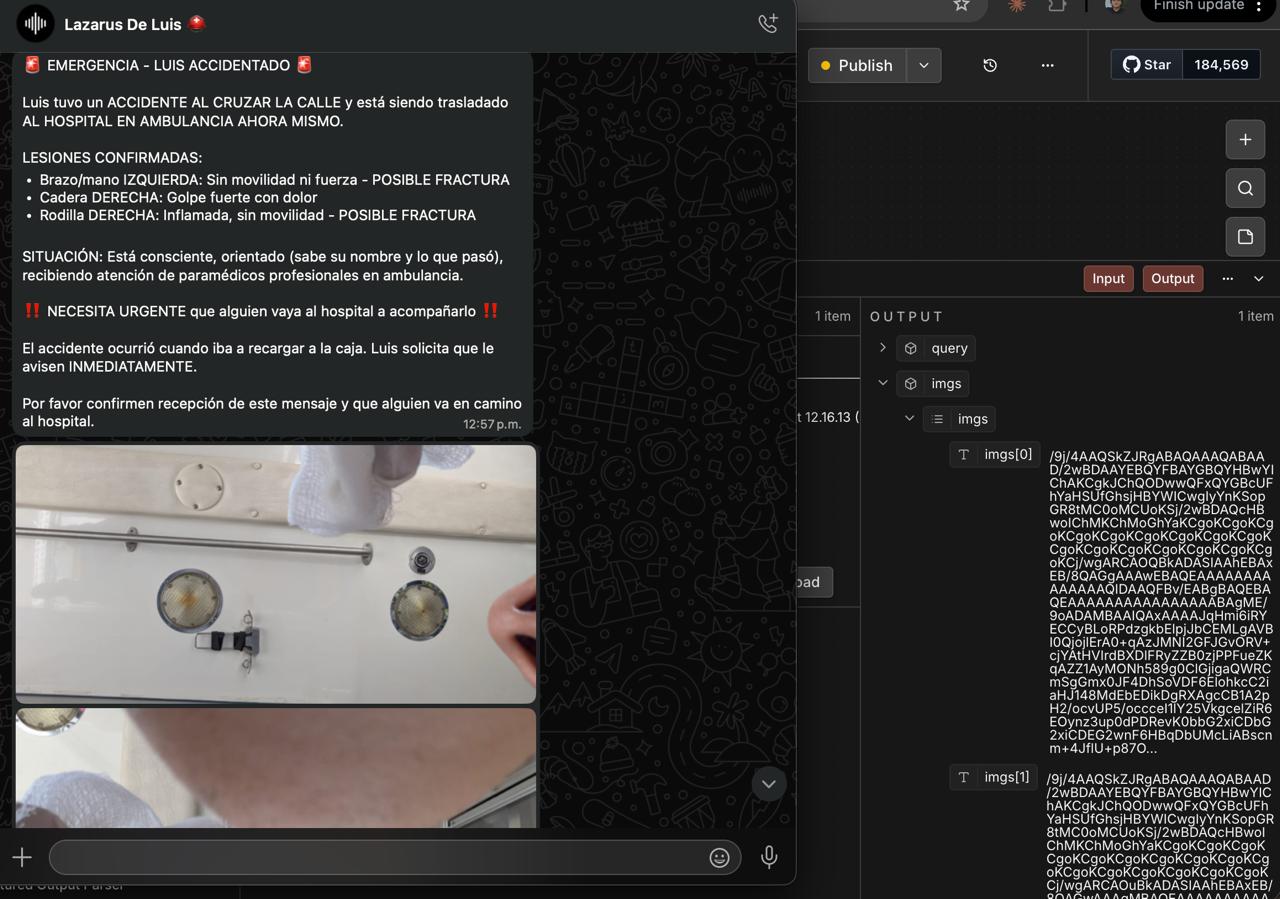
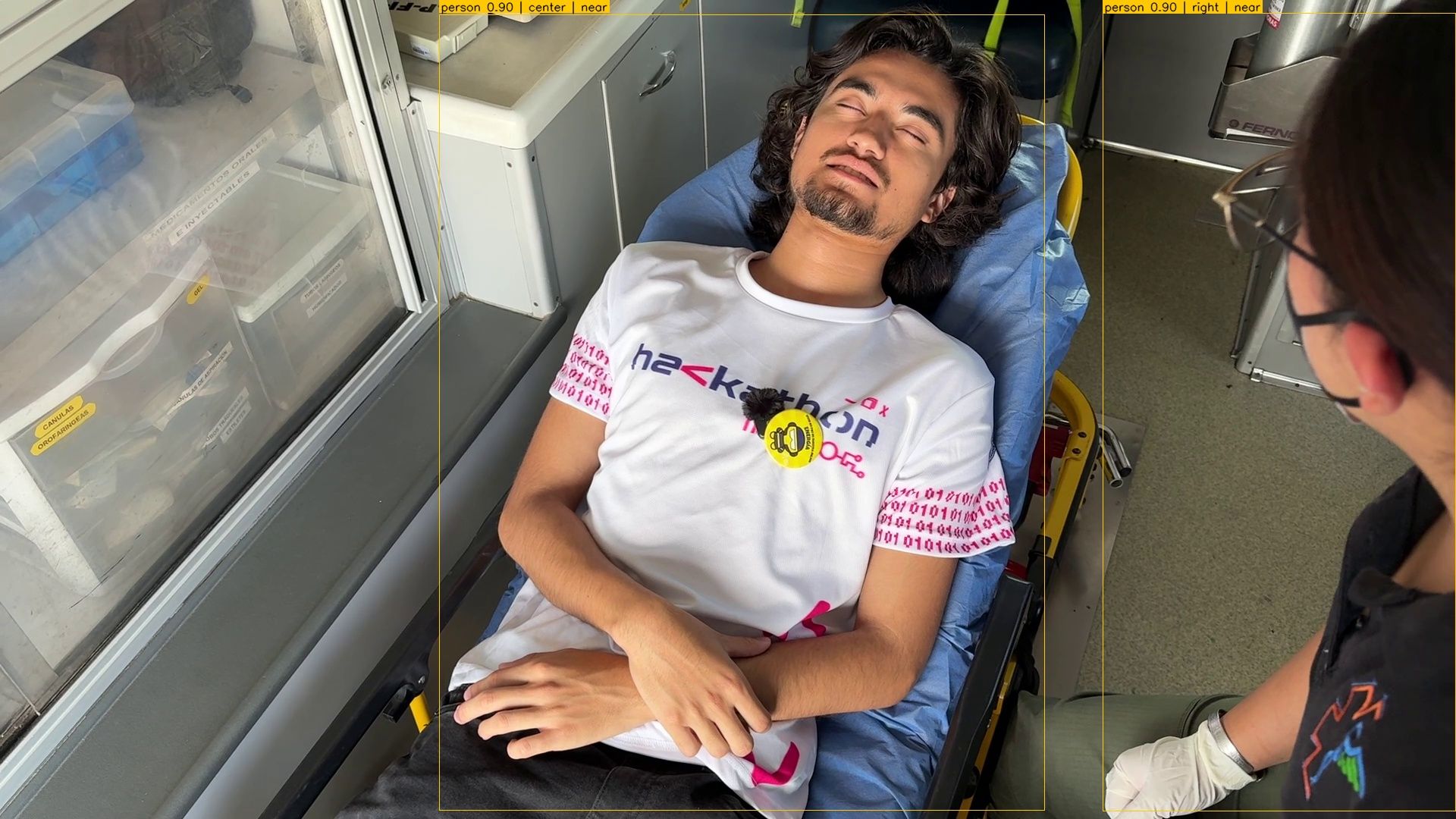
Emergencia — la IMU del wearable Lazarillo detecta impactos físicos. YOLOv8n-pose confirma la caída analizando keypoints corporales en el tiempo. El sistema avisa al usuario y espera diez segundos. Sin respuesta: Gemini genera el resumen del incidente, ElevenLabs lo convierte a audio, y Twilio llama al contacto de emergencia reproduciéndolo junto con la ubicación del usuario. Automáticamente. Sin que el usuario haga nada.
Cómo lo construimos
El binomio Lazarillo–Lázaro
Lazarillo (wearable) — Raspberry Pi Zero W con módulo de cámara e IMU (acelerómetro/giroscopio). Transmite video MJPEG por WiFi a 640×480 ~10 FPS y detecta impactos físicos. No procesa nada localmente — es deliberadamente simple para ser ligero y de bajo consumo.
Lázaro (cerebro) — Orange Pi 5 Max, Rockchip RK3588, 16GB RAM, NPU de 6 TOPS. Aquí vive toda la inteligencia. Los auriculares Bluetooth son la única interfaz con el usuario: micrófono de entrada, parlante de salida. Sin pantallas. Sin botones. Sin fricción.
YOLOv8n-pose en la NPU
El componente más técnico fue hacer correr YOLOv8n-pose directamente en la NPU del RK3588. Los modelos no pueden ejecutarse nativamente — requieren compilación anticipada en tres etapas:
$$\text{PyTorch} \xrightarrow{\text{ultralytics export}} \text{ONNX (12MB)} \xrightarrow{\text{rknn-toolkit2}} \text{RKNN INT8 (8MB)} \xrightarrow{\text{rknnlite}} \text{NPU}$$
La cuantización INT8 comprime los pesos del modelo:
$$W_{int8} = \text{round}\left(\frac{1}{S} \cdot W_{float32} + Z\right)$$
Resultado: inferencia a ~30ms por frame (33 FPS) consumiendo 5–12W, frente a ~205ms (5 FPS) en CPU. Esa diferencia es la que separa un sistema usable de uno que no lo es. Una cadena de fallback garantiza que el sistema siempre funciona:
try:
return RKNNDetector(model_path) # NPU: 30ms
except RuntimeError:
return ONNXDetector(onnx_path) # CPU: 205ms
# → MockDetector si tampoco hay ONNX
El Alert Engine
Una detección de YOLO cada 30ms sin filtrado generaría un flujo de alertas de voz ininteligible. El Alert Engine implementa cooldowns independientes por clase usando timestamps monotónicos:
$$\text{alertar}(c) = \begin{cases} \text{True} & \text{si } t_{\text{now}} - t_{\text{last}}(c) > \tau_c \text{ y } p > p_{\min} \ \text{False} & \text{en otro caso} \end{cases}$$
Donde $\tau_c$ varía por clase: semáforos $\tau=3\text{s}$, vehículos $\tau=5\text{s}$, personas $\tau=8\text{s}$. Cada detección incluye metadata espacial — zona (izquierda/centro/derecha) y proximidad estimada:
$$\text{proximidad} = \frac{(x_2-x_1)(y_2-y_1)}{W \cdot H}$$
Detección de caídas
YOLOv8n-pose extrae 17 keypoints corporales por persona. Una caída se confirma cuando el ratio de postura $r$ cae por debajo del umbral crítico durante al menos 3 segundos consecutivos:
$$r = \frac{|y_{\text{hombros}} - y_{\text{caderas}}|}{h_{\text{bbox}}} < 0.25$$
Versión cloud/PC
Para usuarios sin hardware edge, la versión PC conecta cualquier webcam USB con activación por voz, hotkey y detección automática YOLO, delegando el razonamiento visual a Gemini Vision a través de n8n — el orquestador de flujos que conecta webhooks, Gemini y ElevenLabs sin código de backend adicional.
Desafíos que enfrentamos
El hardware pelea de vuelta. Un apt upgrade de rutina corrompió
el bootloader y dejó la Orange Pi sin arranque. La recuperamos via
modo Maskrom — el protocolo de recuperación de hardware de Rockchip
que bypasea el sistema operativo completo. Dos veces. Bajo presión de
hackathon. Ahora sabemos más de U-Boot de lo que jamás planeamos saber.
# Lo que deberíamos haber hecho desde el inicio
Investigar mas al hadware porque, no solo es potencia es documentacion.
sudo apt-mark hold linux-image-$(uname -r)
sudo apt-mark hold u-boot-menu
La NPU tiene sus propias reglas. onnxruntime-gpu no existe en
ARM. numpy >= 2.0 rompe rknn-toolkit2 en conversión pero funciona
en runtime. YOLOv9 usa operadores de atención que caen a CPU en RKNN,
eliminando todo beneficio de la NPU. Nada de esto está documentado
en un solo lugar.
Audio Bluetooth en Linux es frágil. BlueZ con PipeWire requiere forzar el perfil HFP para habilitar micrófono activo simultáneo con salida de audio. A2DP da mejor calidad pero es solo salida. Esta configuración poco documentada nos costó tiempo significativo.
Diseñar sin interfaz visual cambia todo. No hay UI. Cada decisión — cuándo hablar, qué tan largo es el mensaje, cuándo interrumpir, cuándo quedarse callado — tuvo que pensarse desde la perspectiva de alguien que solo tiene audio. El silencio selectivo resultó ser tan difícil de diseñar como la detección misma.
La realidad urbana mexicana vs. los datasets internacionales. COCO no conoce los semáforos no estándar, los puestos ambulantes ni los obstáculos específicos de las banquetas de Querétaro. Adaptar la detección a nuestro contexto real fue un problema de datos tanto como de modelo.
Logros de los que estamos orgullosos
33 FPS en una placa de $110 dólares. Lograr que YOLOv8n-pose corra a 33 FPS en una NPU de 6 TOPS requirió entender el pipeline completo de conversión RKNN, la calibración de cuantización INT8 y las limitaciones de operadores del RK3588. Funciona. Y funciona bien.
Latencia de alerta menor a 300ms con cache. Las alertas comunes llegan al oído del usuario en ~270ms desde la detección. Esa es la diferencia entre avisarle antes o después de que pise el escalón.
178 tests unitarios sin hardware. Toda la lógica de negocio — detección, alert engine, detección de caídas, orquestación, pipeline de emergencia — fue desarrollada y validada en Mac usando MockDetector, mock streams MJPEG y mocks de sounddevice. El sistema era correcto antes de correr en la Orange Pi por primera vez.
Un sistema que funciona para todos. Dos configuraciones, una misión. Ya sea que tengas una Orange Pi y una Raspberry Pi o solo una laptop y una webcam, Lázaro funciona para ti. Ese no fue un logro técnico. Fue un logro ético.
Respuesta de emergencia automática. Un sistema que detecta una caída, la confirma, espera la respuesta del usuario, genera un resumen en lenguaje natural y llama a un número de teléfono real reproduciendo ese resumen con una ubicación — completamente automático — no es una feature de demo. Es algo que podría salvar una vida.
Lo que aprendimos
La latencia percibida importa más que la latencia real. Un sistema que tarda 600ms pero dice lo correcto en el momento correcto se siente más rápido que uno que tarda 100ms pero genera ruido. El Alert Engine con cooldowns fue tan importante como la optimización de la NPU.
La verdadera inteligencia reside en el silencio selectivo. La fatiga auditiva es un riesgo real. Un sistema que habla demasiado es tan inútil como uno que no habla. Decidir cuándo un evento no merece una interrupción fue el problema de diseño más difícil del proyecto.
Los tests de hardware son distintos a los de software. Los tests unitarios pasan sin NPU, sin cámara, sin micrófono. La disciplina de escribir código testeable y mockeable antes de tocar el hardware hizo la fase de integración dramáticamente más rápida.
La accesibilidad no admite fragmentación de hardware. Diseñar solo para la Orange Pi hubiera limitado quién se beneficia de este proyecto. La decisión de construir una segunda configuración para PC no fue una decisión de ingeniería. Fue una decisión de inclusión.
Qué sigue para Lázaro
OCR en escena. Leer letreros, menús, etiquetas de medicamentos, números de camión — cualquier texto en la escena — integrado directamente al modo reactivo.
App para cuidadores. Interfaz móvil para familiares que permite consultar los reportes de MongoDB con visualización de keyframes, historial de incidentes y recordatorios de medicamentos extraídos de las grabaciones de consultas médicas.
LLM offline. Reemplazar Gemini con un modelo local cuantizado (Qwen2.5-0.5B o similar) para el modo reactivo, haciendo el sistema completamente independiente de conectividad para su funcionalidad base.
Detección fine-tuned para el contexto urbano mexicano. Un dataset propio de semáforos mexicanos, obstáculos en banquetas, transporte público y puestos ambulantes para reemplazar las clases de COCO con algo que refleje realmente dónde viven nuestros usuarios.
Exportación a braille. Integración directa con servicios de impresión braille para los reportes del modo memoria — para que el resumen de una consulta médica pueda imprimirse y guardarse, no solo escucharse una vez.
Lázaro no es solo un dispositivo. Es nuestra respuesta técnica a un problema de derechos humanos. La transición de la asistencia reactiva a la autonomía proactiva. La diferencia entre depender de alguien y confiar en algo que siempre está ahí, siempre viendo, siempre listo — para que tú no tengas que estarlo.
Built With
- agent
- arch
- asyncio
- docker
- edge-computing
- elevenlabs
- fastapi
- gcp
- gemini
- linux
- mongodb
- n8n
- orange-pi
- predictive-edge
- python
- raspberry-pi
- rknn/onnx
- stt
- tts
- twilio
- vision
- whisper
- yolov8n

Log in or sign up for Devpost to join the conversation.