-
Sample dashboard
Inspiration
Ever wondered what the fastest song of the Beatles is? Or tried to find all Porcupine Tree songs with guitar solos greater than 3 minutes? Or the Radiohead song with the most number of happy words (if that's even possible)? Being a music junkie, i often find myself looking for these in a wide variety of places.
I could not find a project (research or otherwise) which has tried to analyze the lyrics of Indian film songs using common data analysis techniques.
What it does
Pulls all metadata and audio features of all songs of an artist from Spotify using their APIs. Looks up the lyrics on Musixmatch and puts all of this into a single object which is then indexed. This can then be searched, aggregated and plotted to our hearts content.
Crawled ~1800 Hindi songs (metadata + lyrics) from http://geetmanjusha.com/ and analyzed them similarly. Because most data analysis tools/algorithms are primarily geared towards english data, I added a translation layer using the Google Translation APIs.
Search using a restricted natural query language Eg: 1. "Bon Iver songs about loneliness" 2. "fastest Beatles song in the key of E" 3. "Hindi songs after 1980 about cars"
Use NLTK for semantic searching Eg: "Beatles songs about love" should return hits for lyrics containing "affection"
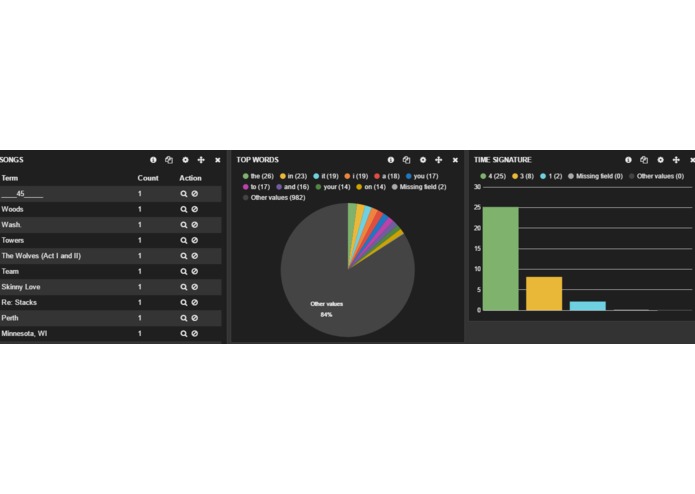
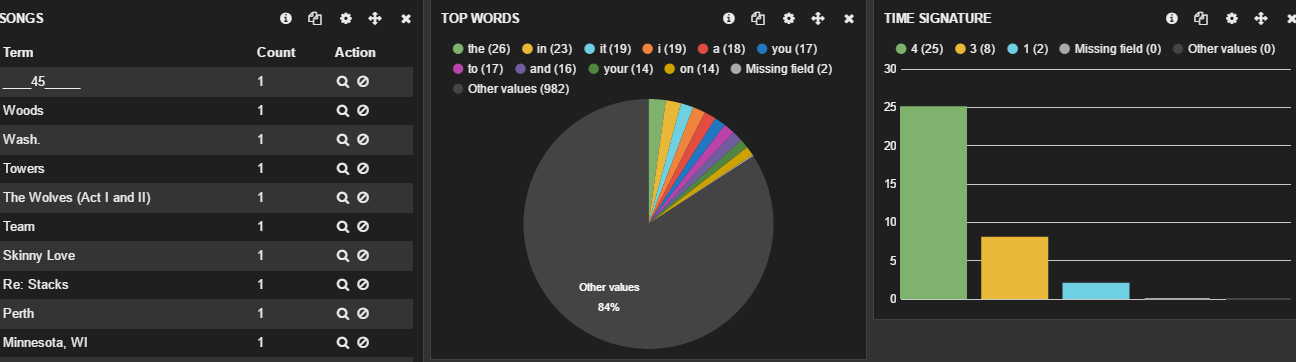
Plot all of the analyzed data in a neat dashboard. This dashboard can then be furthered queried and filtered by simple clicks. Eg: If i want to find all Bon Iver songs with the time signature 3/8, i just click on 3 in the "Time Signature" panel and every other panel (lyrics, songs etc.) are filtered for this query. (Image 1)
How I built it
- Core indexing is performed by elasticsearch and plotting by kibana
- Crawlers and API clients are written in python
- Server is in Django
- Typeahead for autocomplete
Challenges I ran into
- Tuning the crawlers to work with all the peculiarities of the input datasets
- Reading through obtuse API documentation (Can it be anything else:))
- Setting up all the different pieces of the infrastructure (My AWS instance has only 1GB RAM, so i had to launch elasticsearch elsewhere and spent quite a while getting all the pieces to talk to each other sanely)
Accomplishments that I'm proud of
- Solved a personal need (there will always be one user:))
- Probably stumbled upon an interesting research topic that isn't actively being worked on (data analysis of Indian film content and songs)
- Built an extensible platform that interested people can use to extract data. Elasticsearch has easily accessible APIs to get all of the indexed data. For example, an anthropology student studying Indian political outreach via films can extract data from my system easily.
What I learned
- Sometimes, it's ok to build things just for yourself. Not for a million people.
What's next for Lazarus
- Iron out all the rough edges (crawlers are a bit hard-coded)
- Add more Indic languages
Built With
- bootstrap
- django
- elasticsearch
- google-translate-api
- javascript
- jquery
- kibana
- musixmatch
- python
- spotify
- typeahead

Log in or sign up for Devpost to join the conversation.