Inspiration
World Product Day's theme is "Everyone Ships Now." But when you ship every week with an AI builder and have no data team, you ship blind: did the change you just merged help the flow that matters, or did it quietly break it? Today the honest answer is a 40-widget analytics dashboard you'll never open, or a gut feeling. Every PM judge — and every maker here — knows that pain in the first person: "I shipped three things this week. Which one is silently costing me users?"
What it does
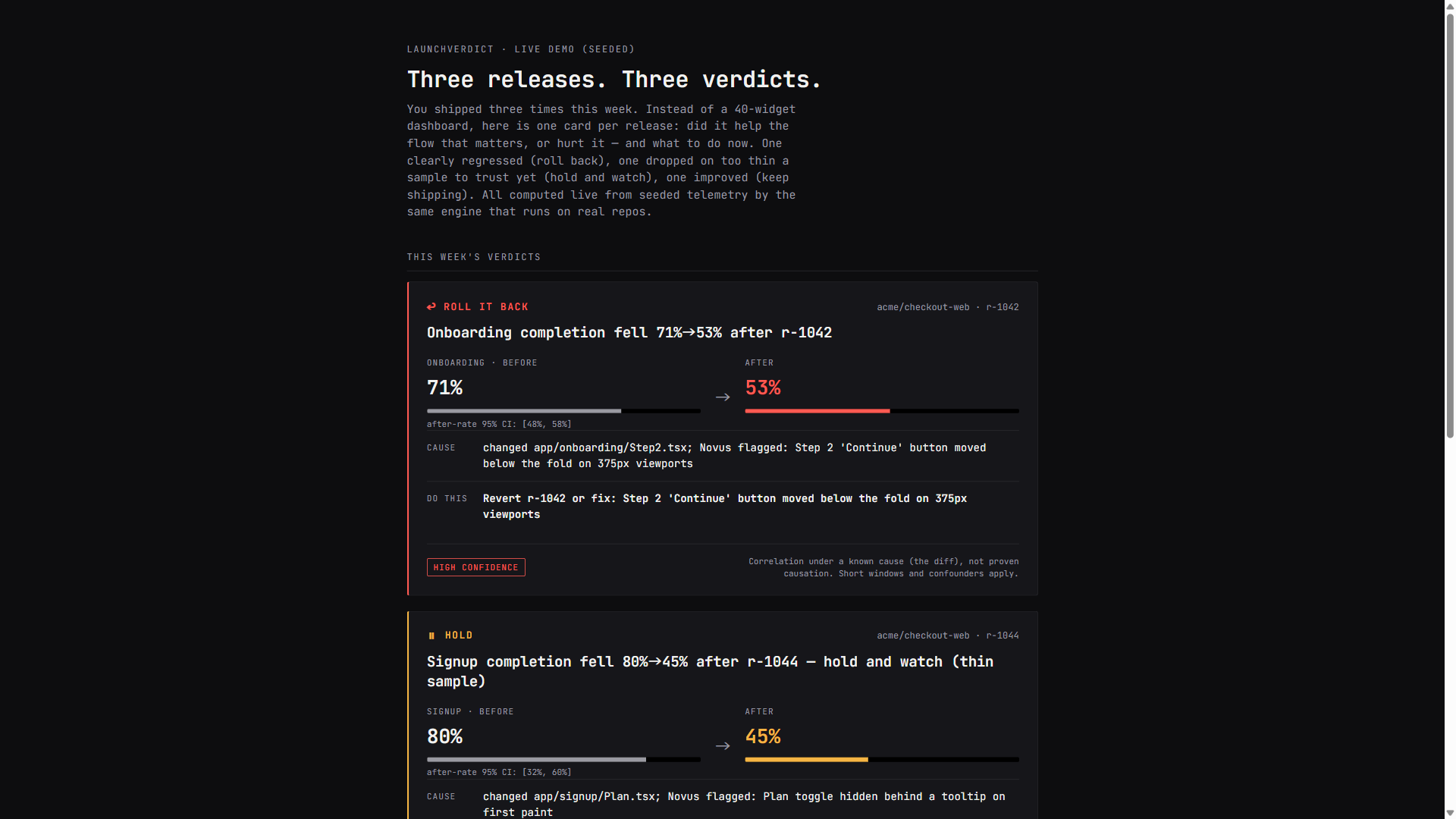
A release is the changepoint on your event timeline — the cut we split before/after on. After each release, LaunchVerdict hands you one card:
- the flow that moved the most (e.g. Onboarding completion fell 71% → 53%),
- the likely cause — the diff you shipped, plus any UX regression Novus flagged on that PR,
- the one thing to do now — keep shipping / hold and watch / roll it back,
- a confidence label and a 95% CI, because a short-window comparison is a correlation under a known cause, not a proof — and the card says so.
Four verdict states, decided deterministically by a rule over the stats — never by the LLM:
- KEEP SHIPPING — significant improvement.
- ROLL IT BACK — significant, meaningful drop, with enough sample to trust.
- HOLD — a real drop but on too thin a sample to revert on yet (hold and watch).
- INSUFFICIENT — not enough data to call.
See all three live in 60 seconds, no login: https://launchverdict.vercel.app/demo
How Novus closes the loop (not a checkbox)
LaunchVerdict and Novus form a closed release-confidence loop — Novus is the cause half, not a logo:
- Novus by Pendo reviews the diff before you merge — it scans the codebase and flags UX regressions on the PR (the cause).
- LaunchVerdict renders the verdict after it ships — it measures the flow that moved (the effect).
When connected to a repo, LaunchVerdict reads Novus's flags from the merged PR's review comments and surfaces the matching flag as the cause line on the verdict card — so the pre-merge warning and the post-ship outcome sit on one artifact. In the public /demo that flag is a seeded fixture string standing in for the comment. We dogfood the loop by installing Novus by Pendo on LaunchVerdict's own GitHub repo — and you can verify it live: Novus is connected as the GitHub App app/novus-by-pendo and has opened its instrumentation PRs on our repo, #1 Install Novus and #2 Instrument Pendo Track Events. The attached Novus dashboard screenshot is that same install actively mapping the product.
How we built it
- Next.js 15 (App Router) on Vercel, React 19, TypeScript.
- A deterministic statistics engine: two-proportion z-test (pooled SE), Wilson score interval, an inlined normal CDF (Abramowitz–Stegun erf) — no stats dependency, fully unit-tested. It reproduces a fixed reference case (z = −5.46, p ≈ 4.6e-8 → ROLLBACK) on every run.
- GitHub for the cut (commit/PR/diff/CI + Novus's PR comments) via webhook; Postgres for telemetry; a thin telemetry snippet (
lv.js) to self-measure before/after on the flows you care about. - An LLM prose layer (schema-forced via tool_choice) that only polishes the headline/cause/action wording — it can never change the call, the numbers, or the confidence. The honesty guard is structural, not a prompt instruction.
- Built with Claude (Claude Code) as the AI builder.
What we learned
- The hard part of "release confidence" isn't the stats — it's refusing to over-claim. The most design effort went into making the product honest: confidence labels, "correlation under a known cause, not causation," and a HOLD state so a thin-sample drop is never mis-sold as a confident rollback.
- The strongest use of Novus wasn't to pull its raw analytics (the free beta doesn't expose a read-back API in time) — it was to promote Novus's pre-merge signal into a decision UI: the cause line on the card. The loop is the product.
Target user
The solo maker / small team who ships every week with an AI builder and has no data team — exactly the "Everyone Ships Now" audience. One avoided bad rollback pays for it.
What's verified vs. wireable (honest scope)
The deterministic engine and the seeded /demo are test-covered and run with no accounts (the live demo is real output from the same engine). The live wiring (GitHub webhook → cut assembly → PR comment + commit status, Postgres telemetry, optional LLM polish) is implemented and typechecks/builds — not stubbed — but /demo data is seeded and the live external paths come online only once a repo + Postgres + token + Novus are connected. The verdict call and numbers never depend on any of that: they come from the tested engine.
Built With
- anthropic-claude
- github-api
- next.js
- novus
- pendo
- postgresql
- react
- typescript
- vercel

Log in or sign up for Devpost to join the conversation.